In diesem Artikel stellen wir dir einen der Stolpersteine von überwachten Lernalgorithmen vor, das Überlernen oder Overfitting auf Englisch.
Was ist Overfitting?
Overfitting ist das Risiko, dass ein Modell die Trainingsdaten „auswendig“ lernt. Auf diese Weise riskiert es, dass es nicht in der Lage ist, auf unbekannte Daten zu verallgemeinern.
Ein Modell, das z. B. das Label für die Trainingsdaten und eine Zufallsvariable für unbekannte Daten zurückgibt, würde während des Trainings sehr gut abschneiden, aber nicht für neue Daten.
Wann besteht die Gefahr, dass Overfitting auftritt?
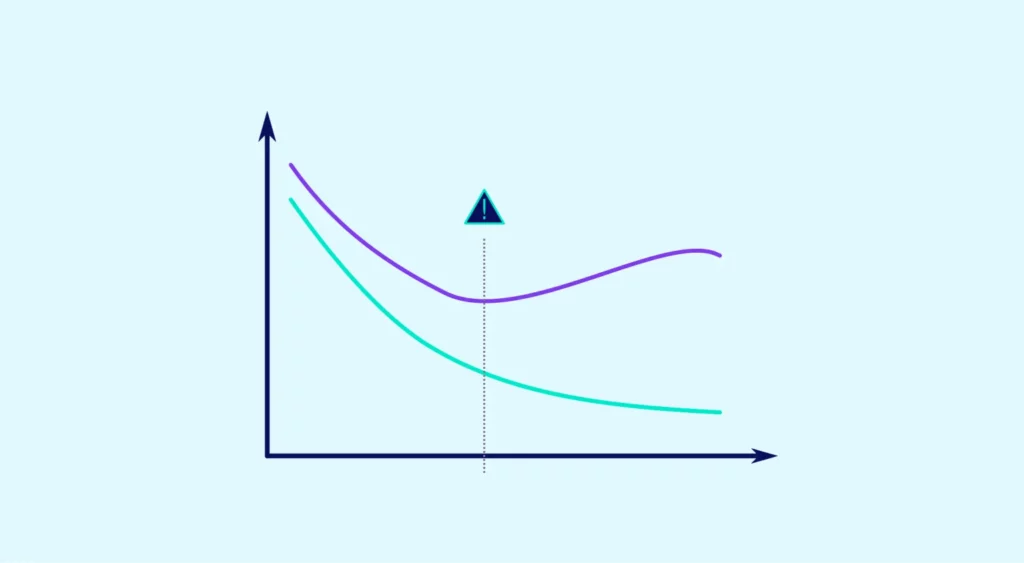
Overfitting kann auftreten, wenn das gewählte Modell im Verhältnis zur Größe des Datensatzes zu komplex ist.
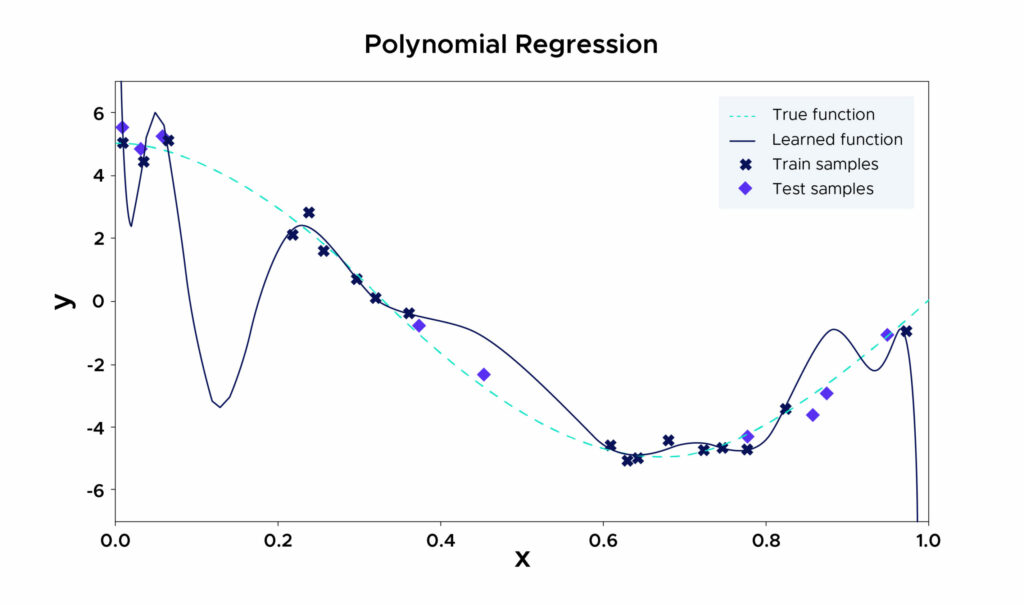
Zum Beispiel ist das hier gewählte Modell eine polynomiale Regression, die sich selbst zwingt, so viele Punkte wie möglich in den Trainingsdaten zu durchlaufen, weil der gewählte Grad zu groß ist.
Dadurch lässt es viele Punkte aus, die während des Trainings nicht gesehen wurden. Bei Trainingsdaten schneidet dieses Modell sehr gut ab, aber bei ungesehenen Daten kann der quadratische Fehler enorm sein.
Warum ist Overfitting ein Problem?
Aufgrund von Overfitting repräsentiert ein Modell die Daten, mit denen es trainiert wurde, nur unzureichend.
Daher ist seine Genauigkeit bei neuen, ähnlichen Daten geringer als bei einem ideal angepassten Modell. Wenn man es jedoch auf die Trainingsdaten anwendet, scheint das überfitte Modell eine höhere Genauigkeit zu bieten. Es ist daher sehr leicht, sich in die Irre führen zu lassen.
Ohne Overfitting-Schutz können Entwickler ein Modell trainieren und einsetzen, das auf den ersten Blick hochgenau ist. In Wirklichkeit wird dieses Modell in der Produktion mit neuen Daten eine schlechtere Leistung erbringen.
Der Einsatz eines solchen Modells kann alle möglichen Probleme verursachen. Beispielsweise kann ein Modell, das zur Vorhersage der Wahrscheinlichkeit eines Zahlungsausfalls verwendet wird, im Falle eines Overfittings einen viel höheren Prozentsatz als die Realität anzeigen. Dies kann zu falschen Entscheidungen führen, was wiederum zu Umsatzeinbußen und unzufriedenen Kunden führt.
Overfitting vs Underfitting
Im Gegensatz zum Overfitting tritt das Underfitting auf, wenn die Trainingsdaten stark verzerrt sind. Wenn z. B. ein Problem übermäßig vereinfacht wird, funktioniert das Modell auf den Trainingsdaten nicht richtig.
Dies kann durch Daten verursacht werden, die Rauschen oder falsche Werte enthalten. Das Modell wird daher nicht in der Lage sein, Muster aus dem Datensatz herauszufiltern.
Eine weitere Ursache kann ein stark verzerrtes Modell sein, weil es nicht in der Lage ist, die Beziehung zwischen den Trainingsbeispielen und den Zielwerten zu erfassen. Der dritte Grund kann ein zu einfaches Modell sein, wie z. B. ein lineares Modell, das mit komplexen Szenarien trainiert wird.
Beim Versuch, Overfitting zu vermeiden, besteht die Gefahr, Underfitting zu verursachen. Dies kann geschehen, indem man den Trainingsprozess früher abbricht oder seine Komplexität durch das Entfernen der weniger relevanten Eingaben reduziert.
Wenn das Training zu früh abgebrochen wird oder wichtige Merkmale entfernt werden, kann Underfitting auftreten. In beiden Fällen wird das Modell nicht in der Lage sein, Trends innerhalb des Datasets zu erkennen.
Daher ist es entscheidend, die ideale Anpassung zu finden, damit das Modell die Muster in den Trainingsdaten erkennt, ohne sich zu genaue Details zu merken. Das ist es, was das Modell in die Lage versetzt, zu verallgemeinern und andere Datenproben genau vorherzusagen.
Wie vermeidet man Overfitting ?
Um Overfitting zu vermeiden, muss das Modell daher jedes Mal neu bewertet werden, und zwar anhand von Daten, die während des Trainings nicht gesehen wurden.
Eine gute Praxis ist es, den anfänglichen Datensatz in einen Trainingssatz (train set) und einen Testsatz (test set) aufzuteilen. Der erste Satz wird dazu verwendet, das Modell zu trainieren. Der Testsatz, der aus ungesehenen Daten besteht, dient dazu, zu testen, wie das Modell generalisiert wird.
Die Leistung des Modells kann nur anhand der Leistung des Testsatzes beurteilt werden, nicht anhand der Leistung des Trainingssatzes, der möglicherweise auswendig gelernt wird.
Wie wählt man Trainings- und Testdaten aus?
Die einfachste und am häufigsten verwendete Methode ist es, die Daten nach dem Zufallsprinzip zu trennen. Das Python-Modul sklearn.model_selection bietet zu diesem Zweck die Funktion train_test_split. Durch die Übergabe eines Datensatzes an diese Funktion wird eine Partition des Datensatzes erstellt, wodurch der Testsatz und der Trainingssatz erhalten werden.
Diese Trennung erfolgt jedoch zufällig. Es besteht also die Gefahr, dass zufällig nicht repräsentative Datensätze erzeugt werden.
Um zu vermeiden, dass ein Modell auf nicht repräsentativen Daten validiert wird, besteht eine Methode darin, den Trainingsvorgang mit einem Satz zu wiederholen, dann mit einem anderen Satz mehrmals zu testen und die Ergebnisse zu mitteln.
Dadurch werden die zufälligen Effekte gemittelt und man erhält eine Schätzung der Leistung auf zufällig ausgewählten ungesehenen Daten.
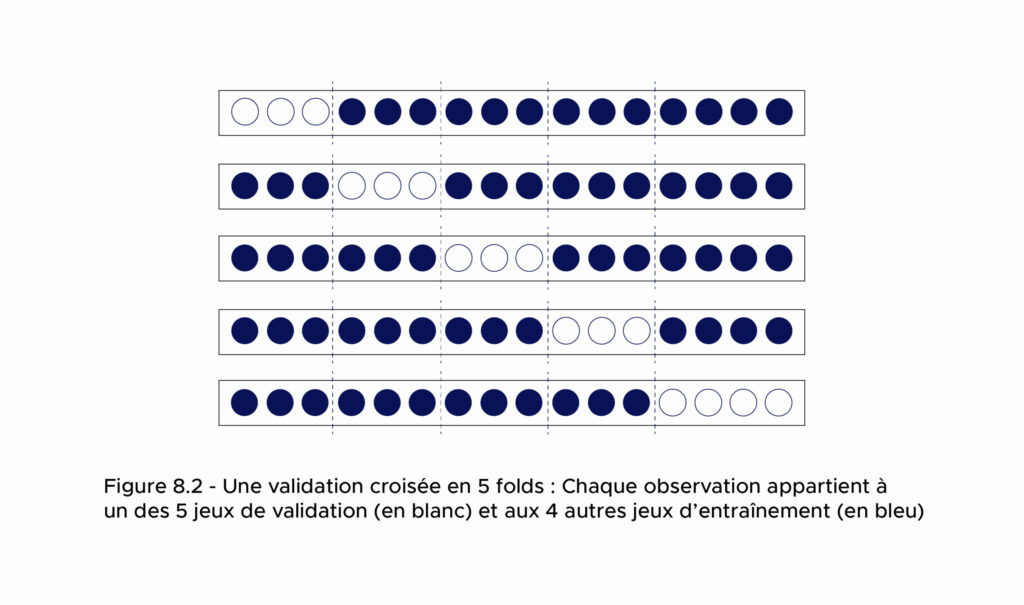
Diese Modellvalidierung nennt man Kreuzvalidierung oder englisch cross validation.
Eine Kreuzvalidierung besteht aus mehreren Folds. Jeder Fold ist eine Partition des Datensatzes in zwei Sätze (Trainings- und Testsatz). Bei der Kreuzvalidierung wird das Modell für jeden Fold zunächst im Trainingssatz trainiert und dann im Testsatz bewertet.
Wir können dann die Leistung des Modells schätzen, indem wir die Leistung der Prädiktoren für jede Fold auf dem Testsatz für jede Fold bewerten und dann ihre Leistung mitteln.
Dieser Ansatz ermöglicht auch den Zugriff auf die Standardabweichung dieser Leistungen, was einen guten Eindruck von der Variabilität des Modells in Bezug auf den Trainingssatz vermittelt.
Wenn die Variabilität hoch ist, dann müssen wir bei der Wahl unseres Trainingssatzes umso vorsichtiger sein. Im Gegensatz dazu ist bei einer geringen Variabilität die Wahl des Trainingssatzes nicht sehr wichtig.
Was sind die Fehlerquellen eines Modells?
Bei einem Regressionsmodell ist das erste Bewertungskriterium der mittlere quadratische Fehler oder MSE für mean squared error.
Unser Datensatz D besteht aus n Realisierungen (xi, yi) eines Zufallsvektors mit der gleichen Gesetzmäßigkeit wie ein Paar Zufallsvariablen (X, Y), die durch die Beziehung Y = f(X) + eps verbunden sind, wobei eps eine Zufallsvariable mit dem Erwartungswert Null und der Varianz Sigma² ist, d.h. das Rauschen der Daten.
Wir können den mittleren quadratischen Fehler über D eines Schätzers als die Summe aus :
Aus dem Quadrat des Bias des Schätzers (der quantifiziert, wie weit die vorhergesagten Etiketten von der Realität entfernt sind).
Der Varianz des Schätzers (die quantifiziert, wie sich die Etiketten für ein und dieselbe Person in Abhängigkeit von den Eingabedaten ändern).
Der Varianz des Rauschens, auch irreduzibler Fehler genannt.
Daher kann ein verzerrter Schätzer mit einer geringen Varianz besser abschneiden als ein unverzerrter Schätzer mit einer großen Varianz.
In sehr vielen Fällen tritt Overfitting in den Fällen auf, in denen ein wenig verzerrter Schätzer mit hoher Varianz gewählt wird. Komplexe Modelle können diese Eigenschaften aufweisen, wie z. B. polynomiale Regressionen mit zu großer Ordnung (siehe Abbildung 1). Die Wahl einfacherer und auf den ersten Blick „schlechterer“, weil verzerrter Modelle kann daher zu einer besseren Leistung führen, wenn ihre Varianz gering ist!
Wenn du mehr über Overfitting und künstliche Intelligenz, die auf Bilder angewandt wird, erfahren möchtest :







