Jupyter Notebook: Ein unverzichtbares Tool für den Code-Austausch

Jupyter Notebook ist eine Webanwendung, mit der du Computercode austauschen kannst. Hier erfährst du alles, was du über dieses Tool wissen musst, das bei Entwicklern sehr beliebt ist, aber auch in der Data Science nicht fehlen darf. Jedes Programmierprojekt muss an einem bestimmten Punkt seines Fortschritts geteilt werden. Es ist möglich, den Quellcode zu teilen, […]
Die Brownsche Bewegung: Prinzip und praktische Anwendungen
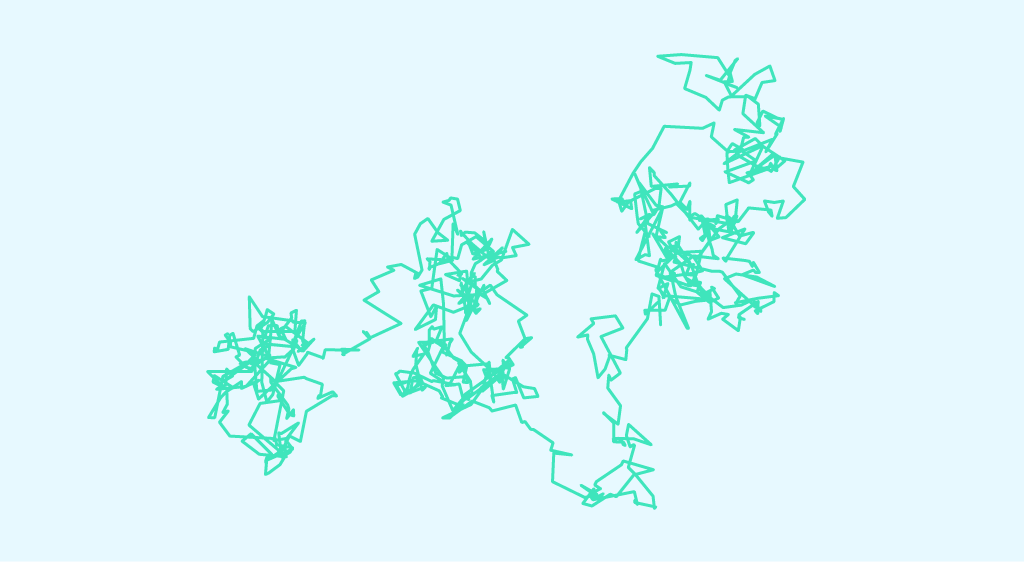
Nehmen wir ein mikrometergroßes Teilchen, das in einer Flüssigkeit schwimmt. Dieses Teilchen bewegt sich zufällig, weil andere kleine Teilchen auf dieses „große“ Teilchen stoßen. Dies ist das Prinzip der Brownschen Bewegung, auch Wiener-Prozess genannt. Historisch gesehen entdeckte der Botaniker Robert Brown die Brownsche Bewegung im Jahr 1827. Er beobachtete die chaotische Bewegung von Pollenkörnern in […]
Beautiful Soup: Einführung in Web Scraping mit Python

Als User im Internet hat man Zugang zu vielen Informationen, die sich auf Kunden, Angebote, Aktienkurse, physikalische Phänomene usw. beziehen. Diese Daten können von Nutzern gelesen werden, aber man würde sie gerne auswerten, indem man sie in ein brauchbares Format umwandelt, um sie dann zu analysieren und daraus Nutzen zu ziehen. Web Scraping ist die […]
Verteilte Architektur: Definition, ihre Beziehung zu Big Data
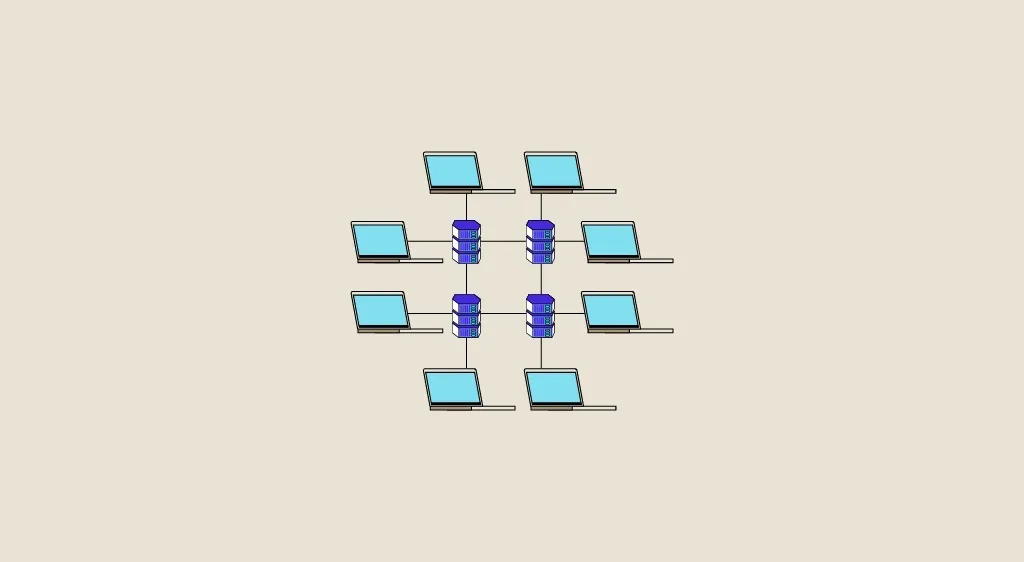
Verteilte Architekturen sind Informationssysteme, die verfügbare Ressourcen verteilen und nutzen, die sich nicht am gleichen Ort oder auf dem gleichen Rechner befinden. In diesem Artikel erklären wir ausführlich, was diese Architekturen sind, welche Vorteile sie gegenüber anderen Architekturen haben und wie sie in der Praxis in der Data Science eingesetzt werden. Was ist eine verteilte […]
Zeitreihe Python: Verarbeitung und Modellierung
Eine Zeitreihe ist eine Datentabelle, die die Entwicklung einer Variablen im Laufe der Zeit wiedergibt. In Python wird die Zeitreihe oft in Form einer Pandas-Reihe verarbeitet, die durch ein DateTime indiziert ist. Dieses Format ist sehr einfach zu verarbeiten und zu visualisieren. Zeitreihen werden in vielen Bereichen wie z. B. der Astronomie und der Meteorologie […]
AWS SageMaker: Leitfaden für die Nutzung der Plattform

Amazon SageMaker ist eine von Amazon Web Services (AWS) entwickelte Cloud-Plattform, die besonders für die Data Science nützlich ist. Im Folgenden erfährst Du mehr über die wichtigsten Funktionen und wie Du die Tools der Plattform von der Entwicklung eines Machine-Learning-Modells bis hin zu dessen Einsatz nutzen kannst. Einführung in Amazon SageMaker Amazon SageMaker ist eine […]
Bokeh: Die Python-Bibliothek für Visualisierung der nächsten Generation

Die Datenanalyse bietet viele Möglichkeiten. Allerdings kann es für nicht-technische Benutzer in einem Unternehmen schwierig sein, die Rohdaten zu interpretieren. Indem sie relevante Informationen klar und explizit darstellt, behebt die Data Visualization dieses Problem und ermöglicht es jedem, Big Data zu nutzen.. Wenn du bereits mit Data-Visualization-Bibliotheken wie Matplotlib und/oder Seaborn vertraut bist, werden wir […]
Bayesianische Optimierung: Definition und Funktionsweise
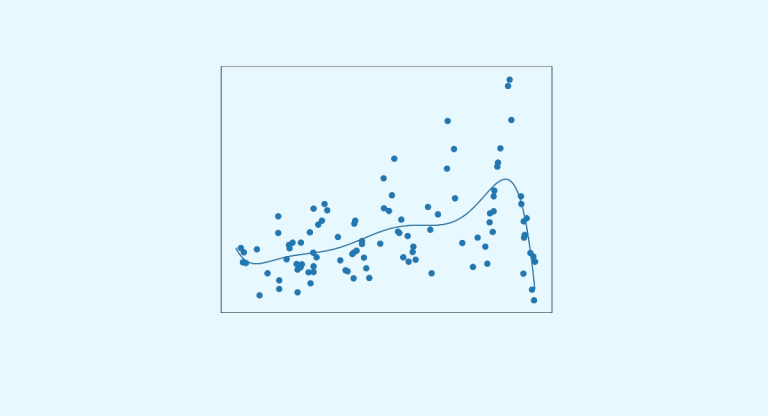
Um ein Vorhersagemodell zu definieren, verwenden Datenwissenschaftler eine Vielzahl von Beobachtungen. Doch während die Untersuchung dieser Beobachtungen zu einem optimalen Ergebnis führt, haben die Datenexperten oft nur wenig Zeit, um alle Hypothesen zu analysieren. Wie kann man also in kürzester Zeit das richtige Modell finden? An dieser Stelle kommt die Bayes’sche oder Bayesianische Optimierung ins […]
