
Apache Pig est le langage de programmation permettant d'utiliser Hadoop et MapReduce. Découvrez tout ce que vous devez savoir : présentation, cas d'usage, avantage, formations...
Le modèle de programmation MapReduce du framework Apache Hadoop permet de traiter de larges volumes de données Big Data. Toutefois, les Data Analysts ne maîtrisent pas toujours ce paradigme. C’est la raison pour laquelle une abstraction appelée Pig a été ajoutée à Hadoop.
Qu'est-ce que Apache Pig ?
Le langage de programmation de haut niveau Apache Pig est très utile pour analyser de larges ensembles de données. Il fut initialement développé en interne par Yahoo ! en 2006, dans le but de créer et d’exécuter des jobs MapReduce sur tous les datasets.
Le nom » Pig » a été choisi, car ce langage de programmation est conçu pour fonctionner sur n’importe quel type de données à l’instar d’un cochon qui dévore tout et n’importe quoi.
En 2007, Pig est rendu Open Source par le biais de l’incubateur Apache. En 2008, la première version de Apache Pig est lancée. Le succès est au rendez-vous, et Pig devient un projet Apache de premier niveau en 2010.
En utilisant Apache Pig, les Data Analysts peuvent passer moins de temps à écrire des programmes MapReduce. Ils peuvent ainsi rester focalisés sur l’analyse d’ensembles de données.
Ainsi, Apache Pig est une abstraction pour MapReduce. Cet outil est utilisé pour analyser les vastes datasets en les représentant comme des flux de données. Toutes les opérations de manipulation de données sur Hadoop peuvent être effectuées en utilisant Apache Pig.
L'architecture Apache Pig
L’architecture Apache Pig repose sur deux composants principaux : le langage Pig Latin et l’environnement runtime permettant l’exécution des programmes PigLatin.
Le langage Pig Latin permet d’écrire des programmes d’analyse de données. Il délivre divers opérateurs que les programmeurs peuvent utiliser pour développer leurs propres fonctions pour lire, écrire ou traiter des données.
Un programme Pig Latin est composé d’une série de transformations ou d’opérations, appliquées aux données » input » (entrée) pour produire un » output « . Ces opérations décrivent un flux de données traduit en une représentation exécutable par l’environnement d’exécution Hadoop Pig.
Pour analyser des données en utilisant Apache Pig, les programmeurs doivent impérativement écrire des scripts avec le langage Pig Latin. Tous ces scripts sont convertis en tâches Map et Reduce de façon interne. Le composant Pig Engine se charge de convertir les scripts en jobs MapReduce.
Toutefois, le programmeur n’a même pas connaissance de ces jobs. C’est ainsi que Pig permet aux programmeurs de se concentrer sur les données plutôt que sur la nature de l’exécution.
On distingue deux modes d’exécution pour Pig. Le mode Local s’exécute sur un JVM unique et utilise le système de fichier local. Ce mode est adapté pour l’analyse de petits ensembles de données.
En mode Map Reduce, les requêtes écrites en Pig Latin sont traduites en jobs MapReduce et exécutées sur un cluster Hadoop. Ce dernier peut être partiellement ou entièrement distribué. Le mode MapReduce combiné avec un cluster entièrement distribué est utile pour exécuter Pig sur de larges ensembles de données.
Pourquoi utiliser Apache Pig ?
Par le passé, les programmeurs ne maîtrisant pas Java avaient du mal à utiliser Hadoop. Il était particulièrement délicat pour eux d’effectuer des tâches MapReduce.
Ce problème a pu être résolu grâce à Apache Pig. En utilisant le langage Pig Latin, les programmeurs peuvent effectuer facilement des tâches MapReduce sans avoir à taper des codes complexes en Java.
Par ailleurs, Apache Pig repose sur une approche » multi-requête « permettant de réduire la longueur des codes. Une opération qui nécessiterait 200 lignes de code en Java peut être réduire à seulement 10 linges avec Pig. En moyenne, Apache Pig divise le temps de développement par 16.
Un avantage du langage Pig Latin est qu’il est relativement proche du langage SQL. Une personne accoutumée à SQL maîtrisera facilement Pig.
Enfin, de nombreux opérateurs sont fournis nativement. Ils permettent de prendre en charge les diverses opérations de données. L’outil offre aussi des types de données comme les tuples, les bags et les maps manquant à MapReduce.
Les applications de Apache Pig
En règle générale, Apache Pig est utilisé par les Data Scientists pour effectuer des tâches impliquant le traitement Hadoop et le prototypage rapide. On l’utilise notamment pour traiter d’immenses sources de données comme les logs web.
Cet outil permet aussi le traitement de données pour les plateformes de recherche. Enfin, il permet de traiter les charges de données sensibles au temps.
Les caractéristiques et points forts de Apache Pig
Voici les principales caractéristiques et fonctionnalités Apache Pig. Le langage de programmation Pïg Latin, similaire à SQL, permet d’écrire un script Pig facilement.
Un vaste ensemble d’opérateurs permet d’effectuer une large variété d’opérations de données. À partir de ces opérateurs, les utilisateurs peuvent développer leurs propres fonctions pour lire, traiter et écrire les données.
Il est aussi possible de créer des UDF (user-defined functions) ou fonctions définies par l’utilisateur dans d’autres langages de programmation comme Java. Elles peuvent ensuite être invoquées ou intégrées à des scripts Pig.
En outre, les tâches Apache Pig optimisent automatiquement leur exécution. Les programmeurs peuvent donc se focaliser uniquement sur la sémantique du langage.
Avec Apache Pig, il est possible d’analyser tous les types de données structurés ou non. Les résultats des analyses sont stockés dans le HDFS de Apache Hadoop.

Apache Pig vs MapReduce
Il existe plusieurs différences majeures entre Apache Pig et MapReduce. Tout d’abord, MapReduce est un paradigme de traitement de données tandis que Pig est un langage de flux de données.
C’est un langage de haut niveau, alors que MapReduce est de bas niveau. Il est difficile d’effectuer une opération de Joint entre des datasets avec MapReduce, alors que c’est une tâche facile avec Pig.
N’importe quel programmeur disposant de notions en SQL peut travailler avec Apache Pig, tandis que MapReduce requiert la maîtrise du Java.
Une autre différence concerne la longueur des lignes de code. Grâce à son approche multi-requête, Apache Pig requiert 20 fois moins de lignes que MapReduce pour effectuer une même tâche.
Enfin, les tâches Mapreduce impliquent un long processus de compilation. Il n’y a pas besoin de compilation avec Pig, car chaque opérateur est converti en interne en job MapReduce à l’exécution.
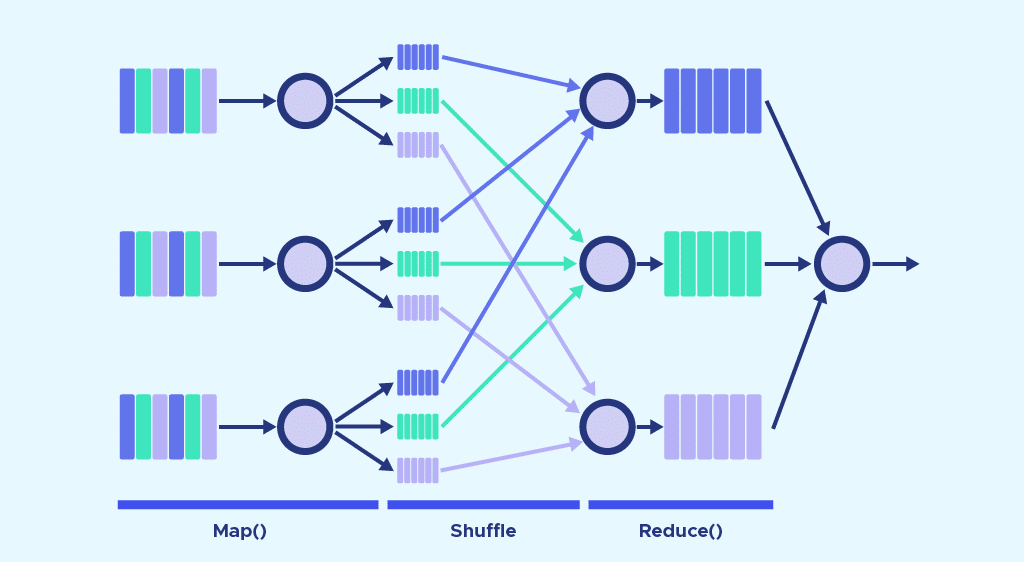
Apache Pig vs SQL
Apache Pig présente des similitudes avec SQL, mais aussi des différences. Alors que Pig Latin est un langage procédural, SQL est un langage déclaratif.
En outre, un schéma est obligatoire en SQL alors qu’il est optionnel avec Pig. Il est possible de stocker des données sans concevoir de schéma.
Il y a davantage d’opportunités d’optimisation de requête avec SQL, alors qu’elles sont plus limitées avec Pig. Par ailleurs, Pig Latin permet de décomposer un pipeline, de stocker des données n’importe où dans le pipeline et permet d’effectuer des fonctions ETL (Extraction, Transformation, Chargement).
Apache Pig vs Hive

Apache Pig fut créé par Yahoo, et Hive par Facebook. Le premier utilise le langage Pig Latin, le second le langage HiveQL.
Alors que Pig Latin est un langage de flux de données et un langage procédural. HiveQL est un langage de traitement de requête et un langage déclaratif.
Enfin, Hive prend principalement en charge des données structurées. De son côté, Pig peut prendre en charge les données structurées, non structurées et semi-structurées.
Comment apprendre à utiliser Apache Pig ?
Alors que de plus en plus d’entreprises utilisent le Big Data, la maîtrise d’Apache Pig est une compétence très recherchée. Elle est très utile pour traiter et analyser facilement de larges ensembles de données avec Hadoop.
Pour apprendre à manier cet outil, vous pouvez choisir les formations DataScientest. Le framework Apache Hadoop, et ses différents composants comme Pig, Hive, Spark et HBase sont au programme du module Big Data Volume de la formation Data Engineer.
Les autres modules de ce parcours sont la programmation, les bases de données, l’automatisation et le déploiement. À l’issue de ce parcours, vous aurez toutes les compétences pour travailler en tant qu’ingénieur des données.
Toutes nos formations sont proposées en Formation Continue, ou en bootcamp. Notre approche innovante de » Blended Learning » allie apprentissage en présentiel et en ligne à distance.
Les apprenants reçoivent un diplôme certifié par l’Université de la Sorbonne., et 93% des alumnis ont trouvé un emploi immédiatement. N’attendez plus et découvrez la formation Data Engineer.
Vous savez tout sur Apache Pig. Découvrez notre dossier complet sur Hadoop, et notre introduction au langage SQL.









