|
Fondements Philosophiques |
Son approche est orientée vers le processus métier. Elle vise à construire l'entrepôt de données de manière incrémentielle, en commençant par les domaines qui apportent le plus de valeur à l'entreprise. |
Sa vision est celle d'un entrepôt de données d'entreprise, centralisé et holistique. Il préconise la construction d'un grand entrepôt de données normalisé, suivi par la création de magasins de données dérivés pour des besoins spécifiques. |
 |
Architecture |
Favorise une approche ascendante ("bottom-up"), en commençant généralement par la création de magasins de données pour répondre à des besoins spécifiques, qui peuvent ensuite être intégrés dans un entrepôt de données plus large. |
Favorise une approche descendante ("top-down"), en construisant d'abord un vaste entrepôt de données d'entreprise, puis en dérivant des magasins de données pour des applications spécifiques. |
 |
Modélisation |
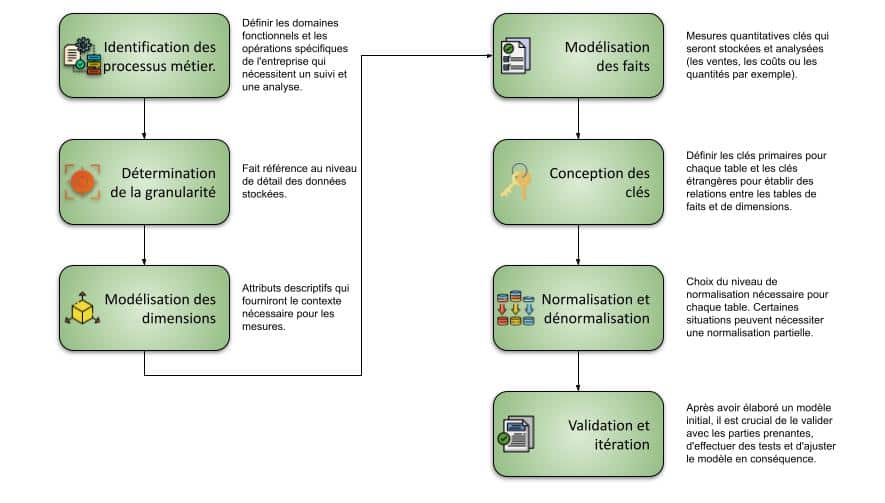
Modélisation dimensionnelle : les données sont organisées en tables de faits et de dimensions, comme abordé dans cet article |
Modélisation en 3NF (troisième forme normale) : pour l'entrepôt de données central, assurant une intégrité et une cohérence maximales. |
 |
Processus de chargement des données |
Le processus ETL est généralement direct, alimentant les données du système source directement dans les magasins de données ou l'entrepôt. |
Les données sont d'abord chargées dans l'entrepôt de données central, puis un processus ELT est utilisé pour alimenter les magasins de données dérivés. |
 |
Flexibilité et cohérence |
La méthode Kimball offre une mise en œuvre plus rapide et une meilleure flexibilité pour répondre aux besoins changeants (elle peut nécessiter plus d'efforts pour garantir la cohérence entre les différents magasins de données). |
Avec son approche holistique, Inmon assure une cohérence maximale des données à travers l'entreprise (la mise en œuvre initiale peut être plus longue et coûteuse). |