
Réalisation d’une application pour calculer l’impact environnemental de sa consommation alimentaire.
1) Contexte & objectifs :
Le changement climatique est une réalité qui se manifeste sous nos yeux : inondations de juillet en Allemagne et en Belgique, dôme de chaleur accompagné de violents incendies au Canada. Le dernier rapport du Groupe d’expert.es intergouvernemental sur l’évolution du climat (GIEC) confirme l’influence humaine comme un fait établi et indiscutable.
Dans le cadre de notre cursus de Data Analyst, nous avons souhaité vous faire part du projet réalisé par trois de nos apprenants : Svetlana, Cédric et Josélito.
Pendant 17 semaines, ils ont travaillé sur la base de données Agribalyse produite par l’Agence de l’environnement et de la maîtrise de l’énergie (ADEME) permettant de connaître l’impact environnemental des produits agricoles en suivant la méthode de l’analyse du cycle de vie.
Ils ont élaboré une application permettant de calculer l’impact environnemental selon le type de consommation.
L’idée de départ : déterminer des profils types selon des régimes alimentaires.
Épaulé de leur mentor Raphaël, l’équipe s’est fixée plusieurs objectifs :
- Explorer de manière approfondie toutes les données mises à disposition
- Ajouter un score pour les agricultures conventionnelles/biologiques à partir du tableau de pondération EF3
- Créer des paniers moyens correspondant à 7 régimes existants
- Analyser l’impact de la consommation de ces paniers sur l’environnement
- Ajouter des profils artificiellement à partir de ces paniers moyens
- Entraîner un modèle de Machine Learning de prédiction du score EF en fonction du type de consommation
Le but : créer une application accessible pour que tout consommateur puisse évaluer son impact sur l’environnement et identifier les leviers d’améliorations dans ses choix de consommation.
2) Le projet :
Les jeux de données sont issus de la base de données Agribalyse 3.0 disponible librement sur ce site.
À chaque étape de la chaîne, des bilans de matières, d’énergie et d’émissions de polluants sont réalisés et agrégés sous forme d’un jeu d’indicateurs environnementaux.
14 indicateurs sont fournis pour chaque produit.
Il s’agit des indicateurs préconisés par la Commission Européenne (projet Product Environmental Footprint).
Ces 14 indicateurs ont vocation à couvrir un ensemble d’enjeux environnementaux (qualité de l’eau, de l’air, climat, sols).
À noter que l’ensemble des indicateurs est ramené à la fabrication de 1 kg de produit alimentaire.
Un score unique est également proposé : il s’agit du « single score EF » préconisé par la Commission Européenne, calculé avec des facteurs de pondération pour chacun des indicateurs.
Ce score s’exprime en Millipoints ou MPt/kg. Plus il sera élevé, plus le produit aura une empreinte écologique forte.
“La pondération prend à la fois en compte la robustesse relative de chacun de ces indicateurs et les enjeux environnementaux. Ce score est un score moyen, qui comprend un arbitraire certain et peut être adapté en fonction des enjeux du contexte d’application.” (source : agribalyse)
Des variables qualitatives viennent s’ajouter à ce score : groupe d’aliments, sous-groupe d’aliments, nom du produit, saisonnalité, matériau d’emballage, mode de livraison, usage de l’avion ou non, type de préparation, code CIQUAL (table de composition nutritionnelle des aliments) et d’une note de qualité de la donnée DQR (1 excellente à 5 très faible).

L’équipe s’est donc lancée dans une première exploration des données avec un nuage de point et une matrice des corrélations.
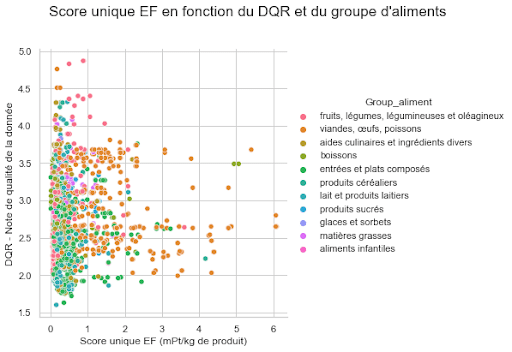
Première observation pour tous les groupes d’aliments, c’est l’agriculture qui semble influencer significativement le score unique et qui différencie l’empreinte écologique des différents groupes d’aliments.
En effet, l’étape de transformation serait la deuxième étape de production avec le plus d’influence mais les valeurs sont assez hétérogènes, entre 0 et 1.
Cela dépend du type de produits auxquels nous nous confrontons : certains groupes d’aliments sont plus transformés que d’autres comme les aides culinaires et ingrédients divers ou les produits sucrés.
La catégorie viande, oeuf, poisson arrive en tête avec les plus forts scores uniques EF (>6).
En effet, il faut rappeler que la production de viande est en général très gourmande en eau. L’élevage émet également des quantités importantes de nitrates, phosphates et autres substances.

La matrice des corrélations offre une autre lecture des variables.
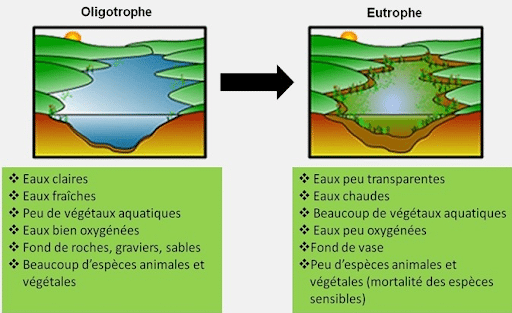
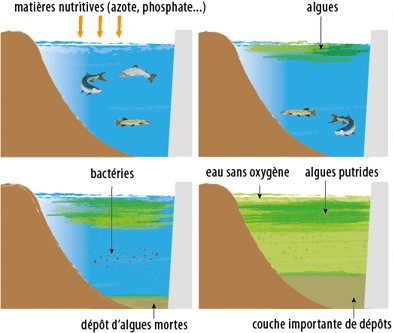
Par exemple, nous observons que les variables particules et acidification ont une corrélation très élevée avec l’eutrophisation des terres (>0.95).
Cette même variable eutrophisation des terres est également très corrélée avec les variables changement climatique et l’usage des sols
Ce résultat confirme l’impact de la production à partir des sols agricoles qui engendre un appauvrissement de l’écosystème.
Sans surprise, les impacts environnementaux sont multiples et sont liés entre eux.

Dans le graphique ci-dessus, l’équipe analyse l’empreinte carbone du matériau d’emballage.
A titre d’exemple, si nous comparons une canette en aluminium de 330 ml et des bouteilles en PET (Polyéthylène téréphtalate) avec un contenu recyclé minimum, l’empreinte carbone d’une canette en aluminium est 2 à 4 fois supérieure.
Il est important de noter que l’empreinte carbone d’une canette en aluminium ne sera comparable à celle d’une bouteille en PET que si elle contient une quantité moyenne d’aluminium recyclé et utilise des énergies renouvelables pour la produire.
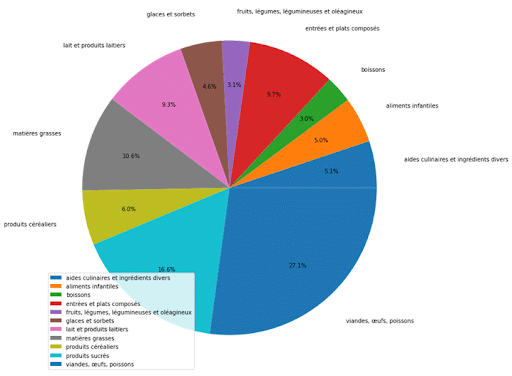
Avec le graphique suivant, l’équipe a observé l’impact des groupes d’aliments sur le changement climatique.
Les émissions les plus importantes proviennent des produits appartenant aux groupes suivants:
- viandes, œufs, poissons : 27.1%
- produits sucrés : 16.6%
- matières grasses : 10.6%
Une représentation de l’impact de la production agricole, selon le type bio ou conventionnel par rapport à certains indicateurs est ensuite proposée dans les graphiques suivants :
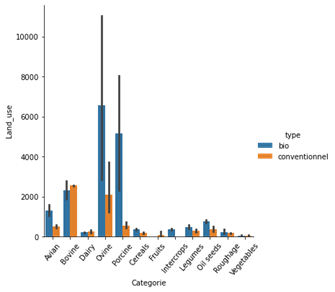

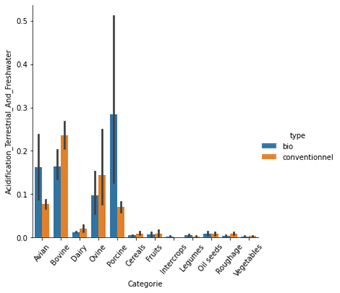
À la lecture des graphiques, le bilan global de l’agriculture biologique apparaît mitigé.
En effet, elle entraîne des émissions indirectes de dioxyde de carbone plus élevées que l’agriculture conventionnelle : les rendements sont inférieurs avec par exemple un usage plus élevé de terres par unité de production et le refus d’utiliser des engrais chimiques.
Cependant, ces résultats sont à nuancer : l’agriculture biologique a un effet plus bénéfique sur les écosystèmes locaux et les émissions directes sont plus faibles du fait de l’élimination des énergies fossiles
Création et analyse de paniers moyens selon 7 régimes existants :
L’équipe a creusé dans un premier temps les données des cantines scolaires pour constituer des menus types. Cependant, cette piste manquait de données synthétiques disponibles.
Elle s’est finalement appuyée sur les résultats de la troisième étude Individuelle Nationale des Consommations Alimentaires (INCA) publiés par l’Anses (L’Agence nationale de sécurité sanitaire de l’alimentation, de l’environnement et du travail).
Plus de 5 800 personnes (3 157 adultes âgés de 18 à 79 ans et 2 698 enfants âgés de 0 à 17 ans) ont participé à cette grande étude nationale qui a mobilisé en 2014 et 2015 près de 200 enquêteurs.
150 questions ont été posées aux participants sur leurs habitudes et modes de vie, 13 600 journées de consommations ont été recueillies, générant des données sur 320 000 aliments consommés.
Sur la base des études de l’INCA 3, le groupe constitue un nouveau data frame à partir duquel il calcule la quantité de consommation d’un adulte par an selon 7 types de régime alimentaire.

Ces nouvelles données permettent de calculer l’impact environnemental (score EF moyen/an) en fonction de ces 7 régimes alimentaires.
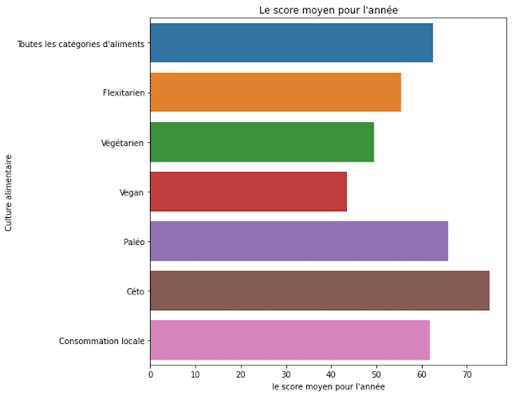
Sans surprise, les régimes végétaliens et végétariens ont un impact environnemental réduit.
Modèle de ML pour la création de l’application :
Les jeux de données n’étaient pas suffisamment étoffés en terme de profils différents.
L’équipe va s’atteler dans un premier temps à créer des profils artificiellement à partir de ces paniers moyens.
1 000 profils sont générés afin d’avoir un échantillon suffisamment pertinent.
La tâche de machine learning du projet est lancée. Elle s’apparente à la création d’un modèle de classification optimal après regroupement des scores en classe.
Plusieurs méthodes y compris en apprentissage non-supervisé lors des premières itérations, ont été testées :
- K plus proches voisins
- Support Vector Machine
- Randomforest
- Clustering : K-Means
- Clustering : Classification ascendante hiérarchique
La métrique de performance principale utilisée est la matrice de confusion.
L’accuracy obtenue sur l’échantillon d’apprentissage et mesurée par validation croisée a été utilisée.
Les 3 modèles offrent des résultats très disparates et le Support Vector Machine apparaît le plus performant.
- SVM : score = 0,72
- RF : score = 0,56
- KNN : score = 0,31
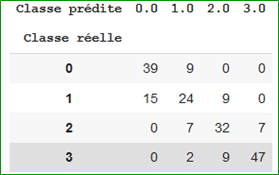
Le modèle SVM obtient un score positif : en effet, la target (score/classe) est directement calculé depuis les valeurs des variables.
L’équipe a transformé les variables en classe : cette modification aurait dû diminuer la performance du modèle, néanmoins elle est contrebalancée par la transformation de la target « score » en classe.
Par ailleurs, l’algorithme SVM a l’avantage de bien fonctionner sur de plus petits datasets ce qui est notre cas.
Il offre une grande précision de prédiction et peut-être plus efficace car il utilise un sous-ensemble de points d’entraînement.
Le modèle proposé permet d’obtenir un résultat de son impact global sur l’environnement à partir de choix de niveau de consommation (0 à 4) pour chaque sous-groupe d’aliments.
Même si le modèle manque de précision (quantités réelles), le choix d’avoir mis en place des classes est assez innovant et devient plus accessible en termes d’usage.
L’objectif est atteint !
3) Difficultés rencontrées
Le principal verrou scientifique était d’étoffer la base de données initiale afin de créer des profils artificiellement sur lesquels l’équipe pouvait appliquer une variabilité et des classes adéquates permettant de concevoir une application qui calcule l’impact selon le type de consommation.
D’autre part, des variables supplémentaires auraient permis de creuser plus loin leur projet : distance du transport, lieu de production, détails des aliments pour la création de menu.
Par ailleurs, l’équipe rappelle que les méthodes de calcul et les paramétrages d’Agribalyse ne permettent pas de faire de l’éco-conception ou d’améliorer les pratiques « au champ ». Or les principaux leviers d’amélioration du score environnemental dépendent des systèmes de production.
4) Bilan
Svetlana, Cédric et Josélito ont tenté d’utiliser toutes les données mises à disposition par le site AGRIBALYSE afin de proposer un modèle robuste et étoffé.
Un modèle qui identifie pour tout individu selon son type d’alimentation, les leviers qui permettent de réduire son impact sur l’environnement.
Leur modèle s’inscrit dans plusieurs processus métiers :
- Aide à la décision dans la production et la mise sur le marché d’un nouveau produit alimentaire (plat préparé, agriculture adéquate…)
- Moteur de recommandation pour les consommateurs dans leurs choix de consommation et de leurs impacts environnementaux.
Leur application fait donc écho à un domaine d’actualité et prouve que l’IA peut être mise au service des enjeux environnementaux (appauvrissement des sols, conséquences climatiques) dans le cadre de l’alimentation (de la production jusqu’à l’assiette du consommateur).
Il serait intéressant de constituer une base de données actualisée, encore plus étoffée et comprenant des indicateurs supplémentaires : distance du transport, usage de phytosanitaires… dans le but d’améliorer encore davantage les performances du modèle.
À titre de comparaison, la start-up qui a développé l’application Yuka, a lancé cette année un nouvel onglet dédié à l’écoscore, avec une notation de A à E sur 30 000 produits pour « permettre aux consommateurs qui le souhaitent de s’orienter vers une alimentation plus durable »
Si tout comme eux, vous souhaitez monter en compétences et mettre en application vos acquis :









