
Ham/Spam distribution
L’ensemble de données contient un ensemble d’environ 4000 e-mails datant de 2010, rédigés en anglais et divisés en deux dossiers spam et ham (e-mails sains). Les e-mails sont composés d’un corps et d’un en-tête. L’en-tête contient généralement le sujet, la date, l’expéditeur, etc.
Le ratio spam / ham est de 32%, comme on peut le voir sur le graphique ci-dessous :
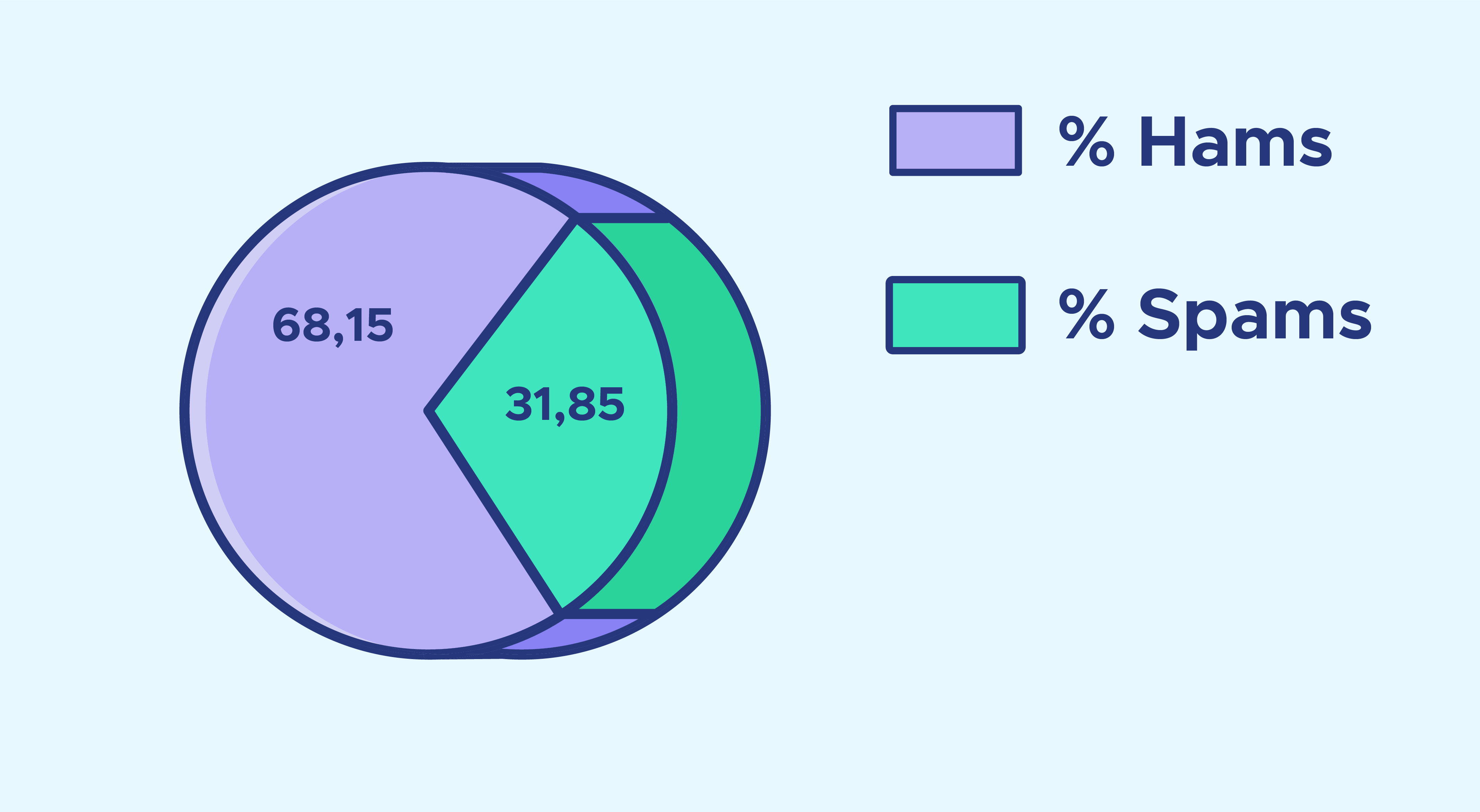
En effet les hams représentent environ 68% de l’ensemble de nos emails contre environ 32% pour les spams. L’en-tête de chaque email contient beaucoup d’informations lorsqu’il est rempli (27 fonctionnalités), mais quand on regarde le nombre de valeurs manquantes dans les en-têtes de nos mails, voici ce que l’on obtient :
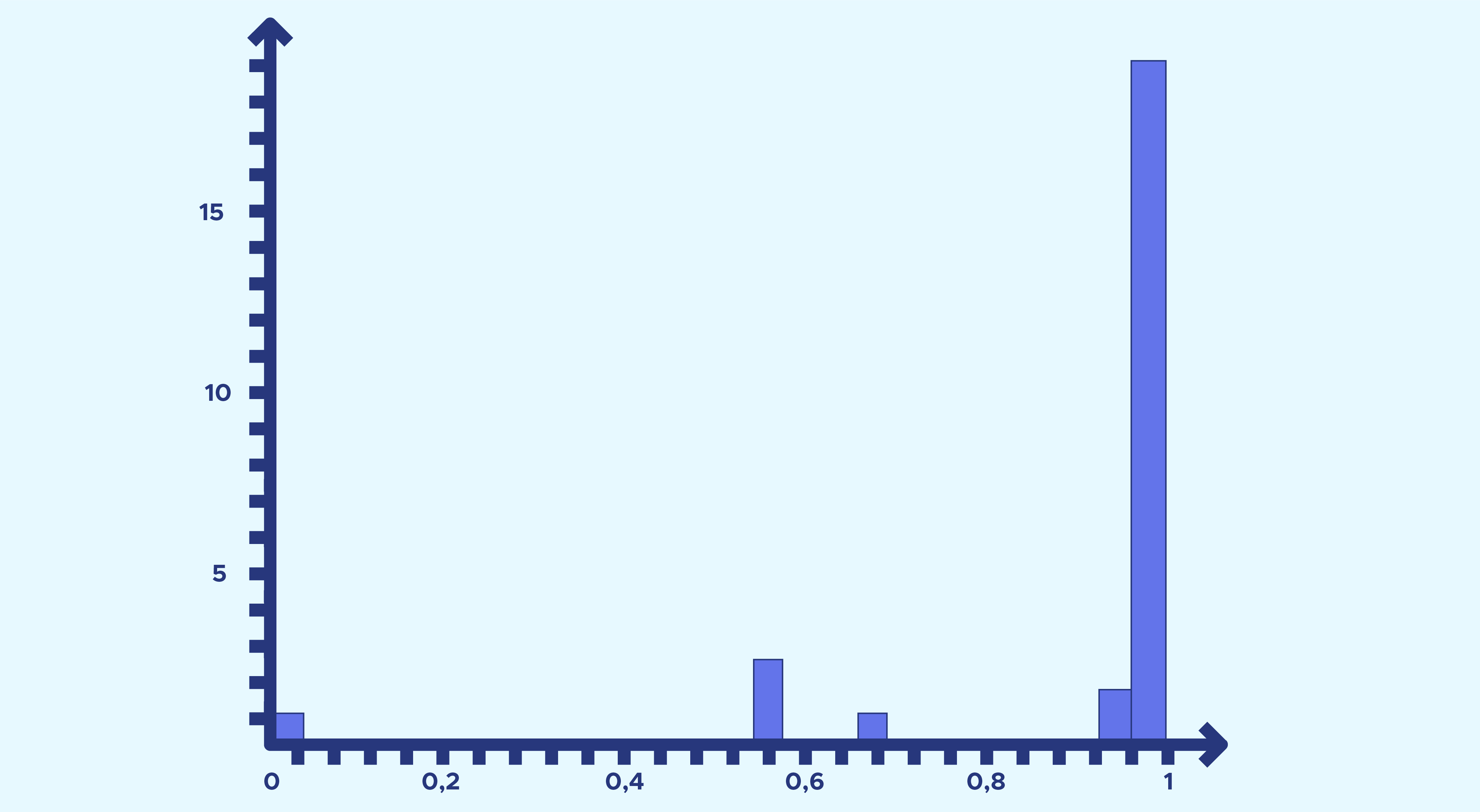
Nous nous apercevons que 19 variables du header ont plus de 90% de valeurs manquantes dans notre jeu de données. Ces variables du header n’ont donc pas été utilisées, nous nous sommes concentrés sur le corps du mail.
Nous avons construit un DataFrame contenant l’ensemble des emails avec pour features le texte du mail. Puis nous avons créé d’autres features, par exemple nous avons cherché à renseigner le nombre de caractères spéciaux, le nombre de mots en majuscules, le nombre de liens http (non sécurisés de fait) etc.
Il peut être intéressant de se faire une idée du contenu des mails en utilisant des wordclouds. Sur ces images, plus l’occurrence d’un mot est forte dans notre jeu de données plus la police de ce mot sera large dans le wordcloud :
Notre modèle permet de traiter simultanément des variables textuelles et numériques via la création d’une matrice creuse après la tokenisation du texte. Un test de classification Random Forest est ensuite effectué sur cette matrice creuse.
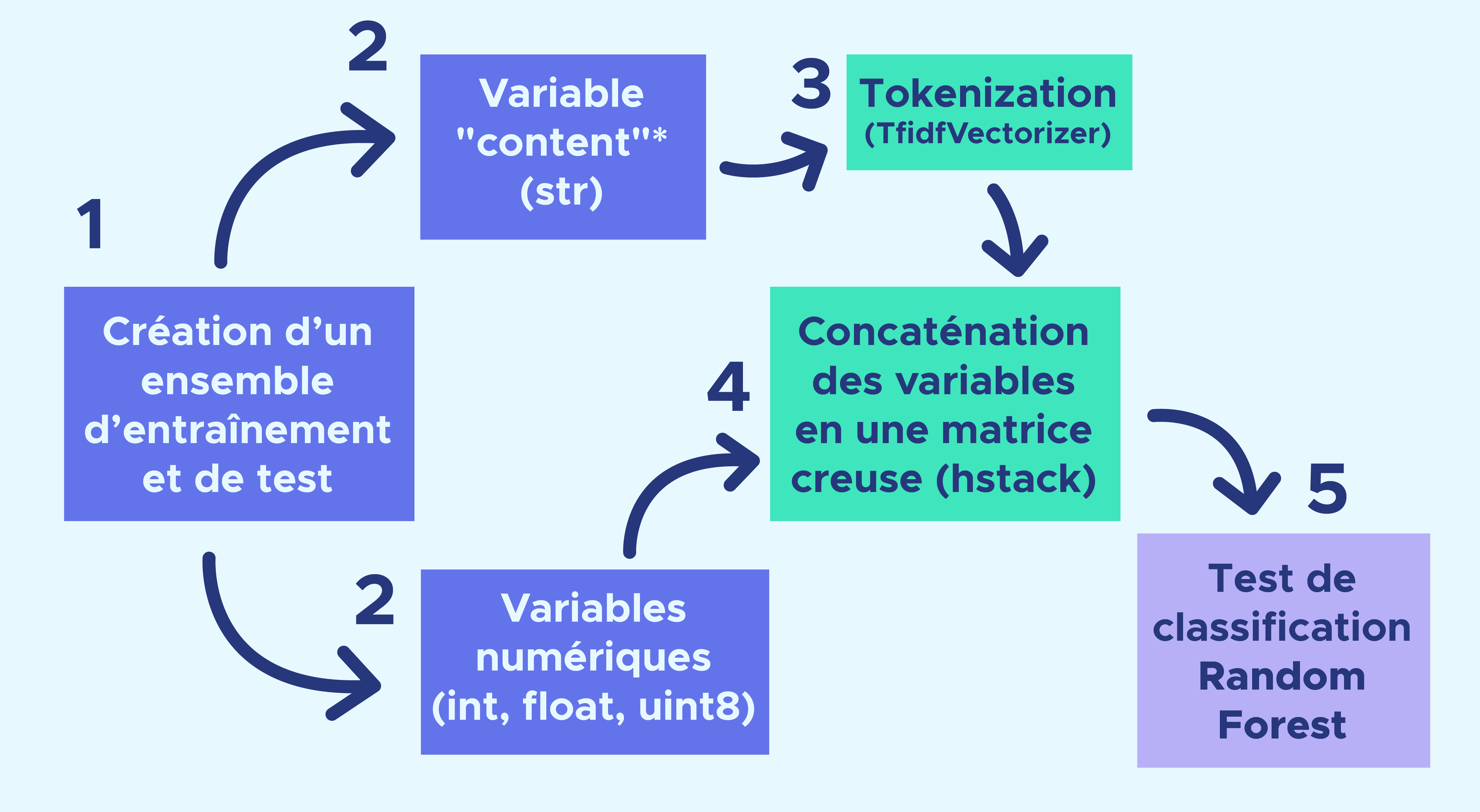
*La variable content n’est rien d’autre que le message du mail.
Tout d’abord, notre jeu de données est divisé en un ensemble d’entraînement et un ensemble de tests. La méthode du Bag of Words est un procédé couramment utilisé en NLP qui nous a permis de numériser notre variable de texte (« content »).
A la différence d’un tokenizer plus classique, Tf-IDF-Vectorizer permet de prendre en compte la fréquence d’apparition d’un mot dans un élément du dataset ainsi que la rareté de ce même mot au sein de l’ensemble du dataset. Ces Bags of words sont ensuite fusionnés avec les variables numériques créés lors de l’étape de feature engineering dans une seule et unique matrice creuse.
L’entraînement d’un algorithme de classification peut alors être effectué et ses performances peuvent être évaluées par matrice de confusion et calcul du F1-score. La comparaison de différents algorithmes de classification (SVM, LR,RF) nous a permis d’identifier le modèle Random Forest comme celui offrant les meilleures performances (Précision et F1-score > 97%).









