
Mit dem Aufkommen von NoSQL-Datenbanken macht Redis einen großen Sprung nach vorne, indem es eine speicherbasierte Datenverwaltung anbietet.
Redis wurde 2009 von Salvatore Sanfilippo gegründet und hat sich zu einer der beliebtesten NoSQL-Datenbanken entwickelt. Redis wurde in der jährlichen „Stackoverflow Developer Survey“ fünf Jahre in Folge zur beliebtesten Datenbank unter Entwicklern gewählt und wird derzeit von vielen Unternehmen wie Twitter, GitHub und Snapchat verwendet. Hier erfährst du alles, was du über diese schnell speicherbare Datenbank wissen musst.
Was ist Redis?
Redis (Remote Dictionary Server) ist ein in C geschriebenes Open-Source-Datenverwaltungssystem, das zum Speichern, Abrufen und Manipulieren verschiedener Datentypen entwickelt wurde. Es handelt sich um eine NoSQL-Datenbank vom Typ Schlüssel/Wertpaar. Redis kann so konfiguriert werden, dass es Daten auf der Festplatte speichert, wird jedoch hauptsächlich für die Verwaltung von Daten im Arbeitsspeicher verwendet, wodurch es viel schneller als herkömmliche Datenbanken ist. Mit seinen schnellen Antwortzeiten, die Millionen von Abfragen pro Sekunde für Echtzeitanwendungen ermöglichen, wird Redis in der Produktion in Branchen wie Videospiele, Werbung, Finanzdienstleistungen, Gesundheitswesen und IoT eingesetzt.
Wie funktioniert Redis?
Redis ist eine NoSQL-Datenbank, deren Verwaltungssystem auf einer Schlüssel-Wert-Struktur basiert, bei der jeder Wert mit einem eindeutigen Schlüssel verknüpft ist. Die Datenstrukturen von Redis unterstützen nativ verschiedene Arten von Werten wie Integers, Strings, Hashes, Lists, Sets, Sorted Sets, Bitmaps, Bitfields, HyperLogLog, Spatial Indexes und Streams.
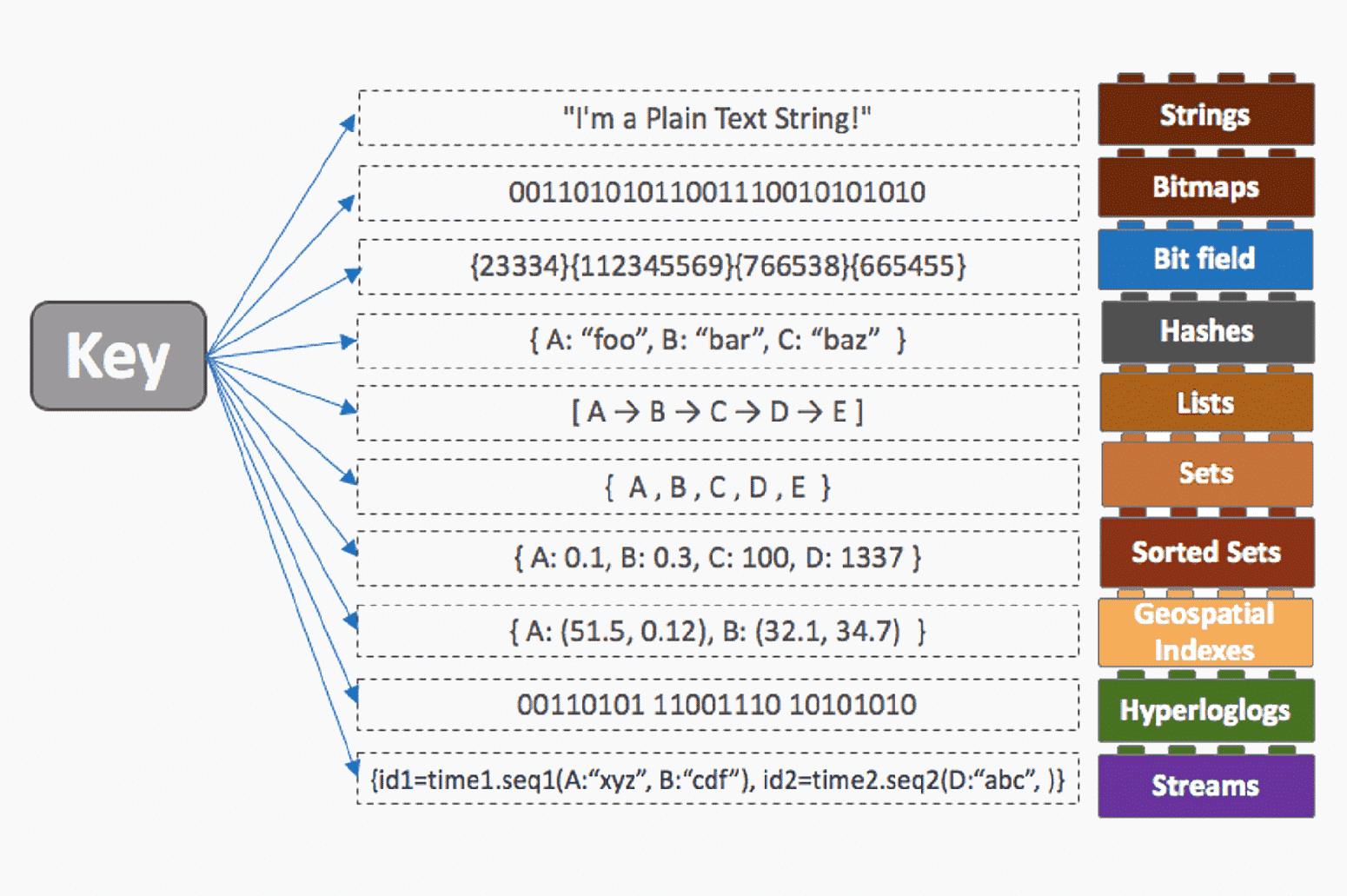
Jeder Strukturtyp hat dedizierte Befehle, die die Ausführung von Operationen der verschiedenen Werttypen erleichtern. Die Daten können dann im RAM-Speicher oder permanent auf der Festplatte gespeichert werden, indem die Backup-Funktion von Redis verwendet wird. Die Wiederherstellung der Daten im Falle eines Systemausfalls erfolgt durch diese automatisch oder manuell erstellten Sicherungen.
Redis bietet verschiedene Möglichkeiten, Daten in vielen modernen Anwendungsfällen zu modellieren.
Redis ist keine relationale Datenbank, daher ist das ACID-Konzept (Atomicity, Coherence, Isolation, Durability) nicht anwendbar. Atomare Transaktionen und Datenisolation zur Gewährleistung der Datenintegrität werden jedoch durch das Datenbankverwaltungssystem sichergestellt.
Was sind die Funktionen von Redis?
Dass Redis bei Entwicklern so beliebt ist, liegt an den vielen Funktionen, die die Datenbank bietet.
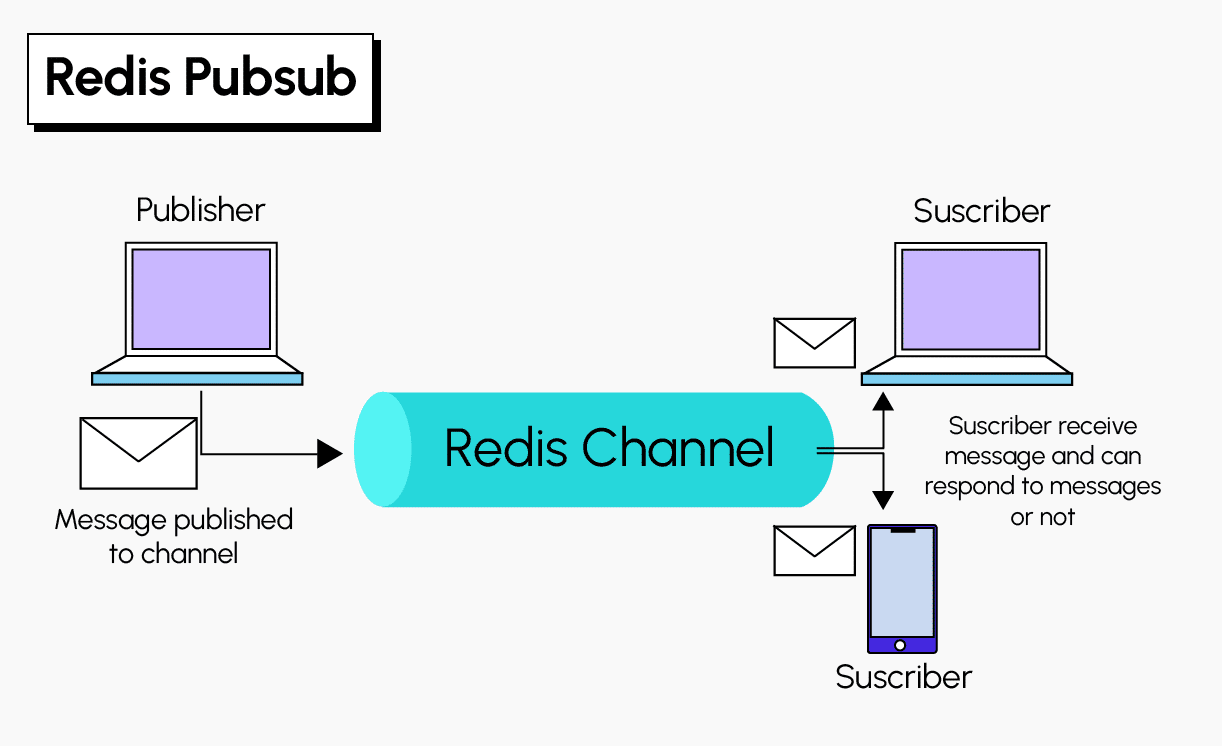
Die Publish/Subscribe-Funktion (pub/sub) von Redis ermöglicht es, Nachrichten in Echtzeit zwischen den verschiedenen Teilen einer Anwendung zu verbreiten. Die Funktionsweise dieses Broadcasts ist einfach. Die von den Absendern (Publishers) gesendeten Nachrichten werden nicht direkt an bestimmte Empfänger (Subscribers) gesendet, sondern laufen durch Kanäle (Channels). Nur die Abonnenten des jeweiligen Kanals erhalten die Nachricht, die „höchstens, einmal“ (at-most-once) gesendet wird. Das bedeutet, dass es keine Chance gibt, dass eine Nachricht, die einmal vom Redis-Server gesendet wurde, noch einmal gesendet wird. Aufgrund eines Fehlers oder einer Trennung vom Netzwerk ist die Nachricht unwiederbringlich verloren. Diese Entkopplung von Publishern und Abonnenten ermöglicht eine höhere Skalierbarkeit und eine dynamischere Netzwerktopologie.
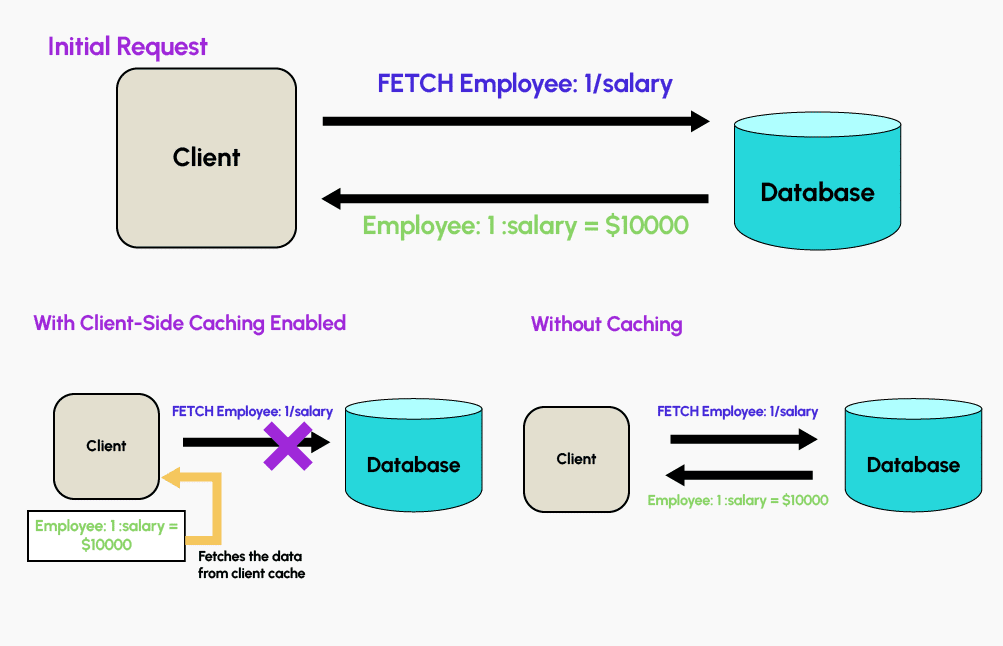
Redis bietet eine clientseitige Caching-Funktion an. Durch die Nutzung des Speichers auf den Anwendungsservern, um eine Teilmenge der Datenbankinformationen direkt in der Anwendung zu speichern, können sehr leistungsfähige Dienste erstellt werden.
Die Anwendung speichert die Antworten auf häufig gestellte Anfragen direkt in ihrem Anwendungsspeicher und kann sie später wiederverwenden, ohne die Datenbank erneut kontaktieren zu müssen. Du kannst sicherstellen, dass die im Cache gespeicherten Daten immer aktuell sind, indem du einstellst, dass die gespeicherten Daten nach einer bestimmten Zeit ablaufen.
Es ist für den Benutzer möglich, mehrere Redis-Befehle in einem einzigen Netzwerkvorgang an die Datenbank zu senden, indem er die Redis-Pipeline verwendet. Anstatt jeden Redis-Befehl einzeln zu senden, können mit einer Pipeline alle Befehle auf einmal gesendet werden, indem sie in einem einzigen Netzwerkpaket verschlüsselt werden. Der Redis-Server speichert diese Befehle dann in einer temporären Warteschlange, führt sie alle nacheinander aus und sendet die Ergebnisse in der gleichen Reihenfolge an den Client zurück. Dies ist eine sehr nützliche Funktion für Anwendungen, die eine große Anzahl von Befehlen auf einmal verarbeiten müssen, und um eine deutlich geringere Latenzzeit zu haben.
Redis unterstützt auch die automatische Sortierung von Daten, was Zeit spart und die Datenverwaltung vereinfacht. Diese Funktion ist besonders nützlich für Anwendungen, bei denen sortierte Daten in Echtzeit abgerufen werden müssen, wie z.B. Leaderboards.
Fazit
Redis ist eine Datenbank, die hauptsächlich in der Produktion eingesetzt wird. Sie ist aufgrund ihrer Speicherung im Arbeitsspeicher viel schneller als herkömmliche Datenbanken und verwendet die Festplatte nur für die Persistenz. Sie kann Millionen von Abfragen pro Sekunde verarbeiten, was sie ideal für Echtzeitanwendungen macht. Trotzdem ist Redis aufgrund seiner Stärke nicht in der Lage, die Anforderungen von Big Data perfekt zu erfüllen, da sich die gesamten Daten immer noch im RAM befinden. Bei sehr großen Datensätzen kannst du mit Leistungsproblemen und hohen Kosten für den Kauf von Servern mit ausreichend RAM rechnen.
Redis ist einfach zu verwenden, sowohl beim Einrichten der Umgebung als auch bei der praktischen Nutzung. Es ist jedoch möglich, komplexe Probleme mit dieser Technologie zu lösen und sie sogar für APIs oder für künstliche Intelligenz wie Gesichtserkennung zu verwenden.
Die Technologie beweist große Flexibilität, da sie von vielen Programmiersprachen wie C, C#, C++, Java, Python, Perl, PHP, Node.js unterstützt wird und die meisten Datentypen, die den Nutzern bereits bekannt sind, nativ unterstützt.
Insgesamt ist Redis eine ausgezeichnete Wahl für Anwendungen, die eine schnelle und zuverlässige Datenbank benötigen, und solche, die nicht mit großen Datenmengen umgehen müssen. Für die Produktionsphase ist es jedoch manchmal besser, Technologien zu wählen, die speziell für die Anforderungen von Big Data entwickelt wurden, wie Apache Hadoop, Apache Spark oder Cassandra. Die Beherrschung dieser Tools wird von vielen Unternehmen verlangt. Zögere nicht, dir die Data Engineer-Ausbildung von DataScientest anzusehen, um dir die Fähigkeiten anzueignen, die in der Welt der Big Data unerlässlich sind.







