
Hadoop est un framework Open Source dédié au stockage et au traitement du Big Data. Découvrez tout ce que vous devez savoir : définition, histoire, fonctionnement, avantages, formations...
Durant plusieurs décennies, les entreprises stockaient principalement leurs données sur des bases de données relationnelles (RDBMS) afin de les stocker et d’effectuer des requêtes. Toutefois, ce type de base de données ne permet pas de stocker les données non structurées et n’est pas non plus adapté aux vastes volumes du Big Data.
En effet, la digitalisation et l’apparition de nombreuses technologies comme l’IoT et les smartphones ont provoqué une explosion du volume de données brutes. Face à cette révolution, de nouvelles technologies sont nécessaires pour le stockage et le traitement de données. Le framework logiciel Hadoop permet de répondre à ces contraintes nouvelles.
Qu'est-ce que Hadoop ?
Hadoop est un framework logiciel dédié au stockage et au traitement de larges volumes de données. Il s’agit d’un projet open source, sponsorisé par la fondation Apache Software Foundation.
Il ne s’agit pas d’un produit à proprement parler, mais d’un framework regroupant des instructions pour le stockage et le traitement de données distribuées. Différents éditeurs de logiciels ont utilisé Hadoop pour créer des produits commerciaux de gestion Big Data.
Les systèmes de données Hadoop ne sont pas limités en termes d’échelle, ce qui signifie qu’il est possible d’ajouter davantage de hardware et de clusters pour supporter une charge plus lourde sans passer par une reconfiguration ou l’achat de licences logicielles onéreuses.
L'histoire de Hadoop
L’origine de Hadoop est étroitement liée à la croissance exponentielle du » World Wide Web « au fil de la précédente décennie. La toile s’est agrandie, et rassemble désormais plusieurs milliards de pages. Par conséquent, il est devenu difficile de chercher efficacement des informations.
Nous sommes entrés dans l’ère du Big Data. Il est devenu plus complexe de stocker des informations de façon efficace pour les retrouver facilement, et de traiter les données après les avoir stockées.
Pour remédier à ce problème, de nombreux projets open source ont été développés. L’objectif était de proposer plus rapidement les résultats de recherche sur le web. L’une des solutions adoptées était de distribuer les données et les calculs sur une grappe de serveurs pour permettre le traitement simultané.
C’est ainsi qu’Hadoop a vu le jour. En 2002, Doug Cutting et Mike Caferella de Google travaillaient sur le projet de web crawler open source Apache Nutch. Ils ont été confrontés à des difficultés pour stocker les données, et les coûts étaient extrêmement élevés.
En 2003, Google présente son système fichier GFS : Google File System. Il s’agit d’un système fichier distribué conçu pour fournir un accès efficace aux données. La firme américaine publie en 2004 un livre blanc sur Map Reduce, l’algorithme permettant de simplifier le traitement de données sur de larges clusters. Ces publications de Google ont fortement influencé la genèse de Hadoop.
Par la suite en 2005, Cutting et Cafarella dévoilent leur nouveau système fichier NDFS (Nutch Distributed File System) incluant aussi Map Reduce. Lorsqu’il quitte Google pour joindre Yahoo en 2006, Doug Cutting se base sur le projet Nutch pour lancer Hadoop (dont le nom est inspiré par un éléphant en peluche du fils de Cutting) et son système fichier HDFS. La version 0.1.0 est relaxée.
Par la suite, Hadoop ne cesse de se développer. Il devient en 2008 le système le plus rapide à trier un terabyte de données sur un cluster de 900 noeuds en seulement 209 secondes. La version 2.2 est lancée en 2013, et la version 3.0 en 2017.
En plus de ses performances pour le Big Data, ce framework a apporté de nombreux avantages inattendus. Il a notamment fait chuter le coût du déploiement de serveurs.
Quels sont les quatre modules de Apache Hadoop ?
Apache Hadoop repose sur quatre principaux modules. Tout d’abord, le Hadoop Distributed File System (HDFS) est utilisé pour le stockage de données. Il est comparable à un système de fichier local sur un ordinateur classique.
Toutefois, ses performances sont nettement supérieures. Le HDFS délivre par ailleurs une excellente élasticité. Il est possible de passer d’une machine unique à plusieurs milliers d’entre elles très facilement.
Le second composant est le YARN (Yet Another Resource Negotiator). Comme son nom l’indique, il s’agit d’un négociateur de ressources. Il permet de planifier des tâches, de gérer les ressources et de surveiller les noeuds de clusters et les autres ressources.
De son côté, le module Hadoop MapReduce aide les programmes à effectuer des calculs parallèles. La tâche Map convertit les données en paires clés-valeurs. La tâche Reduce consomme les données d’entrée, les agrège et produit le résultat.
Le dernier module est Hadoop Common. Il utilise des bibliothèques Java standards entre chaque module.
Comment Hadoop permet le traitement du Big Data ?
Le traitement du Big Data par Hadoop repose sur l’utilisation de la capacité de stockage et de traitement distribué de clusters. Il s’agit d’une base pour la création d’applications Big Data.
Les applications peuvent collecter des données de différents formats et les stocker dans le cluster Hadoop par le biais d’une API se connectant au NameNode. Le NameNode capture la structure du dossier de fichiers, et réplique des morceaux entre les différents DataNodes pour le traitement parallèle.
Les requêtes de données sont effectuées par MapReduce, qui répertorie aussi tous les DataNodes et réduit les tâches liées aux données dans le HDFS. Les tâches Map sont effectuées sur chaque noeud, et les réducteurs sont exécutés pour lier les données et organiser le résultat final.
Quels sont les différents outils de l'écosystème Hadoop ?
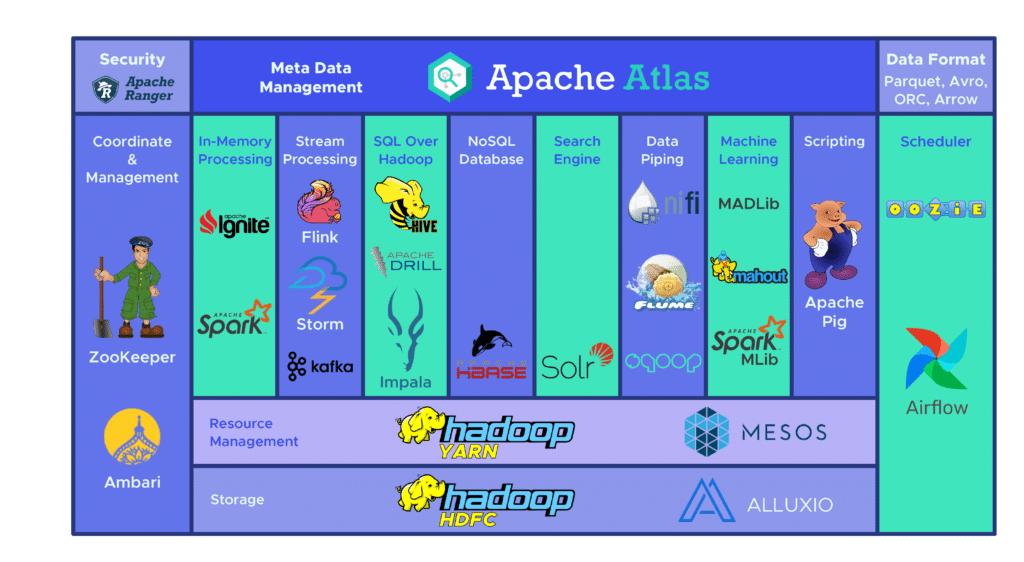
L’écosystème Hadoop regroupe une large variété d’outils Big Data open source. Ces divers outils complémentent Hadoop et améliorent sa capacité de traitement Big Data.
Parmi les plus populaires, Apache Hive est une Data Warehouse dédiée au traitement de larges ensembles de données stockés dans le HDFS. L’outil Zookeeper automatise les basculements et réduit l’impact d’une panne de NameNode.
De son côté, HBase est une base de données non relationnelle pour Hadoop. Le service distribué Apache Flume permet le streaming de données de larges quantités de données de log.
Citons aussi Apache Sqoop, un outil de ligne de commande permettant la migration de données entre Hadoop et les bases de données relationnelles. La plateforme de développement Apache Pig permet le développement de jobs à exécuter sur Hadoop.
Le système de planification Apache Oozie facilite la gestion des jobs Hadoop. Enfin, HCatalog est un outil de gestion de tableau pour trier les données en provenance de divers systèmes de traitement.
Quels sont les avantages de Hadoop ?
Les avantages de Hadoop sont nombreux. Ce framework permet tout d’abord un stockage et un traitement plus rapides de vastes volumes de données. Il s’agit d’un précieux atout à l’ère des réseaux sociaux et de l’Internet des Objets.
Par ailleurs, Hadoop offre une flexibilité permettant de stocker des données non structurées en tout genre telles que des textes, des symboles, des images ou des vidéos. Contrairement à une base de données relationnelle traditionnelle, les données peuvent être stockées sans être traitées au préalable. Le fonctionnement est donc comparable à une base de données NoSQL.
En outre, Hadoop apporte aussi une importante puissance de traitement. Son modèle de calcul distribué offre performances et efficacité.
Ce framework open source permet aussi de s’attaquer au Big Data à moindre coût, puisqu’il peut être utilisé gratuitement et librement. Il repose par ailleurs sur du hardware très commun pour stocker les données.
Un autre avantage majeur est l’élasticité. Il suffit de changer le nombre de noeuds dans un cluster pour étendre ou réduire le système.
Enfin, Hadoop ne dépend pas du hardware pour préserver la disponibilité des données. Ces dernières sont automatiquement copiées plusieurs fois sur différents noeuds du cluster. Si un appareil tombe en panne, le système redirige automatiquement la tâche vers un autre. Le framework est donc tolérant aux pannes et aux erreurs.
Quels sont les points faibles de Hadoop ?
Malgré tous ses points forts, Hadoop présente aussi des faiblesses. Tout d’abord, l’algorithme MapReduce n’est pas toujours adéquat. Il convient pour les requêtes d’informations les plus simples, mais pas pour les tâches itératives. Il n’est pas non plus efficace pour le calcul analytique avancé, puisque les algorithmes itératifs requièrent une intercommunication intensive.
Pour le Data Management, les métadonnées et la gouvernance de données, Hadoop n’offre pas d’outils adaptés et compréhensibles. On déplore aussi le manque d’outils pour la standardisation des données et la détermination de qualité.
Un autre problème est qu’Hadoop est difficile à maîtriser. Il y a donc peu de programmeurs suffisamment compétents pour utiliser MapReduce. C’est la raison pour laquelle beaucoup de fournisseurs ajoutent une technologie de base de données SQL par dessus Hadoop. Les programmeurs maîtrisant SQL sont nettement plus nombreux.
Dernier point faible : la sécurité des données. Le protocole d’authentification Kerberos aide toutefois à sécuriser les environnements Hadoop.
Quels sont les cas d'usage de Hadoop ?
Hadoop offre de multiples possibilités. L’un de ses principaux cas d’usage est le traitement du Big Data. Ce framework est en effet adapté pour le traitement de vastes volumes de données, de l’ordre de plusieurs petabytes.
De tels volumes d’informations requièrent énormément de puissance de traitement, et Hadoop est la solution adéquate. Une entreprise devant traiter de plus petits volumes, de l’ordre de quelques centaines de gigabytes, pourra en revanche se contenter d’une solution alternative.
Un autre cas d’usage majeur de Hadoop est le stockage de données diverses. La flexibilité de ce framework permet de prendre en charge de nombreux types de données différents. Il est possible de stocker des textes, des images, ou même des vidéos. La nature du traitement de données peut être sélectionnée en fonction des besoins. On retrouve ainsi la flexibilité d’un Data Lake.
En outre, Hadoop est utilisé pour le traitement parallèle des données. L’algorithme MapReduce permet d’orchestrer le traitement parallèle des données stockées. Cela signifie que plusieurs tâches peuvent être effectuées simultanément.
Comment les entreprises utilisent-elles Hadoop ?
Des entreprises de toutes les industries utilisent Hadoop pour le traitement du Big Data. Le framework permet par exemple de comprendre les besoins et les attentes des clients.
De grandes entreprises des industries de la finance et des réseaux sociaux utilisent cette technologie pour comprendre les attentes des consommateurs en analysant le Big Data sur leur activité, sur leur comportement.
À partir de ces données, il est possible de proposer des offres personnalisées aux clients. C’est tout le principe de la publicité ciblée sur les réseaux sociaux ou des moteurs de recommandation sur les plateformes de e-commerce.
Par ailleurs, Hadoop permet aussi d’optimiser les processus de l’entreprise. À partir des données de transaction et celles des clients, l’analyse de tendance et l’analyse prédictive aide les entreprises à personnaliser leurs produits et leurs stocks pour accroître les ventes.
Ceci permet de prendre de meilleures décisions et générer des profits plus importants. En analysant les données sur le comportement et les interactions des employés, il est aussi possible d’améliorer l’environnement de travail.
Dans l’industrie de la santé, les institutions médicales peuvent utiliser Hadoop pour surveiller la vaste quantité de données liées aux problèmes de santé et aux résultats des traitements médicaux. Les chercheurs peuvent analyser ces données afin d’identifier des problèmes de santé et choisir des traitements adéquats.
Les traders et le monde de la finance utilisent aussi Hadoop. Son algorithme permet de scanner les données de marché pour identifier des opportunités et des tendances saisonnières. Les entreprises de la finance peuvent automatiser les opérations grâce au framework.
Par ailleurs, Hadoop est utilisé pour l’Internet des Objets. Ces appareils requièrent des données pour fonctionner correctement. Les fabricants utilisent donc Hadoop en guise de Data Warehouse pour stocker les milliards de transactions enregistrées par l’IoT. Le streaming de données peut ainsi être géré correctement.
Il ne s’agit là que de quelques exemples. En outre, Hadoop est utilisé dans le domaine du sport et de la recherche scientifique.
Comment apprendre à utiliser Hadoop ? Les formations DataScientest
En résumé, Hadoop est très utile pour le traitement du Big Data lorsqu’il implémenté et utilisé correctement. Cet outil versatile et polyvalent est idéal pour les entreprises confrontées à de larges volumes de données.
Dans ce contexte, apprendre à maîtriser Hadoop peut être très utile. Vos compétences seront très recherchées par de nombreuses organisations de tous les secteurs d’activité, et vous pourrez donc facilement trouver un emploi bien rémunéré.
Si vous êtes chef d’entreprise, vous pouvez aussi financer la formation à Hadoop pour vos employés. Ils pourront ainsi manipuler le Big Data et saisir toutes les opportunités offertes.
La formation Data Engineer de DataScientest propose d’apprendre à maîtriser Hadoop, et tous les outils et techniques d’ingénierie des données. Le programme est divisé en cinq modules : programmation, base de données, Big Data Volume, Big Data Vitesse, et automatisation et déploiement.
Au fil du cursus, les apprenants découvriront Hadoop, mais aussi Hive, Hbase, Pig, Spark, Bash, Cassandra, le SQL ou encore Kafka. À l’issue de la formation, un diplôme de Data Engineer certifié par l’Université de la Sorbonne est décerné.
Ce parcours permet de se former au métier d’ingénieur des données. Parmi les alumnis, 93% ont trouvé un emploi immédiatement après l’obtention du diplôme. Les compétences acquises peuvent être utilisées directement en entreprise.
Le programme peut être complété en 9 mois en formation continue, ou 11 semaines en Formation Continue. Toutes nos formations adoptent une approche hybride innovante de Blended Learning, mariant apprentissage en présentiel et distanciel.
Le prix de la formation s’élève à 5000€, avec possibilité de payer en plusieurs fois. Le cursus est éligible au CPF (compte professionnel de formation) et peut être financé par le Pôle Emploi via l’AIF.
Vous savez tout sur Hadoop. Découvrez notre dossier complet sur l’Open Source, et notre introduction à la Data Warehouse.








