
Qu’est-ce que Apache Storm ?
Apache Storm est un système de traitement de flux de données en temps réel distribué open-source, et développé principalement en Clojure. Il permet de gérer les flux de données en continu. Storm est aujourd’hui très utilisé dans le cadre des réseaux sociaux, des jeux en ligne ou encore dans les systèmes de surveillance industrielle.
Apache Storm a initialement été développé par Nathan Marz pour la startup Backtype qui a été rachetée par Twitter.
Storm met un poing d’honneur à rester le plus simple possible, ce qui permet aux développeurs de créer des topologies avec n’importe quel langage de programmation. En effet, le développement sur Storm passe par la manipulation de tuples (pour rappel, un tuple est une liste nommée de valeurs).
Ces tuples peuvent contenir n’importe quel type d’objets, et quand bien même Apache Storm ne connaît pas le type, il est facilement possible de mettre en place un sérialiseur.
Comment se structure Apache Storm ?
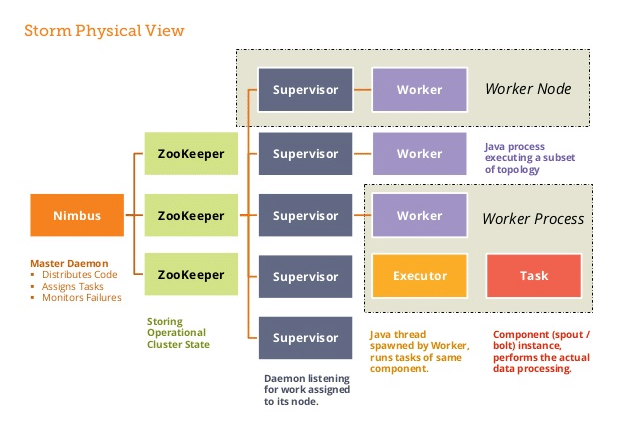
Apache Storm utilise une architecture « maître – esclave » avec les composants suivants :
- Nimbus : Il s’agit du nœud maître, responsable de la distribution du code entre les superviseurs, de l’attribution des ensembles de données d’entrée aux machines pour le traitement et la surveillance des pannes.
- Zookeeper : Coordonne et gère les processus de distribution de données.
- Superviseurs : Services exécutés sur chaque nœud worker, qui gèrent les processus de travail et suivent leur exécution.
- Workers : Sont les processus multiples ou uniques sur chaque nœud démarrés par les superviseurs. Ils exécutent une gestion parallèle des entrées de données et envoient les données dans une base de données ou un système de fichiers.
Topologie de l'outil
La topologie dans Storm utilise un système de graphe orienté acyclique (DAG). Son fonctionnement est similaire aux jobs MapReduce dans Hadoop. La topologie est composée des éléments suivants :
- Les spouts : Ils sont le point d’entrée des flux de données. Ils se connectent à la source de données, récupèrent les données en continu, transforme les informations en flux de tuples et envoie ces résultats aux bolts
- Les bolts : Ils stockent la logique de traitement. Ils exécutent diverses fonctions (telles que des fonctions d’agrégation, de jointure, de filtrage, etc.). La sortie crée de nouveaux flux pour un nouveau traitement via des bolts supplémentaires, ou alors stocke les données dans une base de données ou un système de fichier.

Ce schéma montre que la topologie dans Storm est un enchaînement de traitement, dont la répartition des bolts et spouts permet des résultats très rapides.
Modèle de Parallélisme : Qu'est ce que c'est ?
Apache Storm utilise un modèle de parallélisme basé sur les tâches et les bolts. Les données sont traitées par un ensemble de tâches parallèles qui sont liées ensemble en utilisant des bolts. Chacune des tâches traite un sous-ensemble des données d’entrée et les bolts permettent de connecter les tâches entre elles pour créer des flux de données. Cela permet à Storm de traiter les données de manière distribuée, ce qui augmente les performances en utilisant plusieurs machines pour traiter les données simultanément.
Les DRPC (Distributed Remote Procedure Call) permettent le parallélisme de calculs très intenses et consommateurs. Ils se comportent plus ou moins comme un spout, à ceci près que les sources de données sont les arguments de la fonction et qui retourne une réponse sous forme de texte ou de json pour chacun de ces flux. Ils sont utiles dans le cadre de calcul coûteux en temps et ainsi diminuer les temps de réponse.
La tolérance de pannes
Dans la gestion des traitements relatifs au Big Data, la surcharge d’informations peut entraîner des erreurs ou des pannes sur certains clusters. Il est ainsi primordial que Storm puisse continuer à fonctionner malgré une panne.
Ainsi, lorsqu’un worker est en échec ou en panne, Storm le redémarre automatiquement. Si un nœud complet se met en panne, Storm redémarre les tâches qui était en cours sur d’autres workers. De même, lorsque le Nimbus ou les superviseurs tombent en panne, ils sont également redémarrés automatiquement. Il est même possible de forcer l’arrêt d’un processus (par exemple avec taskkill -9) sans affecter les clusters ou les topologies.
Les différents niveaux de garanties
Storm propose plusieurs niveaux de garantie pour le traitement des flux de données :
- At most once : C’est le niveau de garantie par défaut. Elle garantit que chaque tuple est traité au moins une fois.
- At least once : Cette garantie signifie que chaque tuple sera traité au moins une fois. Elle peut entraîner des traitements en double de certains tuples.
- Exactly once : Cette garantie signifie que chaque tuple sera traité exactement une fois. Il s’agit du niveau de garantie le plus élevé mais également le plus compliqué à implémenter, et nécessite des librairies tiers.
Trident
Trident est une abstraction de haut niveau qui fournit une API pour la transformation et l’agrégation de données en temps réel. Il permet aux développeurs de se concentrer sur la logique métier plutôt que sur les détails de la mise en œuvre des tâches de traitement. Il offre une gestion de l’état, ce qui facilite la gestion des données en mémoire pour les tâches de traitement à long terme, et il prend en charge les transactions distribuées pour garantir la fiabilité des données.
Apache Storm vs Spark
Bien que ces deux technologies ont des utilisations différentes, elles sont néanmoins toutes deux très utilisées dans la gestion du big data. Le tableau suivant indique la comparaison entre ces deux technologies.
| Storm | Spark | |
|---|---|---|
| Architecture | Micro-batch | Micro-batch/batch |
| Type de traitement | Streaming temps réel | Streaming temps réel et traitement par lot |
| Latence | Quelques millisecondes | Quelques secondes |
| Scalabilité | Des milliers de noeuds | Des dizaines de milliers de noeuds |
| Langages supportés | Pas de distinction | Java, Scala, Python, R |
| Utilisation | Traitement de flux de données en temps réel | Traitement de flux de données en temps réel et traitements par lots |
Conclusion
En conclusion, Apache Storm est un système de traitement de flux de données distribué qui permet de traiter de grandes quantités de données en temps réel de manière efficace et fiable. Avec sa plateforme flexible et scalable, Apache Storm s’est avéré être un choix populaire pour les entreprises qui cherchent à traiter des données en temps réel et à prendre des décisions en conséquence.









