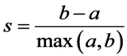Le clustering est une discipline particulière du Machine Learning ayant pour objectif de séparer vos données en groupes homogènes ayant des caractéristiques communes. C’est un domaine très apprécié en marketing, par exemple, où l’on cherche souvent à segmenter les bases clients pour détecter des comportements particuliers. L’algorithme des K-moyennes (K-means) est un algorithme non supervisé très connu en matière de Clustering.
Dans cet article nous allons détailler son fonctionnement et les moyens utiles pour l’optimiser.
Cet algorithme a été conçu en 1957 au sein des Laboratoires Bell par Stuart P.Lloyd comme technique de modulation par impulsion et codage(MIC) . Il n’a été présenté au grand publique qu’en 1982. En 1965 Edward W.Forgy avait déjà publié un algorithme quasiment similaire c’est pourquoi le K-means est souvent nommé algorithme de Lloyd-Forgy.
Les champs d’application sont divers : segmentation client, analyse de donnée, segmenter une image, apprentissage semi-supervisé….
Le Principe de l'algorithme des k-means
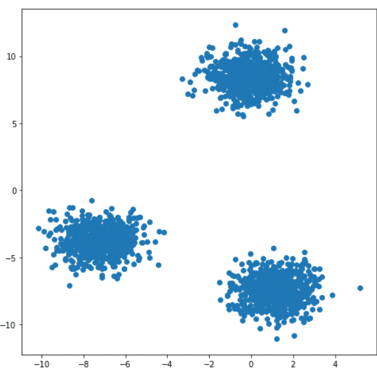
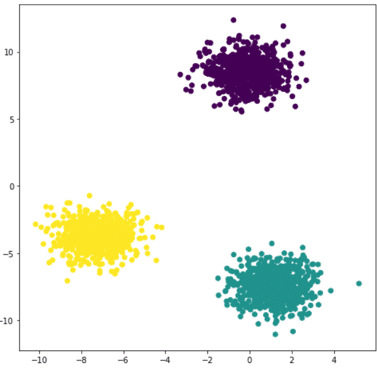
Étant donnés des points et un entier k, l’algorithme vise à diviser les points en k groupes, appelés clusters, homogènes et compacts. Regardons l’exemple ci-dessous :
Sur ce jeu de données en 2D il apparaît clair que l’on peut le diviser en 3 groupes.
Concrètement comment s’y prend-on ?
L’idée est assez simple et intuitive. La première étape consiste à définir 3 centroïdes aléatoirement auxquels on associe 3 étiquettes par exemple 0,1,2. Ensuite nous allons pour chaque point regarder leur distance aux 3 centroïdeset nous associons le point au centroïde le plus proche et l’étiquette correspondante. Cela revient à étiqueter nos données.
Enfin on recalcule 3 nouveaux centroïdes qui seront les centres de gravité de chaque nuage de points labellisés. On répète ces étapes jusqu’à ce que les nouveaux centroïdes ne bougent plus des précédents. Le résultat final se trouve sur la figure de droite.
Notion de distance et initialisation
Vous l’aurez compris dans cet algorithme deux points sont clé : Quelle est la métrique utilisée pour évaluer la distance entre les points et les centroïdes ? Quel est le nombre de clusters à choisir ?
Dans l’algorithme des k-moyennes généralement on utilise la distance euclidienne, soient p = (p1,….,pn) et q = (q1,….,qn)
Elle permet d’évaluer la distance entre chaque point et les centroïdes. Pour chaque point on calcule la distance euclidienne entre ce point et chacun des centroïdes puis on l’associe au centroïde le plus proche c’est-à-dire celui avec la plus petite distance.
Dans l’exemple précédent il était aisé de trouver le nombre idéal de clusters simplement en visualisant graphiquement. Généralement les jeux de données ont plus de deux dimensions et il est donc difficile de visualiser le nuage de points et d’identifier rapidement le nombre de clusters optimal. Supposons dans l’exemple précédent que nous n’avons pas visualiser les données avant et décidons de tester différentes fois avec un nombre de clusters initiaux différents. Voici les résultats obtenus :
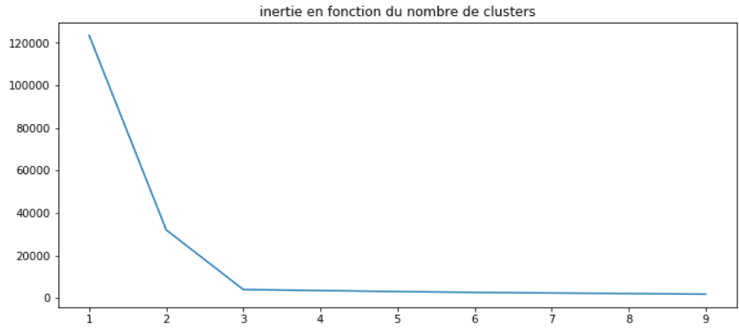
Le partitionnement est inexact car le nombre de clusters initiaux est bien supérieur au nombre idéal en l’occurrence 3. Il existe des méthodes pour déterminer le nombre de clusters idéal. La plus connu est la méthode du coude. Elle s’appuie sur la notion d’inertie. On définit cette dernière comme ceci : la somme des distances euclidiennes entre chaque point et son centroïde associé. Evidemment plus on fixe un nombre initial de clusters élevés et plus on réduit l’inertie : les points ont plus de chance d’être à côté d’un centroïde. Regardons ce que cela donne sur notre exemple :
On remarque que l’inertie stagne à partir de 3 clusters. Cette méthode est concluante. On peut la coupler avec une approche plus précise mais qui requiert plus de temps de calcul : le coefficient de silhouette. Il se définit comme suit :
a la moyenne des distances aux autres observations du même cluster (cad la moyenne intra-cluster).
b la distance moyenne au cluster le plus proche.
Ce coefficient peut varier entre -1 et +1. Un coefficient proche de +1 signifie que l’observation est située bien à l’intérieur de son propre cluster, tandis qu’un coefficient proche de 0 signifie qu’elle se situe près d’une frontière ; enfin, un coefficient proche de -1 signifie que l’observation est associée au mauvais cluster.
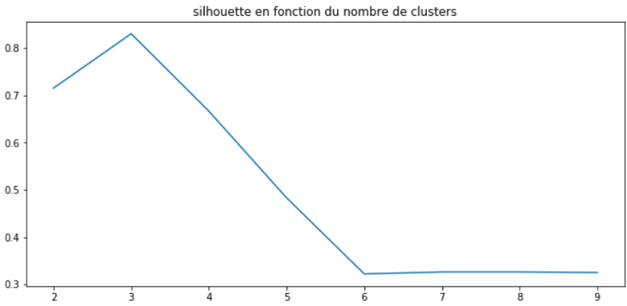
Comme pour l’inertie il est judicieux d’afficher l’évolution du coefficient en fonction du nombre de clusters comme ci-dessous :
Cette méthode permet également de déceler le nombre de clusters idéal c’est-à-dire 3.
Il est également primordial en plus de ces deux méthodes de faire une analyse poussée des clusters créés. J’entends par là une analyse descriptive précise et approfondie pour déterminer les caractéristiques communes de chaque cluster. Cela vous permettra de comprendre les profils types de chaque cluster.
Et maintenant la pratique en python
L’entraînement d’un algorithme des K-moyennes est facilité avec la librairie Scikit-Learn. Notre jeu de données qui a servi d’exemples se crée facilement avec la fonctionalité make_blobs de Scikit-Learn. Voici comment l’implémenter en code :
Maintenant que nous avons notre jeu de données on peut passer à l’implémentation d’un K-means. Nous allons utiliser la librairie Scikit-Learn et visualiser le résultat :
L’attribut n_clusters de la classe KMeans de Scikit-Learn permet de fixer le nombre de centroïdes que l’on souhaite. Par conséquent elle définit aussi le nombre de centroïdes initiaux. Cette classe utilise par défaut non pas une méthode d’initialisation aléatoire mais une méthode développée en 2007 par David Arthur et Sergei Vassilvitskii dénommée K-MEANS ++. Elle consiste à sélectionner des centroïdes distincts les uns des autres ce qui limite les risques de convergence vers une solution non-optimale. La distance par défaut utilisée est bien évidemment la distance euclidienne définie plus haut.
Les limites de l’algorithme des k-means
Comme nous l’avons vu l’algorithme nécessite en amont de définir le nombre de partitions. Cela demande d’en avoir une idée précise et même si nous avons vu deux méthodes complémentaires pour optimiser sur certains jeux de données elles ne sont pas infaillibles.
En effet les jeux de données avec des formes elliptiques par exemple poseront problème. Dans l’exemple ci-dessous on voit clairement deux groupes s’apparentant à deux ellipses. La figure de droite montre le résultat après utilisation de l’algorithme des k-moyennes. Il est clair que celui-ci n’a pas réussi à identifier nos deux ellipses.
L’utilisation d’un algorithme de clustering tel que l’algorithme des k-means n’est pas aisée suivant les données dont vous disposez. Il faudra souvent les retravailler.
Chez Datascientest nous vous apprenons à maîtriser les principaux algorithmes de clustering ainsi qu’à les interpréter sur des jeux de données.