Avec la masse et la variété des données disponibles, il convient d’adapter leur gestion. Dans un environnement où règne le Big Data, l’approche appropriée consiste à distribuer le stockage des données afin de faciliter leur traitement. Pour ce faire, une nouvelle catégorie de système de gestion de base de données appelée « No-SQL » a vu le jour. HBase en fait partie.
Plus précisément, HBase fait partie de la catégorie des systèmes de gestion de bases de données orientés colonne. Grâce à sa structure familière aux utilisateurs-métiers et sa grande capacité de gestion de données, HBase est de plus en plus utilisé par les entreprises, même lorsque la volumétrie de données est modeste.
Le concept général de HBase
Pour les systèmes de gestion de base de données (SGBD) orientés colonne, soit en “No-SQL”, la notion de base de données et la façon dont les données sont stockées sont très différentes des systèmes de gestion de bases de données relationnelles.
Apache HBase est un data store ou magasin de données orienté colonne utilisant des paires clé/valeur. La base de données HBase s’installe généralement sur le système de fichiers HDFS (pour Hadoop Distributed File System).
L’approche de ce dépôt de données centrée sur l’évolutivité lui permet de prendre en charge des tables de base de données extrêmement volumineuses, par exemple des tables contenant des milliards de lignes et des millions de colonnes.
HBase est un des composants additionnels d’Apache au même titre que Hive.
Fonctionnement de HBase
Contrairement aux systèmes de bases de données relationnelles, HBase ne supporte pas un langage d’interrogation structuré comme SQL ; en fait, HBase n’est pas un data store de données relationnelles.
Un système HBase est conçu pour évoluer linéairement. Il comprend un ensemble standard de tables avec des lignes et des colonnes, comme une base de données traditionnelle. Chaque table doit avoir un élément défini comme une clé primaire, et toutes les tentatives d’accès aux tables HBase doivent utiliser cette clé primaire.
HBase peut être qualifié comme un entrepôt de stockage de données. Alors que les systèmes de gestion de base de données assurent à la fois le stockage et le traitement des données, HBase de son côté, est plus spécialisé sur le stockage de celles-ci.
HBase est conçu pour :
- Stocker de très grosses volumétries de données « épaves », c’est-à-dire des données à structure irrégulière, avec de nombreuses valeurs nulles comme les matrices creuses en algèbre.
- Fournir un accès en temps réel à cette grosse volumétrie de données aussi bien pour les opérations de lecture que d’écriture sur le HDFS.
- S’appuyer sur les modèles de calcul distribués tels que le MapReduce, et de tous ses langages d’abstraction tels que Apache Hive, pour l’exploitation de ses données.

Pourquoi utilise-t-on HBase ?
Les avantages de HBase sont nombreux. Tout d’abord, cette base de données présente une importante tolérance aux pannes. En effet, les données sont répliquées sur les différents serveurs du Data Center et un basculement automatique garantit une haute disponibilité, en cas de panne.
De plus, le « sharding », soit la méthode de distribution qui consiste à séparer un jeu de données et l’équilibrage des charges et des tables, est automatique, ce qui simplifie les opérations.
Cette base de données non relationnelle est également « rapide ». En effet, elle est capable de proposer des aperçus des données en temps réel. Un caching in-memory est également proposé. Aussi, un autre avantage majeur est sa versatilité. En effet, les modèles de données peuvent avoir de nombreux cas d’usage. Enfin, il est possible d’exporter les métriques via les plug-ins file.
Par ailleurs, le stockage distribué proposé par HBase permet d’effectuer des requêtes sur des quantités massives de données. En outre, il est possible de « scaler » les capacités de lecture et d’écriture de cette technologie à des millions par seconde, ce qui permet de surmonter les limites des systèmes de gestion de bases de données relationnelles.
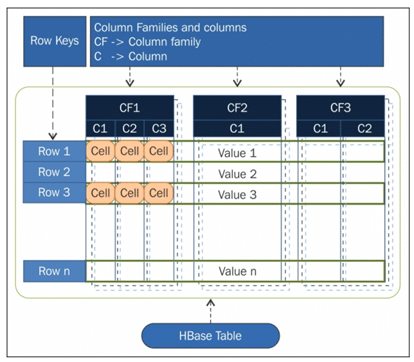
HBase permet de regrouper de nombreux attributs en familles de colonnes, de sorte que les éléments d’une famille de colonnes sont tous stockés ensemble. Ceci est différent d’une base de données relationnelle orientée ligne, où toutes les colonnes d’une ligne donnée sont stockées ensemble.
Un exemple de HBase
Une colonne HBase représente un attribut d’un objet. Admettons que la table stocke les journaux de diagnostic des serveurs de votre environnement. Chaque ligne pourrait être un enregistrement de journal. Aussi, une colonne typique pourrait être l’horodatage de l’enregistrement du journal, ou le nom du serveur d’où provient l’enregistrement.
Avec HBase, vous devez pré-définir le schéma de la table et spécifier les familles de colonnes. Cependant, de nouvelles colonnes peuvent être ajoutées aux familles à tout moment, ce qui rend le schéma flexible et capable de s’adapter aux exigences changeantes des applications.