
Connaissez vous MPG ? C’est un jeu en ligne permettant à différents joueurs de s’affronter chaque week-end entre eux par l’intermédiaire d’équipes de football virtuelles, composées de joueurs réels issus de 5 championnats européens (Ligue 1, Ligue 2, Premier League, La Liga et la Serie A).
Au cours de sa formation Data Analyst en format Bootcamp au sein de DataScientest, Paul-André décide de choisir ce sujet pour son projet fil rouge. Un choix déterminant car il constitue ⅓ de la formation et donc du temps consacré tout au long du parcours à l’apprentissage de la Data Science. Nous l’avons interrogé pour en savoir plus sur ce projet ambitieux !
À vos marques, prêts , partez !
DataScientest : Pourquoi MPG ?
Paul-André: Passionné de sports en tout genre et plus particulièrement de football, je suis régulièrement les résultats sportifs des grands championnats européens ainsi que les divers dossiers d’actualités liés à ce secteur (transferts, réformes, blessures…).
J’ai découvert le jeu MPG par l’intermédiaire d’amis il y a 4 ou 5 ans. Je joue aujourd’hui de façon régulière dans différentes ligues, avec mes amis, mais également avec d’autres joueurs rencontrés sur des groupes Facebook liés à MPG.
L’objectif de ce projet est de faciliter les choix de joueurs à effectuer lors du recrutement de l’équipe (mercato) en fonction de différents paramètres, puis de les aider à déterminer la meilleure équipe à aligner avant chaque rencontre afin de maximiser leurs chances de victoire.
Ce travail peut donc servir à des joueurs MPG, débutants ou non, mais également à toute personne aimant les statistiques sportives et/ou l’analyse de données de façon générale.
DST: Quelles ont été les étapes clés du projet ?
P-A : Dans un premier temps la récupération des données : Afin de récupérer un certain nombre de données, j’ai tout d’abord cibler le site mpgstats fournissant un nombre intéressant de statistiques sur la performance des joueurs sur le terrain. Cependant j’ai rencontré divers problèmes avec ce site, notamment une disparition inattendue de l’ensemble des données entre les deux saisons, ce qui m’a amené à revoir ma stratégie d’acquisition des données. Après de nombreuses recherches, je me suis finalement orienté vers footystats, payant quant à lui, afin de récupérer divers données sur la performance des joueurs en fonction de leurs championnats au format csv.
Cela illustre déjà un des problèmes liés à ce projet et à la statistique sportive en général. Il est en effet difficile de trouver des statistiques récentes, complètes et détaillées pour plusieurs championnats. J’ai ensuite réalisé un « Scraping » de 5 pages du site MPG.

P-A : Le plus difficile, et le plus chronophage, a ensuite été de mettre en relation ces deux DataSets afin de ne former plus qu’une seule base de données. En effet, les noms des joueurs n’ont pas été écrits de la même façon sur les deux DataSets (Nom et Prénom inversé, accent non présent, noms raccourcis …). Il m’a donc fallu créer une « table de correspondance » en grande partie manuellement afin de créer le DataSet final.
Une fois ce jeu de données créé, j’ai pu commencer par réaliser diverses visualisations pour découvrir ou confirmer les liens existants entre les différentes données. Les critères principaux que j’ai retenus pour cette analyses sont :
- Le nombre de buts marqués
- Le nombre de buts concédés
- Le nombre de passes décisives
- Le nombre de « clean sheets »
- La côte des joueurs
- Le poste des joueurs
- Les performances domicile/extérieur
- L’équipe et le championnat du joueur
Afin de visualiser plus facilement le rôle de certaines données, j’ai également rajouté plusieurs variables comme la différence entre la moyenne des buts concédés à domicile et à l’extérieur pour chaque joueur ou bien encore la différence entre les buts marqués à domicile et ceux marqués à l’extérieur ainsi que la relation entre nombre de buts marqués et côte du joueur.
Après avoir nettoyé le jeu de données et après avoir rajouté un certains nombres de variables explicatives, j’ai réalisé plusieurs visualisation à l’aide de Matplotlib et Seaborn (voir exemple ci-dessous).
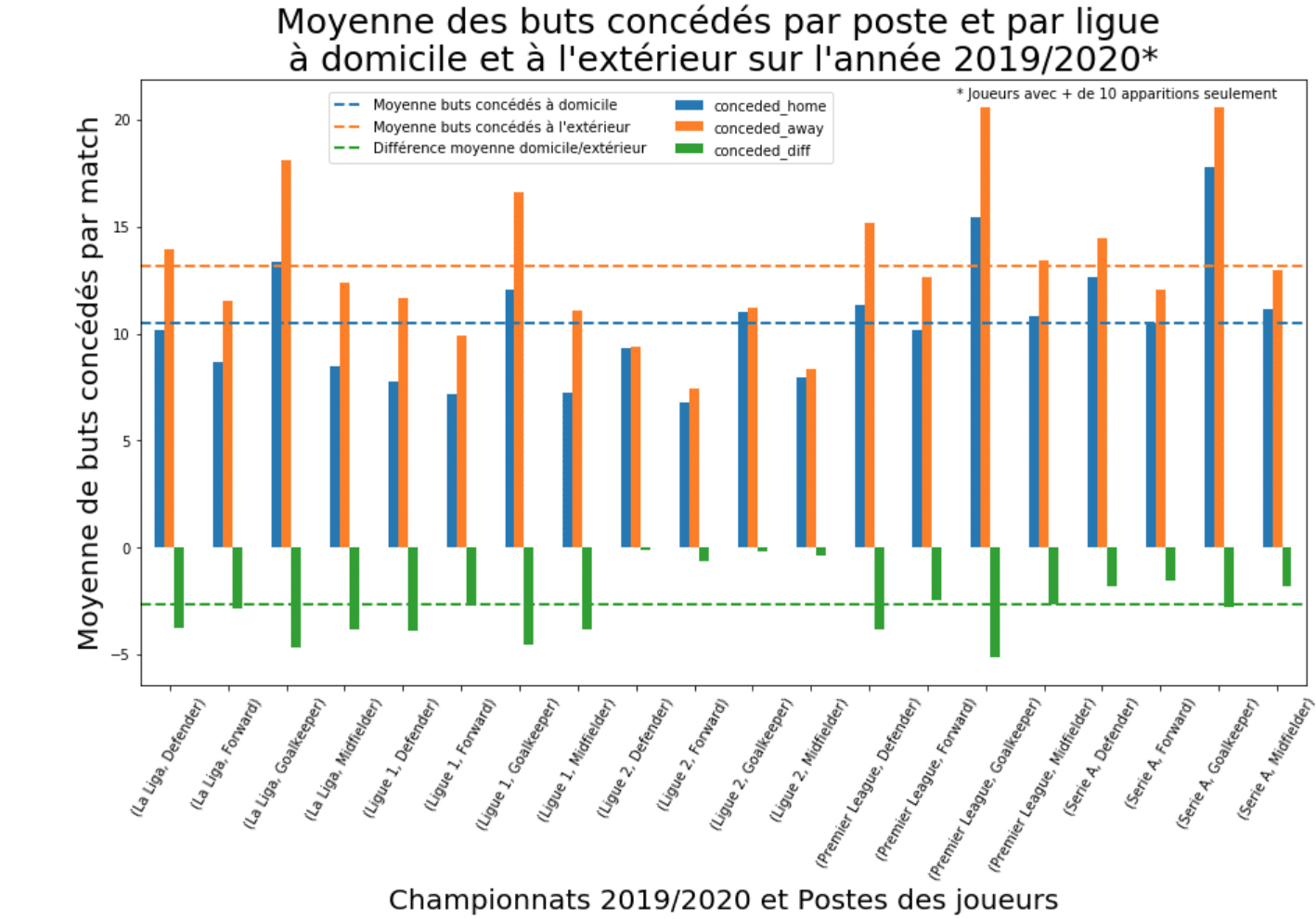
J’ai ensuite commencé à modéliser différentes régressions linéaires qui montrent la corrélation positive entre plusieurs couples de variables. Comme nous pouvons le voir sur un extrait de l’analyse ci-dessous, plusieurs paramètres sont directement liés à l’augmentation de la côte d’un joueur. C’est notamment le cas pour le nombre de buts marqués et les passes décisives de chaque joueur. Plus l’ensemble de ces paramètres est élevé, plus la cote du joueur est élevée. Si cette observation se vérifie globalement pour l’ensemble des championnats, l’analyse montre par exemple que l’intensité de la corrélation diffère selon les critères et les championnats.

L’ensemble de ces analyses permettent aux joueurs de mieux appréhender les spécificités entre les différents championnats.
De plus, ce travail peut également faciliter le travail de composition des joueurs plus expérimentés en prouvant de façon mathématique qu’un joueur A aura plus de chance d’être performant qu’un joueur B.
Si le choix de la composition d’équipe se fait souvent en se basant uniquement sur un jugement personnel de connaissance des joueurs, associer des preuves tangibles à son ressenti grâce à l’analyse de données permet de justifier sa stratégie de façon plus concrète et d’envisager plus sereinement la prochaine rencontre !
DST: Quelle suite à ce projet ? Quelles en seraient les améliorations possibles ?
Le premier défi à relever pour améliorer ce projet se trouve dans la stratégie d’acquisition des données. Il faudrait en effet trouver un moyen d’obtenir des données fiables sur l’ensemble des championnats du jeu MPG, de façon automatisé et régulière afin de proposer des analyses pertinentes après chaque journée. Un tel flux de données pourrait permettre de personnaliser l’expérience selon le joueur et donc ainsi proposer un plus grand nombre d’analyses sous forme de graphique, d’historiques de données et de statistiques par équipe avant chaque rencontre.
P-A : Le deuxième défi serait de trouver un moyen de communiquer les données à tous sans que l’utilisateur ne nécessite une installation quelconque. Un site internet relié à une API représenterait l’aboutissement de ce projet mais cela nécessite des compétences supplémentaires, notamment en développement web, un peu d’investissement et surtout du temps pour le réaliser. C’est un projet que je garde dans le coin de ma tête pour le jour où ces trois conditions seront réunies.
DST: Si tu devais résumer ton parcours (la relation avec l’équipe pédago, ton apprentissage) en un mot ? Et ton projet ?
Si je devais résumer mon parcours en un mot j’utiliserais le mot « cohérent ». En effet j’ai trouvé l’enchaînement des modules relativement logique et pertinent.
Même si j’ai bien conscience qu’il me reste des choses à apprendre en accumulant plus d’heures de pratique, je trouve que la formation Data Analyst donne toutes les bases pour s’orienter vers un poste à l’issue.
Il faut néanmoins avoir une certaine rigueur et une bonne organisation afin de concilier les cours et le projet mais aussi afin d’anticiper au mieux les potentiels imprévus associés, comme ce fut le cas lors de ma formation. Je ne regrette absolument pas mon choix du format « bootcamp » mais c’est un choix que tout futur étudiant doit faire en ayant bien conscience de ses capacités et de sa disponibilité.
Concernant mon projet, j’utiliserais assez logiquement le mot « formateur », puisqu’il permet d’allier la théorie à la pratique.
En plus d’être un bon entraînement, le projet permet à la fois d’avoir un début de portfolio à présenter lors d’un entretien mais également de repérer ses difficultés et donc d’identifier ses axes d’amélioration pour la suite. Avoir une bonne organisation en revanche est primordial pour concilier cours et projet sans se laisser submerger.
Vous souhaitez démarrer un bootcamp de Data Analyst ? Réaliser un projet data en étant guidé par des Data Scientists experts ?
Vous souhaitez discutez du projet avec Paul-André ? Vous pouvez le contacter directement sur Linkedin.








