
Als User im Internet hat man Zugang zu vielen Informationen, die sich auf Kunden, Angebote, Aktienkurse, physikalische Phänomene usw. beziehen. Diese Daten können von Nutzern gelesen werden, aber man würde sie gerne auswerten, indem man sie in ein brauchbares Format umwandelt, um sie dann zu analysieren und daraus Nutzen zu ziehen. Web Scraping ist die Technik, die es ermöglicht, diese Informationen in ein Format zu bringen, das von Computerprogrammen genutzt werden kann. Wir werden in diesem Artikel herausfinden, wie man sie mit Beautiful Soup durchführen kann.
Was ist Beautiful Soup?
Zum Beispiel möchte man vielleicht Zugang zu allen Bewertungen eines HP Tintenpatronen schwarz Packs auf Amazon haben, um eine syntaktische, semantische und sentimentale Analyse durchführen zu können und sich eine eigene Meinung zu bilden. Durch Web Scraping von einem Ladenlokalisierer (z. B. einer Karte) kann man eine Liste von Geschäftsstandorten erstellen. Man kann auch Aktienkurse erhalten, um bessere Investitionsentscheidungen zu treffen.
Was den Teil der Datenanalyse betrifft, so gibt es für jede Art von Daten und jedes Ziel spezifische Techniken. In der folgenden Abbildung siehst du den „logistischen“ Prozess, der zu einer fundierten Entscheidungsfindung führt:
Wenn wir uns in der Phase des Datenabrufs befinden, würden wir gerne auf alle Informationen auf einer Webseite zugreifen, um dann die gewünschte Studie durchführen zu können.
Um dies zu erreichen, kann man sie „von Hand“ in ein anderes Dokument kopieren. Dies ist jedoch eine mühsame Arbeit, da es viel Zeit in Anspruch nehmen kann, ganz zu schweigen von den Tippfehlern, die beim Eingeben passieren können. Wie bereits in der Einleitung gesagt, ermöglicht das Web Scraping den Zugriff auf diese Informationen in einem verwertbaren Format.
Für die zweite Phase werden die technischen Fähigkeiten von Datenanalysten, Dateningenieuren oder Datenwissenschaftlern herangezogen, um Algorithmen und relevante statistische Studien zu implementieren. Im Fall der Analyse von Kommentaren zu einem Produkt kann man z. B. einen NLP-Algorithmus verwenden, der es Maschinen ermöglicht, die menschliche Sprache zu verstehen.
Die Interpretation der Daten wird oft in einem Team vorgenommen, wobei die Meinung von Fachleuten berücksichtigt wird (z. B. die Meinung eines Arztes berücksichtigen, wenn man an einem Projekt mit medizinischen Daten arbeitet), um schließlich zu einer optimalen Entscheidungsfindung zu gelangen.
Präsentation von Beautiful Soup
In diesem Artikel werden wir uns auf Phase 1 konzentrieren, da wir uns mit dem Abrufen von Daten beschäftigen.
Im nächsten Abschnitt werden wir uns eine Anwendung der Beautiful Soup Library ansehen, die Web Scraping in Python ermöglicht.
Im nächsten Abschnitt werden wir uns mit einer Web-Scraping-Buchhandlung in Python beschäftigen, die ein hervorragendes (einfach zu handhabendes) Werkzeug ist, um Informationen aus unstrukturierten Daten zu extrahieren: Beautiful Soup.
Die Python-Bibliothek Beautiful Soup ermöglicht es, Inhalte zu extrahieren und sie in eine Python-Liste, -Tabelle oder -Wörterbuch umzuwandeln.
Diese Bibliothek ist sehr beliebt, weil sie eine umfassende Dokumentation hat und ihre Funktionen gut strukturiert sind. Außerdem gibt es eine große Community, die verschiedene Lösungen für die Nutzung dieser Bibliothek anbietet.
Warum "Beautiful Soup"?
Webseiten werden mit den Computersprachen HTML und CSS geschrieben, die das Layout von Webseiten ermöglichen. Um den Inhalt zu verwalten und zu organisieren, wird HTML verwendet. Der Teil, der das Aussehen der Webseite verwaltet (Farben, Textgröße usw.), wird von der Sprache CSS verwaltet.
In der Webentwicklung ist „Tag-Suppe“ ein abwertender Begriff für syntaktisch oder strukturell inkorrektes HTML, das für eine Webseite geschrieben wurde.
Ein Beispiel für Web Scraping mit Beautiful Soup
Lass uns ein einfaches Beispiel nehmen, um uns mit diesen Begriffen vertraut zu machen. Das folgende Beispiel wurde von Kaggle genommen und das Ziel ist es, Daten über die Bevölkerung der Welt zu scrapen. Die Daten sind auf der Worldometer-Website verfügbar, einer Open Source, die von einem internationalen Team freiwilliger Entwickler und Forscher betrieben wird und deren Ziel es ist, globale Statistiken einem breiten Publikum auf der ganzen Welt zur Verfügung zu stellen.
Hier ist eine Vorschau der Seite, die wir scrapen werden
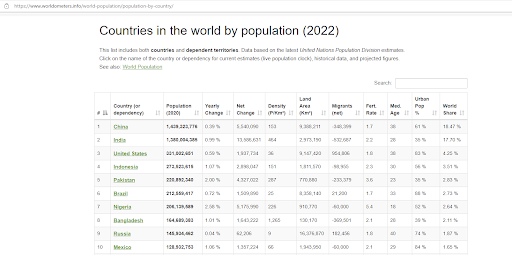
Unser Ziel ist es, diese Tabelle abzurufen und sie in einen DataFrame umzuwandeln, ohne dass wir alle Daten von Hand kopieren müssen.
In einem Jupyter Notebook importieren wir zunächst die benötigten Bibliotheken.
- Dann erstellst du eine url-Variable im String-Format (Text), die den Link zu der betreffenden Seite enthält.
Um die Daten vorzubereiten, benutzt du die Funktion requests.get():
- Da die Daten nun vorbereitet sind, kann die Funktion BeautifulSoup() den HTML-Code dieser Seite extrahieren. Im Argument dieser Funktion wählen wir das .text-Objekt aus.
- In der Variable data speichern wir den HTML-Code. Wir suchen mit der Funktion .find_all() nach dem Schlüsselwort „table“:
- Du benutzt den Befehl .read_html(str()), damit die Maschine den HTML-Code liest und holst dir dann das erste und einzige Element dieses Objekts (das Array).
Jetzt werden die ersten Elemente angezeigt, Befehl .head() des DataFrame :
- Man kann die Datenbank auch mit folgendem Befehl in das csv-Format exportieren:
Dieser Befehl erstellt eine Datei im csv-Format, die sich im angegebenen Pfad befindet.
Um die Arbeit mit dem DataFrame zu vereinfachen, kannst du die Namen der Spalten ändern oder einige Spalten entfernen, wenn du sie nicht verwendest.
Nachdem wir nun die Daten, die auf der Worldometer-Website zur Verfügung gestellt wurden, erhalten haben und sie in einem DataFrame-Format vorliegen, können wir mit den weiteren Schritten fortfahren und Studien durchführen. Man kann also mit dem weiteren Prozess beginnen (Phase 2, 3 und 4, siehe das Schema in der Einleitung). Je nach Art der Daten und je nach den zu erreichenden Zielen kann man verschiedene Studien durchführen: explorative Analyse, Vorschlag eines Machine-Learning-Modells, Modellierung von Zeitreihen, etc.
Fazit
Wir haben gerade ein Beispiel gesehen, mit dem man in einer Tabelle gespeicherte Daten abrufen kann, aber man muss bedenken, dass je nach Struktur der Webseite, auf der man die Daten scrapen will, unterschiedliche Bibliotheken und Funktionen verwendet werden.
Die gute Nachricht ist, dass es im Internet viele Beispiele gibt, die auf das Format der Seite und die Konfiguration der Daten, die du scrapen willst, abgestimmt sind.
Zusammenfassend lässt sich sagen, dass Web Scraping das „intelligente“ Surfen im Internet ermöglicht und somit eine reichhaltige Ressource für jeden Bereich der Forschung oder des persönlichen Interesses darstellt.
Die Data Analyst Weiterbildung von Datascientest ermöglicht es dir, dich mit den Fähigkeiten des Web Scrapings vertraut zu machen und sie in die Praxis umzusetzen, aber nicht nur das. Wenn du dich in der Datenanalyse weiterbilden und technische Fähigkeiten im Zusammenhang mit diesem Thema erwerben möchtest, entdecke unsere Weiterbildung:







