
In einem früheren Artikel haben wir den Begriff Natural Language Processing (NLP) definiert. In diesem Artikel beschäftigen wir uns mit einer der wichtigsten NLP-Methoden, das Verfahren des Word Embedding (dt. Worteinbettung). Word Embedding bezeichnet eine Reihe von Lernmethoden, die darauf abzielen, Wörter in einem Text durch Vektoren reeller Zahlen zu repräsentieren. In diesem Artikel entdeckst Du drei Hauptmethoden, um ein Wort als Vektor darzustellen:
Methode : One Hot Encoding
Methode: Image Embedding
Methode: Word Embedding
One hot encoding
One hot encoding ist die klassische vektorielle Darstellung. Dabei wird jedem Wort des Wortschatzes eine Dimension zugewiesen. Jedes Wort des Wortschatzes wird als binärer Vektor dargestellt, wobei alle seine Werte mit Ausnahme des Wortindex 0 sind.

Nehmen wir diesen Satz als praktisches Beispiel:
"I think, therefore I am". Das Prinzip des One-Hot-Encodding besteht darin, jedem Wort des Wortschatzes einen Index zuzuweisen. Der Wortschatz sieht dann wie ein Wörterbuch aus:
{'am': 0, 'i': 1, 'therefore': 2, 'think': 3}. In diesem Fall besteht der Wortschatz aus den vier einzigartigen Wörtern unseres Korpus. Die Methode besteht darin, das Wort des Wortschatzes als Vektor der Dimension 4 (Wortschatzgröße) darzustellen. Die Werte des Vektors sind alle 0 außer dem Wortindex.
Onehot('i')=0 1 0 0 Bei dieser Darstellung haben alle Wörter den gleichen Abstand und die gleiche Ähnlichkeit. Das Verfahren des One-Hot-Encoding liefert also nur die Information, dass sich ein Wort von einem anderen unterscheidet.
Image Embedding
Die Größe eines Bildes wird durch seine Pixelzahl definiert. Konvolutionen werden benutzt, um Merkmale zu extrahieren, die relevanter sind als der Wert der Pixel. Beispielsweise könnten die Kerne, die zur Erkennung von Kanten dienen, nützlich sein, um bestimmte geometrische Formen zu klassifizieren.
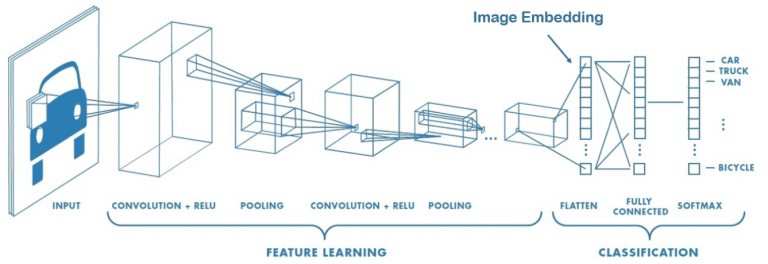
Mit Image embedding werden Convolutions/Pooling angewendet, um das Bild zu kodieren und Linearitätsbeziehungen zwischen Eigenschaften (Kunststil, spezifische Form …) und neuen Merkmalen unseres Bildes zu extrahieren.

Word Embedding
Genauso kann man mit Word Embedding durch Verringerung der Dimension den Kontext, die semantische und syntaktische Ähnlichkeit (Genus, Synonyme, …) eines Wortes erfassen. Beispielsweise würde man erwarten, dass die Wörter „Hund“ und „Katze“ durch Vektoren dargestellt werden, die in dem Vektorraum, in dem diese Vektoren definiert sind, relativ wenig voneinander entfernt sind.
Wie bei Bildern möchten wir, dass das Modell die relevantesten Merkmale auswählt, die das Wort repräsentieren. Zum Beispiel könnte das Merkmal „Lebewesen“ interessant sein, um „Hund“ von „Computer“ zu unterscheiden und „Hund“ und „Katze“ einander anzunähern.
Embedding-Matrix
Um die Dimension eines Vektors zu reduzieren, kann man das Ergebnis, das ein Dense Layer zurückgibt, als Embedding verwenden, d. h. eine Embedding-Matrix W mit der „One-Hot“-Darstellung des Wortes multiplizieren:
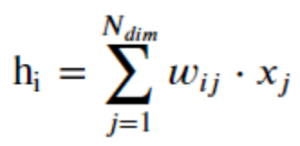
Es gilt :
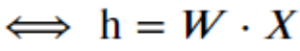
Nachdem wir nun die Methode der Dimensionsreduktion (durch Informationskomprimierung) definiert haben, wie trainieren wir die Embedding-Matrix W?
Embedding-Matrix und Klassifikationsproblem
Um die richtige Embedding-Matrix zu finden kann man sie auf ein überwachtes Problem anwenden. Dementsprechend werden wir die diese Wortdarstellung verwenden, um ein Problem der Sentiment Analysis (auch Sentiment Detection) bei IMBD-Rezensionen zu lösen. Der Datensatz umfasst 25.000 Filmkritiken (weitere Informationen zum Datensatz findest Du hier).
Es ist dann möglich, die W-Matrix des word embedding gleichzeitig mit dem Training des Klassifizierungsproblems zu trainieren.
Formatierung der Daten:
Um die Daten zu formatieren, muss der Textkorpus in eine Vektorgrafik umgewandelt werden, wobei jedes Review in eine Sequenz von ganzen Zahlen umgewandelt wird (jede ganze Zahl ist der Index eines Wortes):
tokenizer.texts_to_sequences(['hello my dear readers']) -> [[4422, 10, 2974, 6117]] 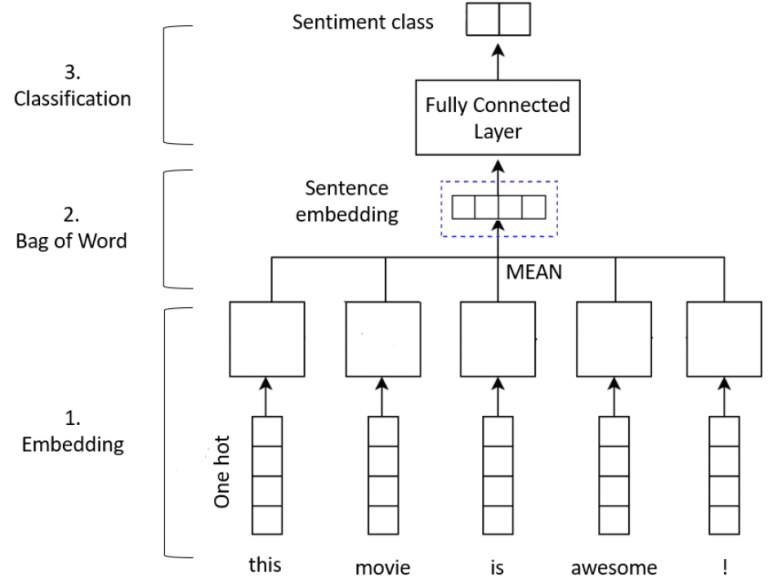
Unser Modell wird ein einfaches bag of word mit einer Embedding-Methode sein:
- Die embedding layer wird jeden Wortindex in einen Embedding-Vektor umwandeln. Die W-Matrix des Embeddings wird gelernt, während das Modell trainiert wird. Die resultierenden Dimensionen sind: (Batch, Sequenz, Embedding).
- Anschließend gibt die GlobalAveragePooling1D layer einen Ausgabevektor mit fester Länge für jedes Beispiel zurück, indem sie den Durchschnitt über die Sequenzdimension bildet. Diese Transformation besteht aus einem bag of word und ermöglicht es dem Modell, mit Eingaben variabler Länge umzugehen.
- Da wir schließlich mit einem Klassifizierungsproblem zu tun haben (positive oder negative Rezension), müssen wir Dense-Layer hinzufügen, um das sentiment der Rezension zu klassifizieren.
Und in der Praxis?
Auf diese Weise haben wir auf dem Testdatensatz eine Genauigkeit von 0,88 erreicht. Diese Punktzahl ist mit herkömmlichen Methoden nur schwer zu erreichen. Außerdem hätten wir auch ein Tf-idf-Maß (anstelle von bag of word) verwenden können, um unsere Sequenz in einen Vektor umzuwandeln.
Schlussfolgerungen:
So ein Modell liefert in der Regel bessere Ergebnisse als herkömmliche Ansätze. Es ermöglicht auch, die Dimension des Problems und damit die Lernaufgabe zu reduzieren. , Da wir nur eine Information über das Gefühl geben, erfasst jedoch das word embedding nur schwerlich eine andere Beziehung als diese.
In einem nächsten Artikel werden wir die embedding-Matrix unbeaufsichtigt mithilfe des bekannten word2vec-Algorithmus trainieren. Da das Training unüberwacht erfolgt, werden wir die Verzerrung vermeiden, die mit der Lösung eines überwachten Problems verbunden ist.
Hat Dir dieser Artikel gefallen? Möchtest Du noch mehr über Data Science lernen?







