
Google Colab est un service de notebooks Jupyter en ligne qui permet dʼécrire et dʼexécuter du code en Python depuis son navigateur web. Gratuit, accessible avec un compte Google, Colab est tout indiqué pour lʼanalyse de données et la data science avec Python, avec ses cellules de code et ses blocs de texte en syntaxe Markdown, pour structurer et commenter le code.
Un notebook créé sur Colab est enregistré sur Google Drive. En pratique, il s’agit d’un fichier .ipynb qui, une fois téléchargé sur ordinateur, peut être ouvert et utilisé en local avec Jupyter notebook. À l’inverse, un fichier .ipynb créé en local avec Jupyter notebook peut être uploadé sur Google Drive pour être édité et exécuté dans Colab pour accéder à des ressources informatiques, y compris des GPU[1] et des TPU[2]. Pour travailler en équipe à distance, il est possible de partager un notebook Colab comme on le ferait avec un document Google Docs. Enfin, ce notebook peut accéder aux fichiers stockés dans Google Drive, par exemple si vous travaillez avec des jeux de données au format .csv.
Mais comment procéder pour partager à la fois les notebooks qui contiennent votre code et les fichiers qui contiennent les données ? C’est là où les choses se corsent (un peu). Et il y a plusieurs manières de procéder !
Durant leur formation chez DataScientest, nos étudiants réalisent un projet fil rouge destiné à mettre en pratique les compétences acquises à travers un cas mis en œuvre de A à Z. Ce projet est réalisé par équipe de 2, 3 ou 4, avec des membres qui sont généralement dispersés géographiquement. Pour mettre en place rapidement et efficacement ce travail collaboratif à distance, notre équipe pédagogique propose une masterclass qui pose les bases et aborde les différentes solutions possibles. Puis chaque équipe bénéficie d’un suivi personnalisé à travers des rendez-vous réguliers avec son mentor.
Dans cet article, nous revenons sur les clés pour bien démarrer avec Google Colab en équipe. Quels sont les trucs et astuces des mentors de DataScientest ? Y a-t-il des points de vigilance à avoir ? En moins de 7 minutes, vous allez avoir une vision claire des 3 scénarios recommandés pour tout paramétrer.
Au préalable, créez et partagez votre notebook
- Depuis votre dossier de travail dans Drive, cliquez sur “+ Nouveau” > Plus > Google Colaboratory (ou “Associer plus d’applications” s’il n’apparaît pas dans la liste) puis “Créer”.
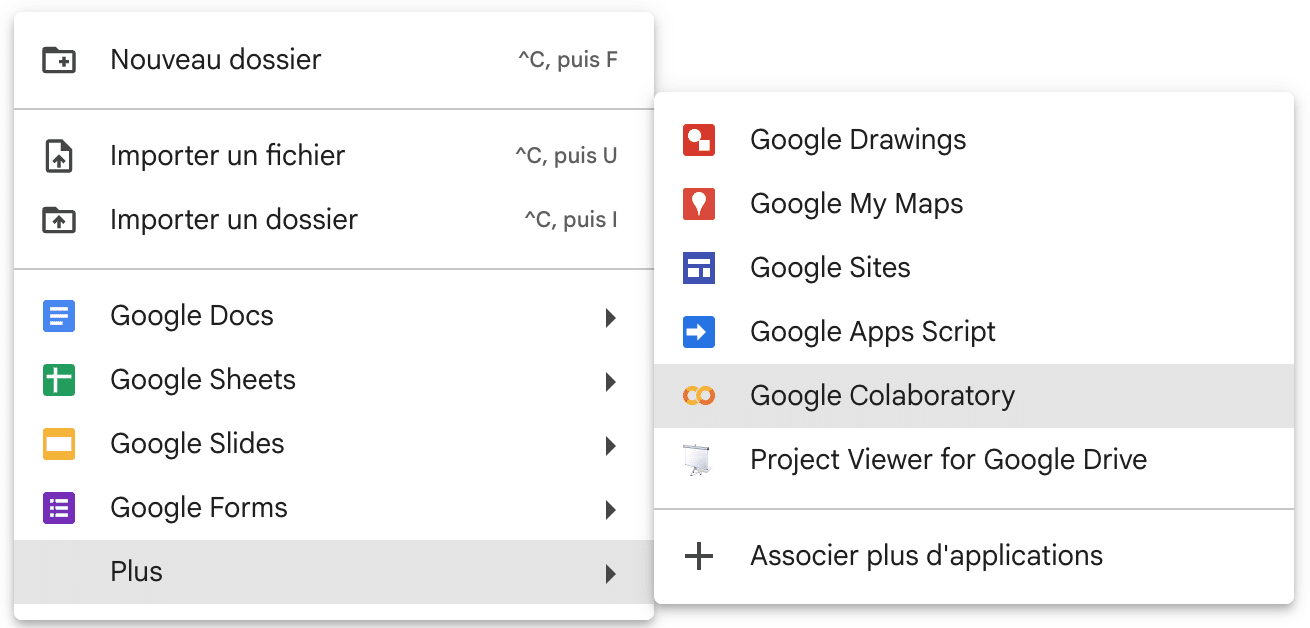
- Sinon, depuis la page https://colab.google, cliquez sur “New Notebook” (le fichier est stocké par défaut dans votre Drive dans un sous-dossier “Colab Notebooks”).
- Renommez le fichier, intitulé par défaut
Untitled0.ipynb. - Cliquez sur le bouton

et donnez accès à vos équipiers avec les droits d’éditeur.
⚠️ Avertissement : le notebook peut être exécuté par une seule personne à la fois.
Scénario 1 avec BytesIO et 1 fichier
Lucas recommande cette méthode en début de projet. Avec elle, le même fichier source peut être utilisé par toute l’équipe, le fichier peut être stocké dans n’importe quel compte, il suffit de le rendre public. Ainsi, chaque membre de l’équipe peut exécuter le notebook sans modifier la cellule de code qui charge le jeu de données.
import pandas as pd
from io import BytesIO
import requests
# Ceci est uniquement utilisé pour vous montrer où obtenir le file_id
original_link = "https://drive.google.com/file/d/1fRkXUdfLzTMkscHsAI8_NJuuDptwk02W/view?usp=drive_link"
# ID du fichier (à partir du lien partagé) (LE FICHIER DOIT ÊTRE PUBLIC)
file_id = "1fRkXUdfLzTMkscHsAI8_NJuuDptwk02W"
# Télécharger un fichier CSV depuis Google Drive
download_url = f"https://drive.google.com/uc?id={file_id}"
response = requests.get(download_url)
data = BytesIO(response.content)
# Charger le fichier CSV dans un DataFrame
df = pd.read_csv(data)
df.head()
🔗 Pour en savoir plus : consultez la documentation sur https://docs.python.org/3/library/io.html.
Scénario 2 avec gdown (Google Drive Public File Downloader) et 1 ou plusieurs fichiers
Alia propose régulièrement cette approche aux étudiants qu’elle mentore. La librairie gdown est spécifiquement conçue pour importer des fichiers depuis Google Drive. Là encore, avec cette méthode, le fichier source stocké sur Drive doit être rendu public. Astuce : le paramètre “quiet = True” supprime la sortie de progression pendant le téléchargement, le rendant moins verbeux.
# import de packages
import subprocess
import sys
import pandas as pd
# Ce code permet de s'assurer que gdown est bien installé.
# Si ce n'est pas le cas, il l'installe automatiquement.
# Cela évite des erreurs au moment de l'utiliser, surtout sur Colab où certaines bibliothèques ne sont pas déjà présentes.
try:
import gdown
except ImportError:
# Si gdown n'est pas installé, l'importer en utilisant pip
subprocess.check_call([sys.executable, "-m", "pip", "install", "gdown"])
# Remplacez l'ID par le vôtre (tout ce qui se trouve entre /d/ et /view)
# Par exemple avec https://drive.google.com/file/d/1ptwmJbk8ToMt4BvQeG5ni37IeNAOoAsb/view?usp=drive_link
file_id = '1ptwmJbk8ToMt4BvQeG5ni37IeNAOoAsb' # Remplacer par un fichier plus léger!
url= f'https://drive.google.com/uc?id={file_id}'
# Téléchargement du fichier csv
gdown.download(url, 'your_file_name.csv', quiet=True)
# Chargement du fichier csv dans un dataframe
df = pd.read_csv('your_file_name.csv')
df.head()
🗃️ Vous avez plusieurs fichiers à importer ? gdown permet aussi d’importer un dossier Drive et son contenu en bloc, avant d’ouvrir le ou les jeux de données qui vous intéressent.
import gdown
url = "https://drive.google.com/drive/folders/1HWFHKCprFzR7H7TYhrE-W7v4bz2Vc7Ia"
gdown.download_folder(url, quiet=True, use_cookies=False)
La sortie de code énumère alors les chemins d’accès de chacun des fichiers du dossier :
Output
['https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/special_general.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/remain_person.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/general.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/eunuch.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/civil_servant.csv']
On ouvre alors le fichier souhaité avec Pandas :
# Nous ouvrons le premier fichier avec pandas et vérifions les premières lignes
import pandas as pd
df = pd.read_csv('https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/special_general.csv')
df.head()
🔗 Pour en savoir plus : la documentation est accessible sur https://pypi.org/project/gdown et notre script reprend la démo proposée par Google Colab à la page https://colab.research.google.com/github/intodeeplearning/blog/blob/master/_notebooks/2022-05-08-how-to-download-files-in-gdrive-using-python.ipynb#scrollTo=I4vv49erlMC3
Scénario 3 avec un raccourci Drive pour des fichiers privés
Vos fichiers sources doivent rester privés ? Vous pouvez partager un notebook à votre équipe et l’exécuter à tour de rôle pour analyser un jeu de données partagé uniquement aux autres membres. Le mode opératoire qui suit vise à harmoniser le chemin d’accès aux fichiers, pour que chaque membre soit en mesure d’exécuter la même cellule d’importation des datasets en début de notebook.
Voyons ce que cela donne pour les utilisateurs A, B et C.
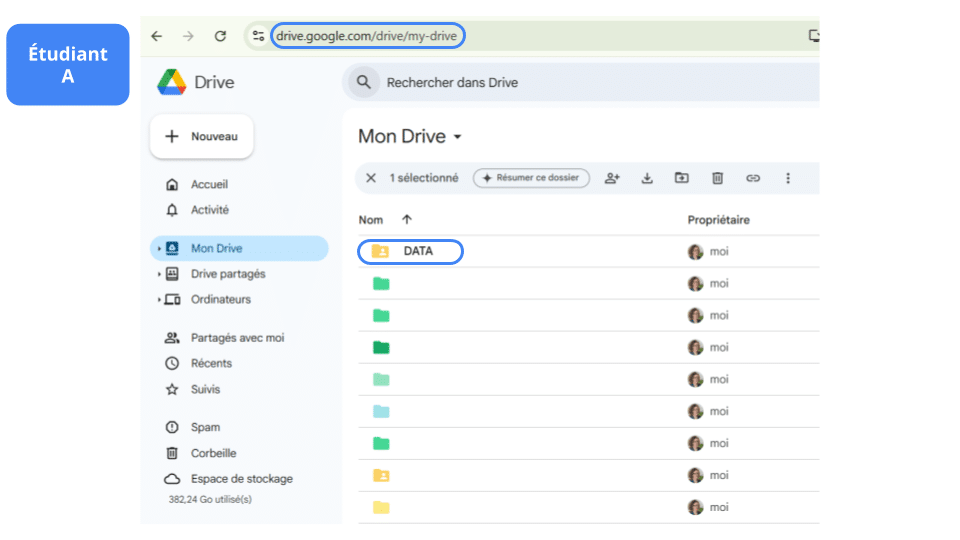
A dépose le jeu de données data.csv dans un dossier « Data » créé à la racine de son Drive et dont le chemin complet est le suivant :
python '/content/drive/My Drive/Data/dataset.csv'
A partage le dossier « Data » à ses camarades B et C.
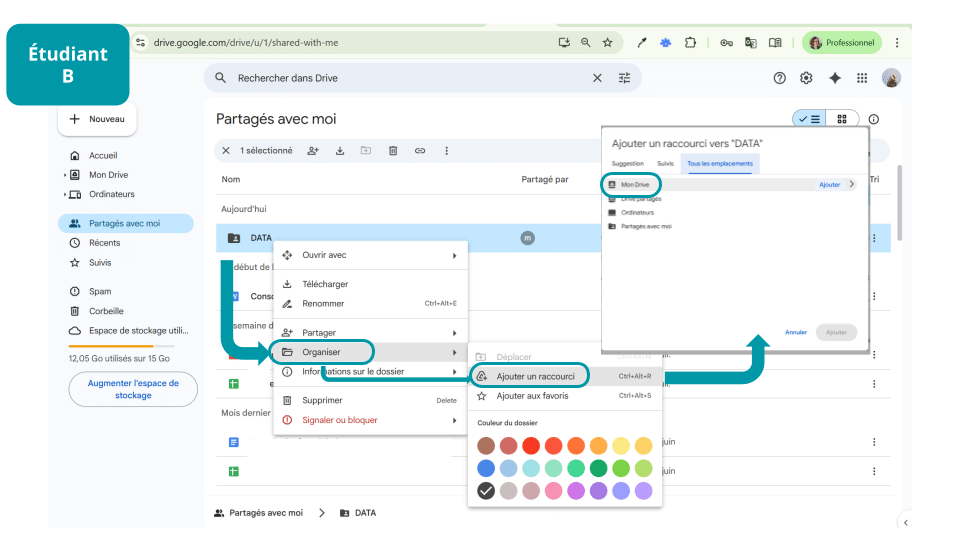
B et C chacun de leur côté, vont retrouver « Data » parmi leurs dossiers partagés, créer le raccourci vers « Data » (avec un clic droit) et le placer à la racine de leurs Drives respectifs (chacun dans « Mon Drive »).

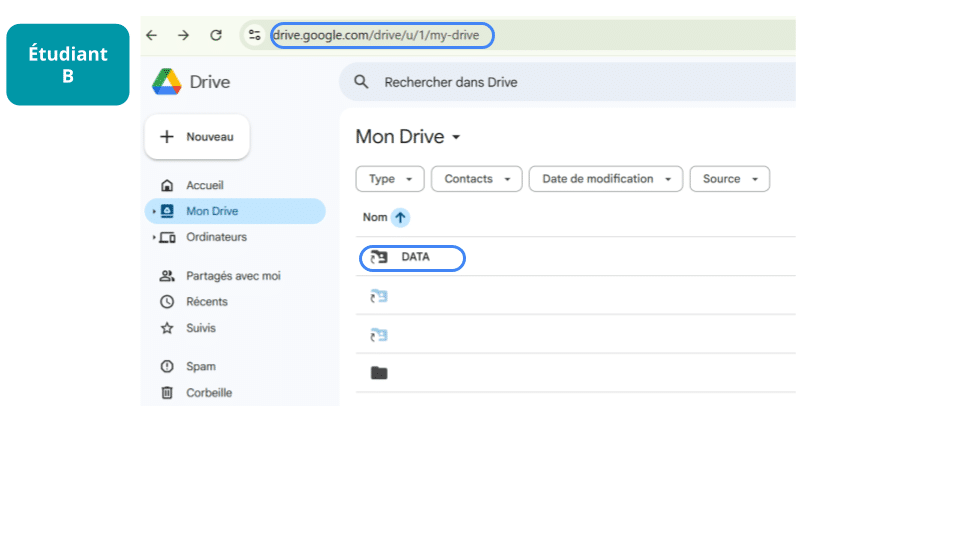
Ils peuvent alors utiliser le même chemin que A :
python '/content/drive/My Drive/Data/dataset.csv'
Le notebook comportera donc une cellule de code pour connecter Colab à Drive (chaque étudiant travaillant à tour de rôle devant connecter le notebook à son Drive) :
from google.colab import drive
drive.mount('/content/drive')
Puis la cellule suivante, à exécuter pour activer le chemin vers le fichier :
# File path for A, B, C
import pandas as pd
pathA='/content/drive/My Drive/Data/dataset.csv'
df = pd.read_csv(pathA)
En résumé
- Au démarrage d’un projet fil rouge, durant la phase d’exploration d’un jeu de données ouvertes (donc publiques), BytesIO offre la syntaxe la plus simple.
- En cours de projet gdown offre une solution plus intéressante pour nettoyer, combiner et transformer des données provenant de plusieurs fichiers issus d’un même dossier.
- Si les jeux de données doivent rester privés, la solution de contournement consiste à organiser le partage d’un unique dossier contenant tous les datasets, avec un raccourci identique pour tous les autres membres, de sorte à utiliser un chemin d’accès commun dans Colab.
Pour aller plus loin
- Google Colab : https://colab.google/
- Vidéo d’introduction à Google Colab (3 minutes) : https://www.youtube.com/watch?v=inN8seMm7UI&ab_channel=TensorFlow
[1]: Graphic Processing Unit
[2]: Tensor Processing Unit








