
La modification des attributs du visage, aussi appelé Facial Attribute Editing, désigne l’ensemble des méthodes qui ont pour but de modifier un ou plusieurs attributs d’un visage donné. Avant l’arrivée du Deep Learning, cette tâche était fastidieuse car faite à la main pixel par pixel. Mais, depuis peu, de nouveaux algorithmes ont vu le jour et permettent d’automatiser cette cette modification. Nous allons ici étudier en détail le modèle AttGAN qui fait partie de ces algorithmes basés sur les réseaux de neurones. Cet algorithme prend en paramètre le visage que nous voulons modifier ainsi qu’un vecteur d’attribut binaire et renvoie le visage modifié avec les attributs voulus. Des exemples de son fonctionnement sont montrés ci-dessous :
1- Architecture du AttGAN
Pour obtenir un visage modifié en cohérence avec le visage original, le modèle a été construit pour suivre 3 règles.
- Premièrement, le nouveau visage doit ressembler à celui de base (hors attribut).
- Ensuite, il doit également être visuellement réaliste, c’est-à-dire que les attributs créés doivent respecter des contraintes de tailles et de position.
- Pour finir, il doit bien posséder les attributs demandés. C’est pour cela que l’on peut décomposer l’architecture de l’AttGAN en 3 parties principales.
Premièrement, un apprentissage non supervisé par reconstruction dans l’espace latent est utilisé afin de préserver les détails du visage hors attribut. Cette tâche est effectuée par un Auto Encoder. Si vous voulez en savoir plus sur le fonctionnement d’un Auto Encoder, un article traitant du sujet est disponible sur le blog.
La partie Décodeur de cet Auto Encoder est ensuite utilisée pour entraîner un Générative Adversarial Network (GAN) afin d’obtenir un visage modifié visuellement réaliste. De même, si vous voulez vous renseigner sur le GAN, il y a également un article disponible sur le blog (https://datascientest.com/generative-model-ou-modele-generatif).
Enfin, pour vérifier que le nouveau visage obtenu possède bien les nouveaux attributs demandés, une contrainte de classification est appliquée à l’image générée et les attributs détectés sont comparés aux attributs demandés.
On peut illustrer cette architecture avec l’image ci-dessous qui présente une itération de l’entraînement de l’AttGAN :
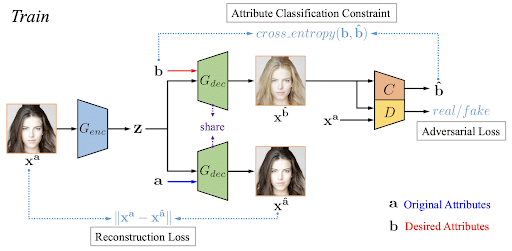
Sur ce schéma, l’image de gauche est l’image originale et le vecteur a contient ses attributs (femme, jeune, brune, …). Le vecteur b, quant à lui, désigne le vecteur d’attributs désirés (femme, jeune, blonde, …).
L’Auto Encoder est entraîné de manière à minimiser la reconstruction Loss qui est tout simplement la norme de la différence entre l’image originale et l’image reconstruite. En ce qui concerne le GAN, son but va être de générer une nouvelle image avec les attributs souhaités b et de tromper le discriminateur D pour que cette image ressemble fortement à l’image originale. La classification de contrainte se fait tout simplement par une détection du vecteur d’attribut dont la fonction de perte est une Cross Entropy.
Ainsi, pour faire plus simple, durant sa phase d’entraînement, l’AttGAN va apprendre à quoi correspond chaque attribut en se basant sur sa base de données d’entraînement.
Voyons maintenant ce qui se passe durant la phase de Test, lorsque nous voulons modifier un visage :

Une fois que la partie Décodeur / Générateur est entraînée, pour transformer une image, on se sert de la partie Encoder pour encoder l’image dans l’espace latent tout en spécifiant les nouveaux attributs souhaités et le Générateur génère tout simplement une nouvelle image grâce à toutes les règles qu’il a apprises durant sa phase d’entraînement.
2 - Base de données utilisée pour entraîner l’AttGAN
La base de données qui a été utilisée par les créateurs de cet algorithme est CelebA. Elle recense plus de 200 000 visages de 10 177 personnalités connues différentes annotés à l’aide de 40 attributs sous forme de vecteurs binaires qui précisent si l’attribut est présent (1) ou non (0). Ces 40 attributs peuvent aller d’une simple couleur des cheveux jusqu’à la présence ou non de maquillage sur le visage.

Pour accélérer l’entraînement de l’algorithme, seulement 13 de ces 40 attributs ont été utilisés : chauve, frange, cheveux noirs, cheveux blonds, cheveux châtains, sourcils épais, lunettes, homme, bouche ouverte, moustache, barbe, peau pâle, jeune.
3- Résultats obtenus et comparaison avec d’autres algorithmes d’édition d’attributs
Voici les résultats obtenus après un entraînement du réseau de neurones sur 50 epochs qui correspond à peu près à une journée :

Les deux premières images de chaque ligne représentent l’image originale et l’image reconstruite par l’Auto Encoder et les images suivantes sont les images générées en ne modifiant qu’un attribut à la fois sur les 13 dans l’ordre d’énonciation ci-dessus.
- Premièrement, on peut constater que les visages générés sont en cohérence avec les visages d’origine.
- De plus, on retrouve bien les attributs demandés même si certains ont du mal à être générés.
- Enfin, les attributs générés sont visuellement réalistes.
Ceci est dû aux 3 règles que l’on a imposées dans l’architecture durant l’entraînement.
Cependant, on peut remarquer que certains attributs paraissent plus naturels que d’autres. C’est le cas de l’ouverture de la bouche et de la couleur des cheveux. A l’inverse, les attribut “chauve” ou encore “lunettes” sont plus difficiles à obtenir. On peut donc en conclure que les modifications qui consistent à ajouter ou retirer de la matière sont celles qui ont été le moins entraînées.
Comparons maintenant ce modèle à d’autres types de réseaux de neurones effectuant la même tâche :

Ici, on compare l’AttGAN à deux autres modèles dont l’architecture est un peu différente : Le VAE / GAN et l’IcGAN. On s’intéresse à la reconstruction de l’image originale ainsi qu’à quelques attributs pour chaque modèle. On remarque que l’AttGAN est le seul modèle capable de reconstruire quasi parfaitement le visage original alors que les autres le modifient légèrement. On peut donc en déduire que même si les autres modèles d’édition d’attributs réalisent bien la modification, ils ne respectent pas le principe de base qui est de préserver les détails du visage hors attribut.
4- Conclusion
Dans cet article, nous avons vu en détail un modèle de réseaux de neurones permettant de réaliser l’édition d’attributs sur des visages, l’AttGAN. Nous avons décrit son architecture divisée en 3 parties qui permet d’obtenir des images très cohérentes par rapport aux images originales. Puis, nous avons comparé ce modèle avec d’autres réseaux de neurones également utilisés dans l’édition d’attributs et nous avons remarqué que c’était l’AttGAN le plus abouti pour le moment.
Si vous avez aimé cet article et que vous voulez découvrir d’autres méthodes de Deep Learning, je vous invite à rejoindre notre cursus expert en Deep Learning.








