
Les modèles d'apprentissage automatique sont des outils puissants pour résoudre des problèmes complexes, qu'il s'agisse de prédire les tendances boursières ou de diagnostiquer des maladies. Toutefois, pour tirer le meilleur parti de ces modèles, il faut comprendre le rôle des hyperparamètres et savoir comment les optimiser pour obtenir de meilleures performances.
Dans cet article, nous examinerons les différents types d’hyperparamètres et les techniques utilisées pour les optimiser. Nous aborderons également l’importance de comprendre les relations entre les hyperparamètres et les performances du modèle, ainsi que les compromis qui doivent être faits.
Qu'est-ce qu'un hyperparamètre ?
Un hyperparamètre est un paramètre qui est utilisé pour configurer un modèle de Machine Learning. Contrairement aux paramètres du modèle, qui sont appris à partir des données d’entraînement, les hyperparamètres doivent être définis par l’utilisateur avant de commencer l’entraînement du modèle.
Les hyperparamètres sont généralement choisis en fonction de la performance souhaitée du modèle, ainsi que de ses caractéristiques et de ses limites.
Pourquoi les hyperparamètres sont-ils importants ?
Les hyperparamètres sont importants car ils peuvent avoir un impact significatif sur la performance du modèle. Par exemple, en utilisant des valeurs inappropriées, il est alors possible de surapprendre (overfitting) ou de sous-apprendre (underfitting) sur les données d’entraînement.
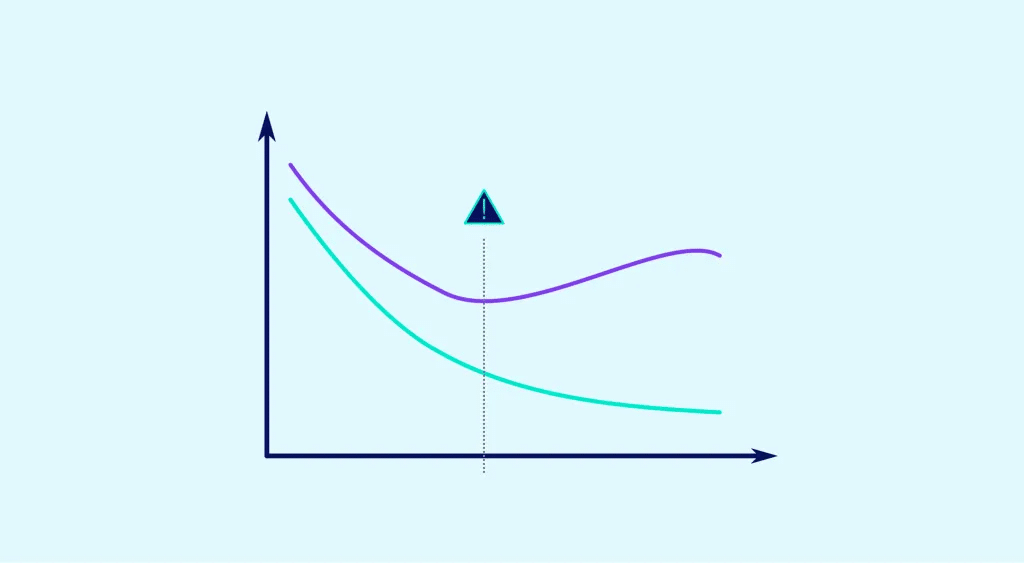
L’overfitting va se produire lorsque le modèle s’adapte trop étroitement aux données d’entraînement et ne généralise pas bien aux données de test. Cela peut entraîner une baisse de la performance du modèle sur les données de test.
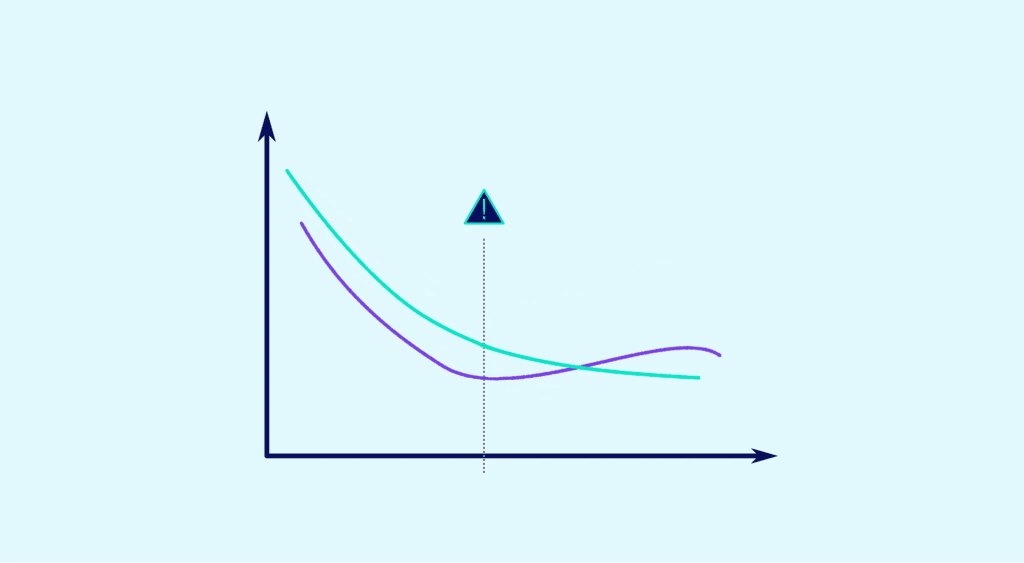
L’underfitting, quant à lui, se produit lorsque le modèle ne s’adapte pas suffisamment aux données d’entraînement et ne parvient pas à capturer les relations complexes présentes dans les données. Cela peut donc amener à une baisse de la performance du modèle sur les données d’entraînement et de test.
En résumé, il est important de choisir les hyperparamètres de manière à éviter l’overfitting et l’underfitting et ainsi obtenir un modèle performant sur les données de test.
Quelles différences entre les Hyperparamètres ?
Il existe plusieurs méthodes pour choisir les hyperparamètres d’un modèle. Voici quelques exemples :
Recherche en grille (grid search)
Ce paramètre consiste à essayer toutes les combinaisons possibles des hyperparamètres, en entraînant un modèle pour chaque combinaison, et en choisissant la combinaison qui donne les meilleurs résultats. Cette méthode peut être très efficace, mais elle peut prendre beaucoup de temps si vous avez beaucoup d’hyperparamètres et de valeurs possibles à essayer. De plus, elle peut être coûteuse en termes de ressources de calcul si vous avez besoin de beaucoup d’entraînements de modèle pour trouver les meilleures combinaisons.
Malgré ces inconvénients, la recherche en grille reste une méthode populaire pour choisir les hyperparamètres et peut être très efficace dans de nombreuses situations. Si vous avez le temps et les ressources de calcul nécessaires, c’est une approche à considérer pour choisir les hyperparamètres de votre modèle.
Random search
La recherche aléatoire consiste à sélectionner aléatoirement différentes combinaisons d’hyperparamètres et à entraîner un modèle pour chaque combinaison. Cette méthode peut être moins efficace que la recherche en grille, mais l’avantage est qu’elle est souvent plus rapide à mettre en œuvre et peut donner de bons résultats dans certaines situations.
Optimisation bayésienne
Consiste à utiliser une distribution de probabilité sur les hyperparamètres et à mettre à jour cette distribution en fonction des résultats obtenus lors de l’entraînement du modèle. Cette méthode peut être plus efficace que la recherche en grille et la recherche aléatoire, mais elle nécessite généralement l’utilisation d’outils spécialisés et peut être plus complexe à mettre en œuvre.

Expérimentation et essais-erreurs
Consiste à essayer différentes valeurs d’hyperparamètres de manière itérative et à ajuster les hyperparamètres en fonction des résultats obtenus. Cette méthode peut être utile lorsque vous avez une bonne compréhension des hyperparamètres et de leur impact sur le modèle, mais elle peut être moins efficace que les autres méthodes lorsque vous ne savez pas quels hyperparamètres sont les plus importants.
En fin de compte, le choix des hyperparamètres dépend de nombreux facteurs, tels que la complexité des données, la performance souhaitée et les ressources disponibles. Il est recommandé de tester plusieurs approches pour trouver les hyperparamètres qui donnent les meilleurs résultats pour votre modèle.
Conclusion
Les hyperparamètres sont des paramètres qui sont utilisés pour configurer un modèle de Machine Learning et qui peuvent avoir un impact significatif sur sa performance. Il est important de choisir les hyperparamètres avec soin pour éviter l’overfitting et l’underfitting et obtenir un modèle performant. Il existe plusieurs méthodes pour choisir les hyperparamètres, chacune ayant ses propres avantages et inconvénients. En fin de compte, le choix des hyperparamètres dépend de nombreux facteurs et peut nécessiter des essais et des erreurs pour trouver les meilleures valeurs.









