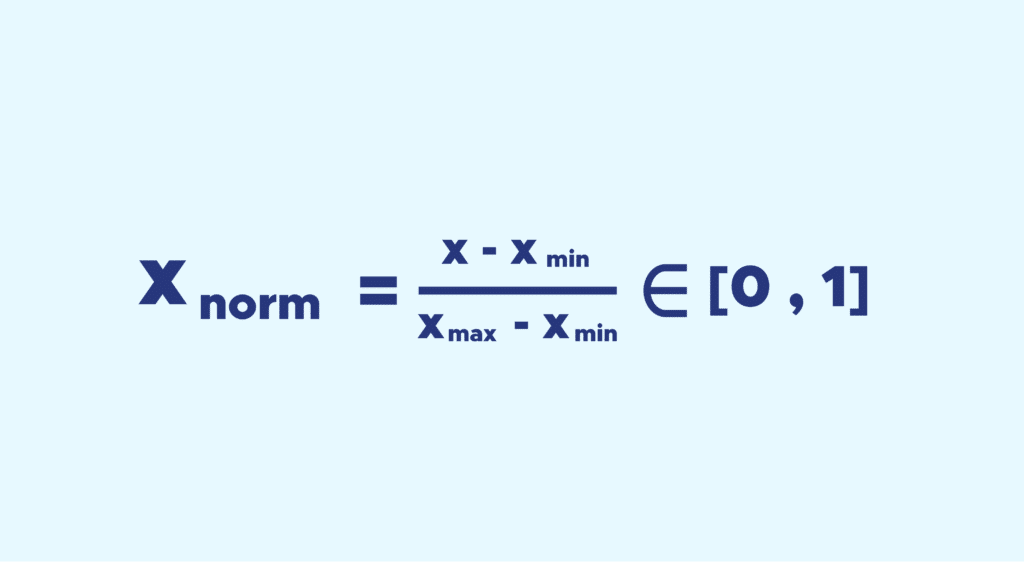
Daniel ist unser technischer Support für die Weiterbildungen bei DataScientest. Er ist der Experte, der sich mit allen Themen der Data Science auskennt und die Lernenden durch ihre Weiterbildungen begleitet. Heute haben wir es geschafft, ein paar Minuten seiner kostbaren Zeit zu nehmen, damit er unsere Fragen rund um die Datenstandardisierung beantworten kann.
Ich: Hallo Daniel! Ich weiß, dass wir Dir diese Frage schon oft gestellt haben, aber ich höre ständig von der „Datennormalisierung”. Kannst Du mir helfen, das Konzept in wenigen Worten zu verstehen?
Daniel: Tatsächlich ist die Datennormalisierung im Bereich Data Science ein zentrales Konzept der Datenvorverarbeitung, wenn man an einem Machine-Learning-Projekt arbeiten muss.
Mit dem Wort „Normalisierung” sind eigentlich zwei Hauptverfahren gemeint: Normalisierung und Standardisierung. Im Großen und Ganzen haben beide Verfahren denselben Zweck: numerische Variablen so zu skalieren, dass sie auf einer gemeinsamen Skala vergleichbar sind.
Wie sieht das mathematisch aus?
Betrachten wir eine numerische Variable mit n Beobachtungen, die so geschrieben werden kann:
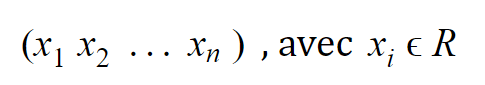
Da wir eine endliche Anzahl von realen Werten haben, können wir verschiedene statistische Informationen extrahieren, darunter: Min, Max, Mittelwert und Standardabweichung. Für ein Normalisierungsverfahren brauchen wir nur Min und Max.
Die Idee dahinter ist, dass wir alle Werte der Variablen zwischen 0 und 1 reduzieren, während wir die Abstände zwischen den Werten beibehalten.
Die Formel lautet einfach wie folgt:
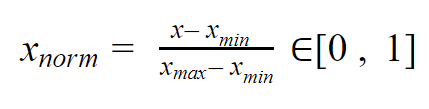
Bei der Standardisierung ist die Umwandlung feiner als einfach alle Werte zwischen 0 und 1 zu bringen: Der Mittelwert μ wird auf 0 gebracht, die Standardabweichung σ auf 1.
Auch hier ist es einfach. Wenn man den Mittelwert μ und die Standardabweichung σ einer gegebenen Variable X = x1 x2 xn zur Verfügung hat, wird die standardisierte Variable so geschrieben:

Das ist alles toll, aber wozu braucht man Datennormalisierung ?
In der Datenverarbeitung arbeiten wir sehr oft mit numerischen Daten, und diese Daten sind selten in ihrem Rohzustand vergleichbar.
Die Arbeit mit unterschiedlich skalierten Daten kann bei der Analyse ein Problem sein, da eine numerische Variable mit einem Wertebereich von 0 bis 10.000 in der Analyse stärker ins Gewicht fällt als eine Variable mit Werten zwischen 0 und 1, was später zu Verzerrungen führen würde.
Achtung! Bei der Verarbeitung unserer Daten ist die Normalisierung kein obligatorischer Schritt, da sie einen unmittelbaren Informationsverlust verursacht und in manchen Fällen von Nachteil sein kann!
Jetzt ist es klarer, aber eine Frage bleibt offen: Wie normalisiert man konkret Daten?
Mit Python ist das sehr einfach: Es gibt viele Bibliotheken, die dies ermöglichen. Ich werde nur Scikit-learn erwähnen, da es die am häufigsten verwendete Bibliothek in Data Science ist. Diese Bibliothek bietet Funktionen, die die gewünschten Normalisierungen in wenigen, sehr einfachen Codezeilen durchführen.
Dennoch ist es wichtig, die Anwendungsfälle in einen Kontext zu stellen. Denn in der Praxis reicht es nicht aus, eine einfache Normalisierung auf alle unsere Daten anzuwenden, wenn wir unsere Trainingsdaten bereits normalisiert haben.
Warum ist das so? Aus dem einfachen Grund, dass es nicht möglich ist, dieselbe Transformation auf eine Stichprobe oder auf neue Daten anzuwenden.
Es ist natürlich möglich, jede beliebige Stichprobe auf die gleiche Weise zu zentrieren und zu reduzieren, aber mit einem Mittelwert und einer Standardabweichung, die sich von denen unterscheiden, die für den Trainingssatz verwendet werden.
Die Ergebnisse wären dann keine angemessene Darstellung der Leistung des Modells als Ganzes, wenn es auf neue Daten angewendet wird.
Anstatt also die Normalisierungsfunktion direkt anzuwenden, ist es besser, eine Funktion von Scikit-Learn namens API Transformer zu verwenden, die es Dir ermöglicht, einen Preprocessing-Schritt unter Verwendung der Trainingsdaten anzupassen (engl. fit).
Wenn also beispielsweise die Normalisierung auf andere Stichproben angewendet wird, werden die gleichen gespeicherten Mittelwerte und Standardabweichungen verwendet.
Um diesen „angepassten” Preprocessing-Schritt zu erstellen, verwende einfach die Funktion StandardScaler und passe sie dann mit den Trainingsdaten an. Um sie später auf eine Datentabelle anzuwenden, musst Du nur scaler.transform() anwenden.
Genauso funktioniert es für eine Min-Max Normalisierung.
Super, danke Daniel!
Auch interessant:
Wenn wir uns in Data Science weiterbilden und Deine Tipps anwenden wollen, wie machen wir das?
Ganz einfach: Du kannst in Kürze einen unserer Data Science-Kurse belegen  .
.







