
Beim Surfen im Internet ist es auf vielen Seiten nicht möglich, Daten direkt für den persönlichen Gebrauch zu speichern. Die einfachste Lösung in diesem Fall ist einfach das manuelle Kopieren und Einfügen der Daten, was schnell mühsam und zeitaufwendig werden kann. Aus diesem Grund werden häufig Web Scraping-Techniken eingesetzt, um Daten von Webseiten zu extrahieren.
Web Scraping ist die Automatisierung des Prozesses der fast automatischen Extraktion von Daten aus Webseiten. Dies geschieht mithilfe von Scraping-Tools, die oft auch als Web Scraper bezeichnet werden. Diese ermöglichen dann das Laden und Extrahieren spezifischer Daten von Websites entsprechend den Bedürfnissen der Nutzer. Sie werden meist für eine einzelne Website maßgeschneidert und dann so konfiguriert, dass sie auch mit anderen Websites funktionieren, die die gleiche Struktur haben.
Zusammen mit der Programmiersprache Python sind BeautifulSoup und Scrapy Crawler die am häufigsten verwendeten Tools im Bereich des Web Scrapings. In diesem Artikel werden wir einige Unterschiede zwischen den beiden Tools vorstellen und uns dann auf Scrapy konzentrieren.
Web Scraping vs Web Crawling
Bevor wir zum eigentlichen Thema kommen, ist es interessant, den Unterschied zwischen den Techniken Web Scraping und Web Crawling zu verstehen:
Das Web Scraping
Beim Web Scraping werden Roboter eingesetzt, um eine Webseite programmatisch zu analysieren und Inhalte zu extrahieren. Beim Web Scraping ist es daher notwendig, gezielt nach Daten zu suchen.
Beispiel für Web Scraping: Extraktion von Preisen für verschiedene spezifische Produkte auf der Amazon-Website oder einer anderen E-Commerce-Website.
Das Web Crawling
Der Begriff Crawling wird als Analogie zur Art und Weise verwendet, wie eine Spinne krabbelt (dies ist auch der Grund, warum Webcrawler oft als Spider bezeichnet werden).
Web Crawling Tools werden auch Roboter (Bots, die Crawler genannt werden) einsetzen, um das World Wide Web systematisch zu durchsuchen, normalerweise mit dem Ziel, es zu indexieren.
Dabei wird eine Seite in ihrer Gesamtheit betrachtet und jedes Element auf ihr referenziert, einschließlich des letzten Buchstabens und des letzten Punktes der Seite. Die verwendeten Bots werden dann, während sie durch Unmengen von Daten und Informationen navigieren, die Informationen, die sich in den tiefsten Schichten befinden, lokalisieren und abrufen.
Als Beispiel für Web Crawling-Tools können alle Suchmaschinen wie Google, Yahoo oder Bing genannt werden. Diese crawlen Webseiten und nutzen die extrahierten Informationen, um diese zu indexieren.
Auch interessant:
| Deep Neural Network |
| Deep Learning vs. Machine Learning |
| Deep Learning – was ist das eigentlich ? |
| Deep Fake Gefahren |
| Python Deep Learning Basics |
| Style Transfer Deep Learning |
BeautifulSoup vs Scrapy
Weiter geht es mit einem kurzen Vergleich zwischen BeautifulSoup und Scrapy, den beiden meistgenutzten Bibliotheken für Web Scraping.
- BeautifulSoup
BeautifulSoup ist eine beliebte Python-Bibliothek, mit der du HTML- oder XML-Dokumente analysieren kannst, um sie mithilfe einer Baumstruktur oder in Form eines Wörterbuchs zu beschreiben. Diese ermöglicht es dann, bestimmte Daten auf Webseiten leicht zu finden und zu extrahieren. BeautifulSoup ist recht einfach zu erlernen und verfügt über eine gute und umfassende Dokumentation, die das Lernen leicht macht.
Die Vorteile von BeautifulSoup :
Sehr gute Dokumentation (sehr hilfreich, wenn man gerade erst anfängt).
Große Gemeinschaft von Nutzern.
Für Anfänger leicht zu erlernen und zu beherrschen.
Nachteile:
Abhängigkeit von anderen externen Python-Bibliotheken.
Scrapy
Scrapy ist ein kompletter Open-Source-Framework und gehört zu den leistungsfähigsten Bibliotheken, die für die Datenextraktion im Internet verwendet werden. Scrapy enthält nativ Funktionen, um Daten aus HTML- oder XML-Quellen mithilfe von CSS- und XPath-Ausdrücken zu extrahieren.
Einige Vorteile von Scrapy :
Effizient in Bezug auf Speicher und CPU.
Eingebaute Funktionen für die Datenextraktion.
Leicht erweiterbar für große Projekte.
Ziemlich leistungsstark und schnell im Vergleich zu anderen Bibliotheken.
Als Nachteile sind die geringe Dokumentation zu nennen, die Anfänger entmutigen kann.
Um alle oben genannten Punkte zusammenzufassen:
| Scrapy | BeautifulSoup |
|---|---|
|
|

Scrapy-Architektur
Wenn ein Projekt erstellt wird, gibt es verschiedene Dateien, die mit den Hauptkomponenten von Scrapy interagieren. Die Architektur von Scrapy, wie sie in der offiziellen Dokumentation beschrieben wird, ist unten zu sehen:
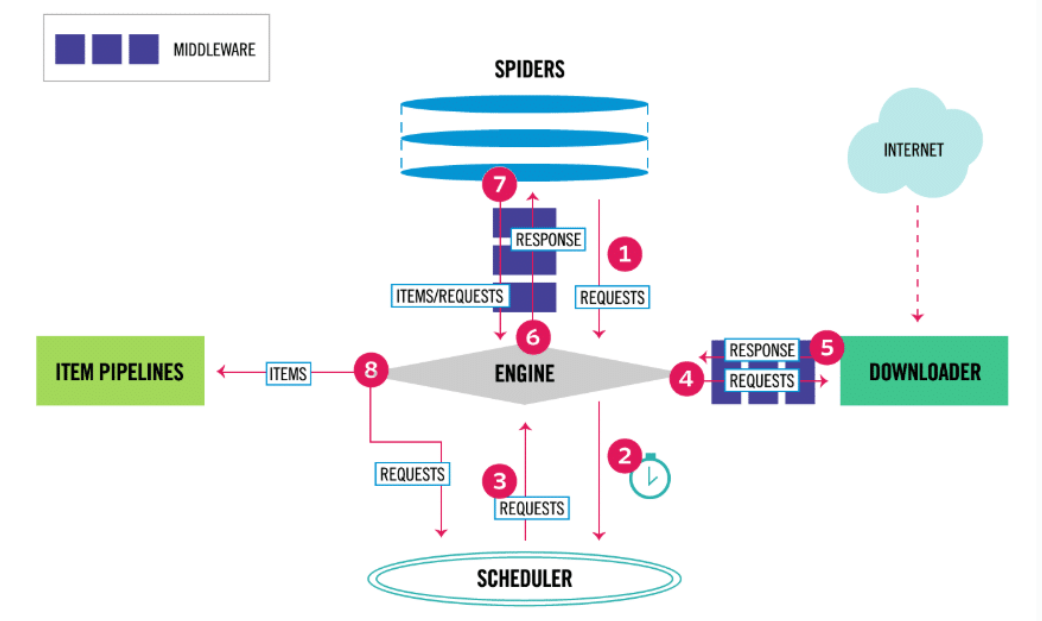
Wenn wir das Architekturdiagramm von Scrapy analysieren, sehen wir, dass sein zentrales Element, die Engine oder der Motor, vier ausführende Komponenten steuert:
- Die Spiders
- Die Item Pipelines
- Der Downloader
- Der Scheduler
Zu Beginn des Prozesses erfolgt die Kommunikation über die Spider, die Anfragen (mit den zu scrappenden URLs und den zu extrahierenden Informationen) an die Engine weiterleiten. Die Engine leitet die Anfrage an den Scheduler weiter, der sie in der Warteschlange speichert (wenn mehrere URLs übertragen werden).
Die Engine wird auch Anfragen vom Scheduler, der die Aufgaben zuvor angeordnet hat, empfangen, um sie an das Downloader-Modul weiterzuleiten, das den HTML-Code der Seite herunterlädt und ihn in ein Response-Objekt umwandelt.
Das Response-Objekt wird dann an den Spider und dann an das ItemPipeline-Modul weitergeleitet. Dieser Vorgang wiederholt sich für die verschiedenen URL-Links der Webseiten.
Die Rollen der Komponenten können nun besser definiert werden:
- Spiders: Die Klassen, die die verschiedenen Methoden des Scrappings durch die Benutzer definieren. Die Methoden werden dann von Scrapy bei Bedarf aufgerufen.
- Scrapy Engine: Kontrolliert den Datenfluss und löst alle Ereignisse aus.
- Scheduler: Kommuniziert mit der Engine über die Reihenfolge der auszuführenden Aufgaben.
- Downloader: Empfängt Anfragen von der Engine, um den Inhalt von Webseiten herunterzuladen.
- ItemPipeline: Abfolgen von Transformationsschritten (zur Bereinigung, Validierung von Daten oder zum Einfügen in eine Datenbank), die auf die extrahierten Rohdaten angewendet werden.
Installation von Scrapy
Die Installation von Scrapy ist recht einfach. Führe einfach den folgenden Befehl in einem Ubuntu-Terminal aus. Du kannst die Entsprechungen dieser Befehle für andere Betriebssysteme leicht finden:
# Erstellen einer virtuellen Umgebung (OPTIONAL)
virtualenv scrapy_env
# Aktivierung der Umgebung (OPTIONAL).
source scrapy_env/bin/active
# Installation von Scrapy
pip install scrapy
# Test zur Überprüfung der Installation.
scrapy
# Führe einen schnellen Benchmark-Test durch, um zu sehen, wie Scrappy auf deiner Hardware funktioniert.
scrapy bench
Die Scrapy-Eingabeaufforderung
In der Experimentierphase, d.h. wenn wir nach der Syntax des auszuführenden Codes suchen, um Informationen aus Internetseiten zu extrahieren, hat Scrapy eine spezielle Eingabeaufforderung, die es uns erlaubt, interaktiv mit der Engine zu interagieren: die Scrapy Shell.
Die Scrapy Shell ist auf Python aufgebaut, sodass wir jedes Modul, das wir benötigen, importieren können.
Um auf diese Eingabeaufforderung zuzugreifen (nachdem Scrapy installiert wurde), führe einfach den folgenden Befehl aus:
# Ouvrir le shell scrapy
scrapy shell „URL-de-la-page-internet“
# exemple: scrapy shell „https://www.ville-ideale.fr/abries_5001“
Nach dem Start kannst du in der Shell die Befehle ausführen, die die Informationen über die angegebene Seite extrahieren. Wir können dann interaktiv verschiedene Befehle und Extraktionsansätze ausprobieren.
Am Ende der Experimente werden die Codezeilen für die Extraktion in einer Spider-Klasse zur Automatisierung zusammengefasst.
Die CSS- und XPATH-Selektoren
Beim Erstellen einer Spider-Klasse ist der wichtigste Schritt, den Code zu erstellen, der für das Abrufen der Daten verantwortlich ist (der Code, der im vorherigen Schritt von der Scrapy-Shell aus bestimmt wurde).
Um anzugeben, welche Daten von der Website von Scrapy heruntergeladen werden sollen, können wir :
XPath-Selektoren:
XPath-Selektoren werden beim Web Scraping aufgrund ihrer großen Bandbreite an Möglichkeiten sehr häufig verwendet. Zum Beispiel:
- Das genaue Element angeben, das von der Seite extrahiert werden soll.
- Den mit einem Element verbundenen Text abrufen.
- Das übergeordnete oder untergeordnete Element herunterladen.
- Benachbarte Elemente herunterladen.
Elemente herunterladen, die mit Schlüsselwörtern beginnen/enden. - Elemente abrufen, deren Attribute eine mathematische Bedingung erfüllen.
Die CSS-Selektoren:
CSS-Selektoren sind eine einfachere Alternative für Anfänger, insbesondere für diejenigen, die mit den CSS-Befehlen vertraut sind. CSS-Selektoren haben etwas weniger Möglichkeiten als XPath, aber im Fall von Scrapy wurden sie um eine zusätzliche Syntax erweitert, die es ermöglicht, ein bestimmtes Elementattribut abzurufen.
Bibliothek BeautifulSoup:
Da Scrapy in Python geschrieben ist, ist es möglich, bei Bedarf andere Bibliotheken zu importieren, um bestimmte Aufgaben zu erledigen. Dies ist der Fall bei der BeautifulSoup-Bibliothek, die bei der Definition der Datenextraktionsklassen (Spiders) verwendet (und somit importiert) werden kann.
Beispiel für die Datenextraktion mit Scrapy
Um dir einen konkreten Einblick in die Möglichkeiten von Scrapy zu geben, werden wir einige Daten über DataScientest von der Website https://fr.trustpilot.com/review/datascientest.com abrufen.
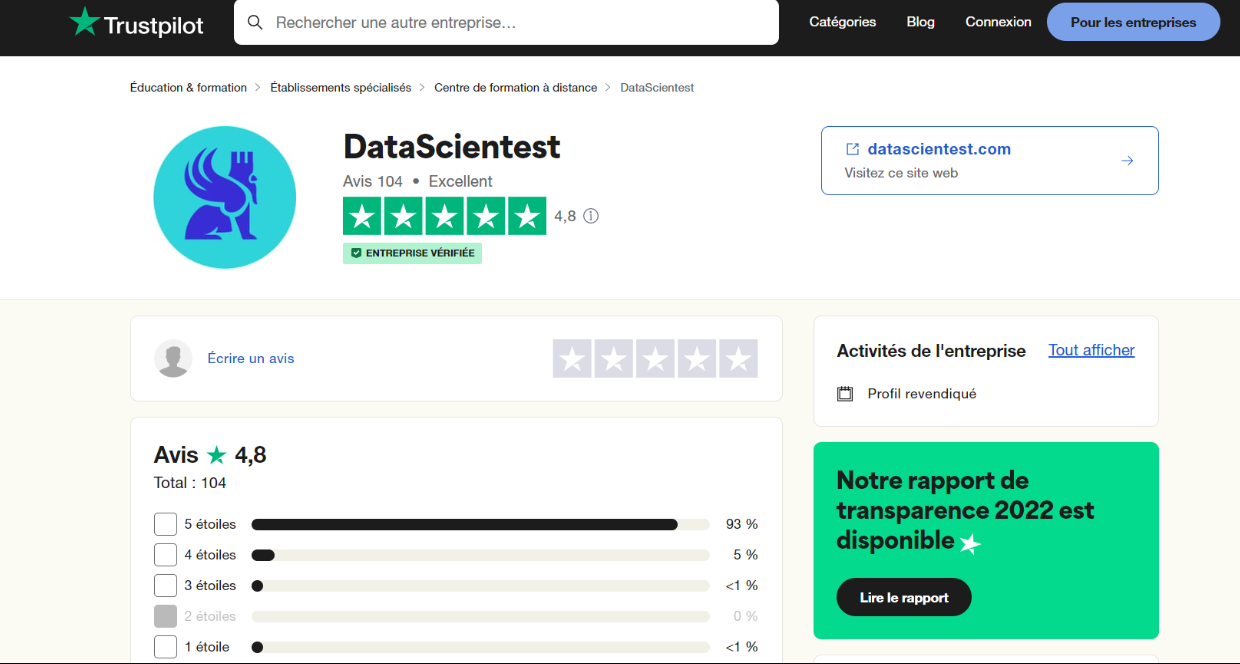
Die Idee ist, alle Kommentare und Bewertungen von Lernenden, die auf trustpilot verfügbar sind, in einer einzigen CSV-Datei zusammenzufassen. Wir werden uns der Einfachheit halber auf die Bewertungen beschränken, die auf Deutsch abgegeben wurden.
Die empfohlene Methodik für das Web Scraping mit Scrapy :
- Analysiere und lokalisiere auf der Internetseite die verschiedenen Informationen, die du extrahieren willst.
- Prototype in der Scrapy Shell die verschiedenen Befehle, um jedes der zu extrahierenden Elemente, die im vorherigen Schritt identifiziert wurden, zu extrahieren.
- Erstelle ein Scrapy-Projekt und erstelle den Spider (um festzulegen, wie die Informationen von allen Seiten extrahiert werden sollen).
- Den Spider auf einer Seite testen
Den Spider auf alle Seiten anwenden, um alle Informationen abzurufen.
Step 1: Analyse und Lokalisierung der zu extrahierenden Informationen
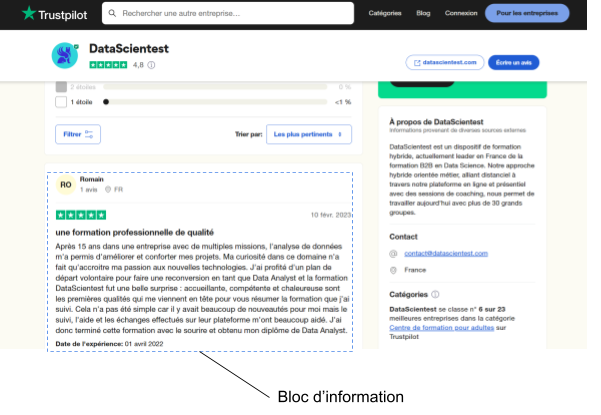
Das Ziel dieses recht manuellen Schrittes ist es einfach, nützliche Informationen zu finden und die dazugehörigen HTML-Tags zu identifizieren. Wenn wir uns auf einen Beitrag konzentrieren (unten) :

Wir werden uns mit den unten stehenden Informationen beschäftigen:
- Der Kommentar
- Das Datum des Kommentars
- Das Datum der Ausbildung
- Der Titel des Kommentars
- Die Anmerkung
Um auf den HTML-Code der Seite zuzugreifen, klickst du (im Edge- oder Firefox-Browser) einfach mit der rechten Maustaste auf die Seite und klickst auf die Option inspizieren. Auf der rechten Seite werden die verschiedenen Tags angezeigt, die den verschiedenen Elementen der Seite zugeordnet sind.
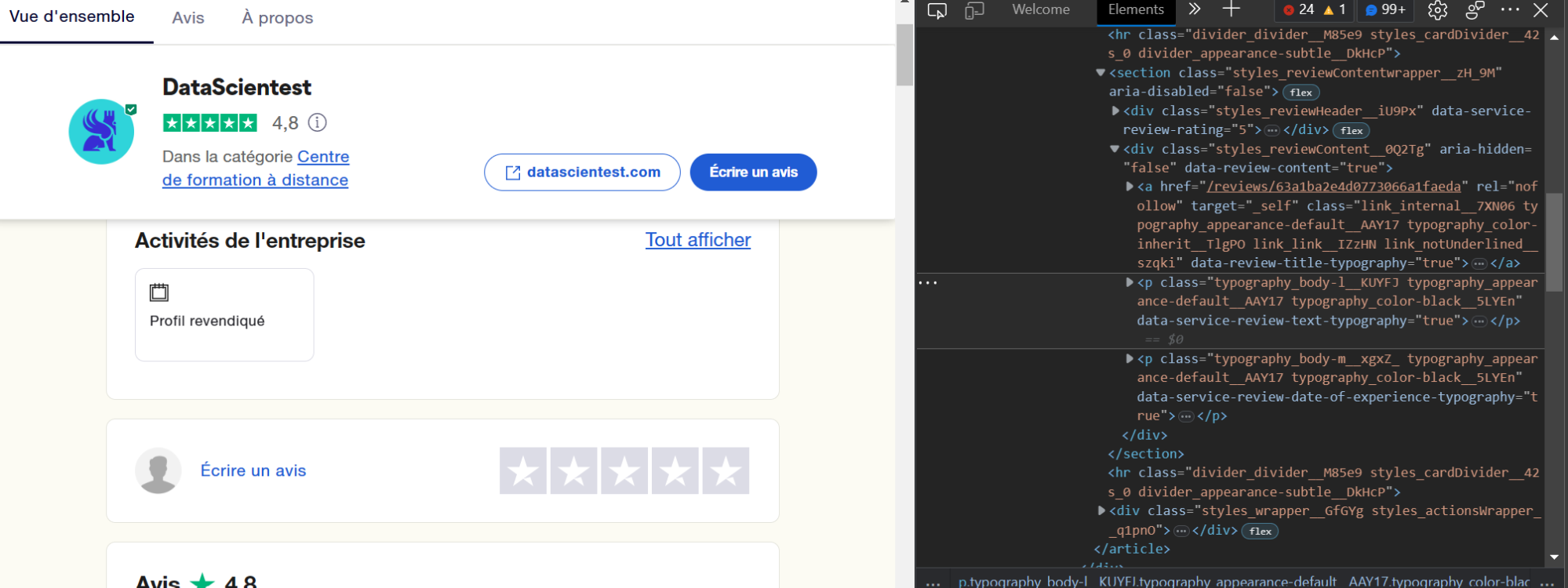
Um direkt auf den Tag zuzugreifen, der mit einem bestimmten Element verknüpft ist, wähle einfach das Element aus und wiederhole die vorherige Manipulation (Rechtsklick + inspizieren).
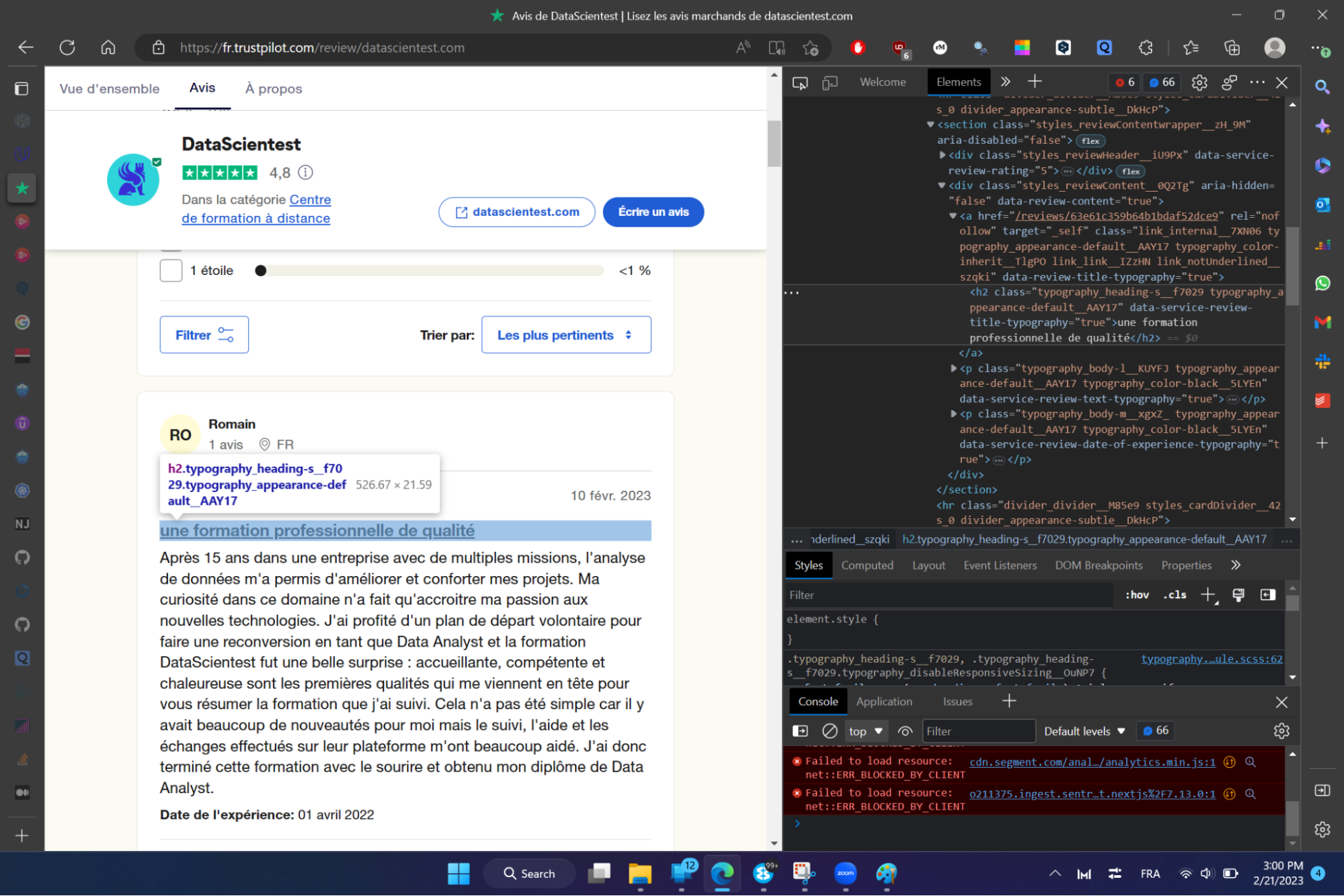
Um z. B. das Tag für den Titel zu erhalten, kannst du nach der Manipulation das Haupt-Tag für den Titel des nebenstehenden Kommentars lesen: .typography_heading-s__f7029. Dies ist ein CSS-Tag (man spricht auch von einem CSS-Selektor), aus dem nur der Text extrahiert werden kann.
Dieser Vorgang wird für alle Elemente, die du extrahieren willst, wiederholt, um jedem Element das entsprechende CSS-Tag zuzuordnen.
Schritt 2: Experimentieren mit der Scrapy Shell
Sobald die Tags eindeutig identifiziert sind, können wir die Scrapy-Eingabeaufforderung betreten, um die Befehle zum Extrahieren vollständig zu definieren.
Um die Scrapy Shell zu betreten, geben wir den folgenden Befehl ein (nachdem wir die virtuelle Umgebung aktiviert haben):
# Öffnet die Scrapy Shell auf der trustpilot-Website.
scrapy shell „https://fr.trustpilot.com/review/datascientest.com“.
Der obige Befehl ermöglicht Folgendes:
- Alle Elemente der angegebenen Seite mithilfe der Scrapy-API abrufen.
- Diese Elemente werden in einer Variablen „response“ gespeichert.
- Scrapy Shell öffnen
In der Variablen „response“ können wir mithilfe der CSS-Selektoren, die wir im vorherigen Schritt identifiziert haben, die Informationen, nach denen wir suchen, genau abrufen.
Um die Informationen auf einfache und iterative Weise zu extrahieren (und sicherzustellen, dass die Informationen, die mit jedem Kommentar verbunden sind, einfach abgerufen werden), ist das erste Element, das wir extrahieren werden, die Liste aller Informationsblock-Selektoren auf einer Seite.
Der CSS-Selektor, der einem Block zugeordnet ist, lautet wie folgt: .styles_reviewContentwrapper__zH_9M‘.
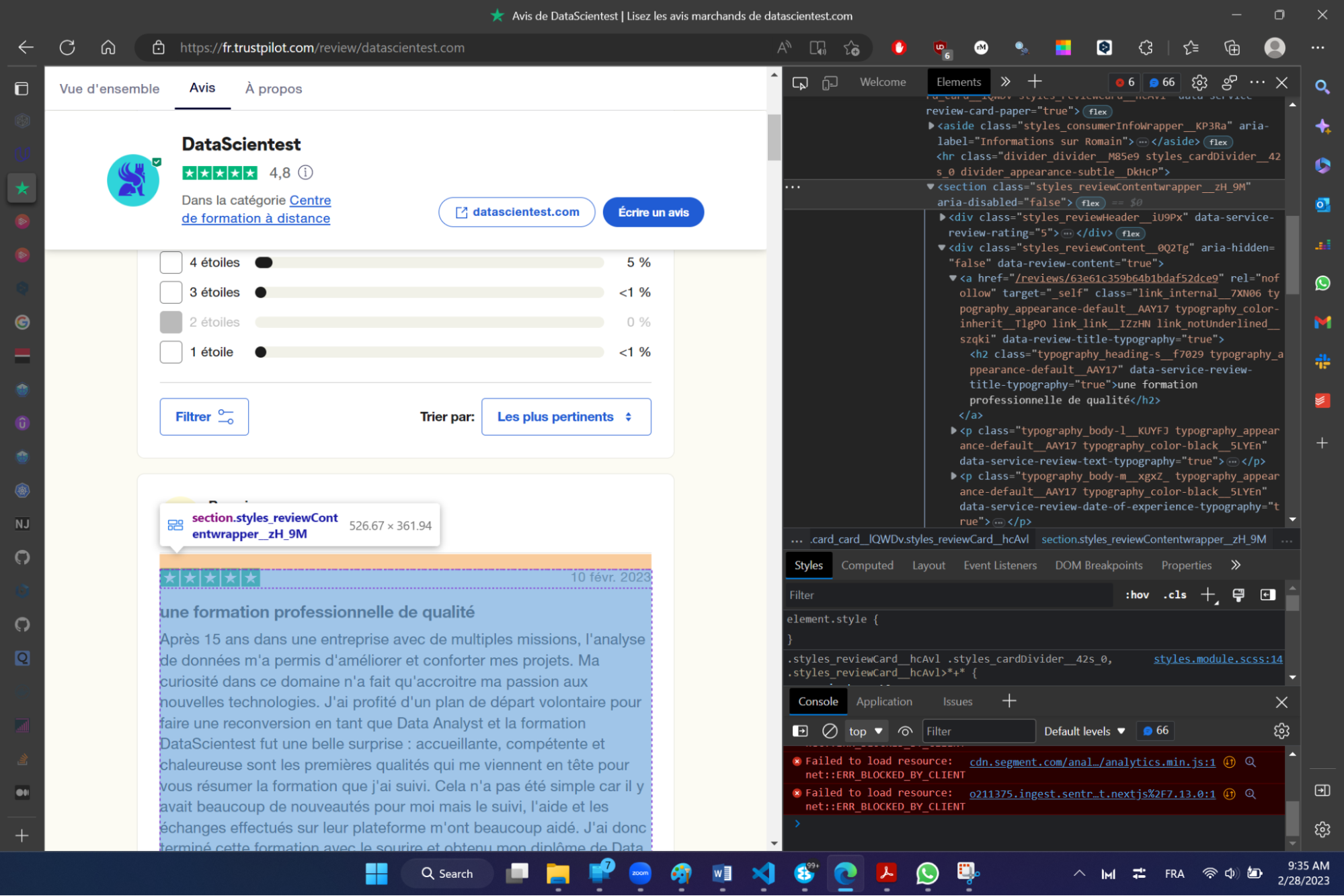
Wir können dann den folgenden Befehl in der Scrapy-Shell ausführen, um die Liste aller Blöcke zu extrahieren.
# Extrahiere alle Blöcke.
response.css(‚.styles_reviewContentwrapper__zH_9M‘))
Als Ausgabe erhält man das folgende Ergebnis:
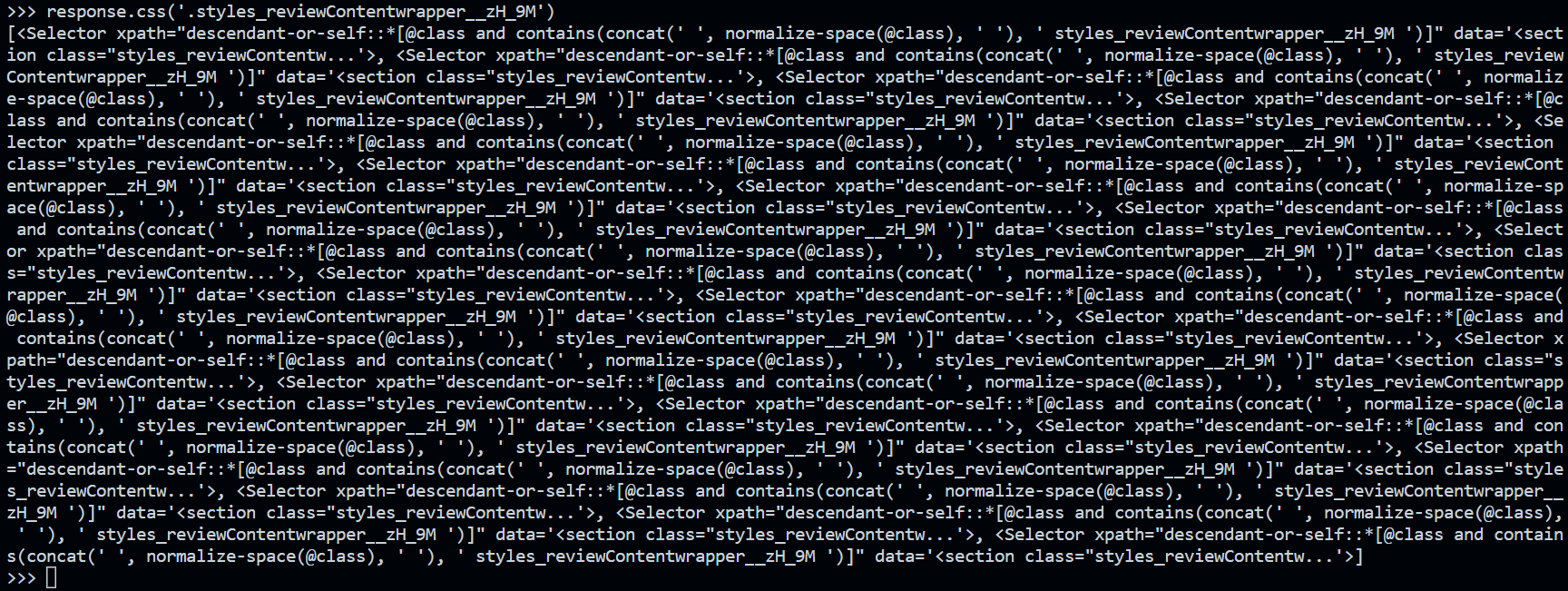
Dies ist eine Liste von Selektoren, die es ermöglichen, die in jedem Block enthaltenen Daten mithilfe jedes einzelnen Elements der Liste abzurufen. Wir können dann alles, was wir brauchen, mit den folgenden Codezeilen abrufen (jede Zeile muss separat in der Scrapy-Shell ausgeführt werden):
# Abruf aller Informationsgruppen
selectors = response.css(‚.styles_reviewContentwrapper__zH_9M‘)
# die Bewertung eines Elements abrufen
selectors[0].css(‚img::attr(alt)‘).extract()
# Extrahiere den Titel auf einem Element.
selectors[0].css(‚.typography_heading-s__f7029::text‘).extract()
# Kommentar und Datum auf einem Element
elt = selectors[0].css(‚.typography_color-black__5LYEn::text‘).extract()
exp_date = elt[-1].
comment = “.join([word for word in elt[:-1]])
# Extrahiere das Datum des Kommentars (einen Tag versetzt zu dem, was angezeigt wird).
selectors[0].css(‚div.typography_body-m__xgxZ_.typography_appearance-subtle__8_H2l.styles_datesWrapper__RCEKH > time::text‘).extract()
Schritt 3: Erstellen eines Scrapy-Projekts
Sobald das Prototyping der Scrapy-Codezeilen abgeschlossen ist, kann man leicht eine Spider-Klasse erstellen, die einfach nur alle oben genannten Codezeilen in einer einzigen Python-Datei zusammenfasst.
Scrapy bietet native Funktionen zum Initialisieren eines Scrapy-Projekts (und damit auch zum Initialisieren der Spider-Klassendateien). Um ein Scrapy-Projekt zu erstellen, führe einfach den folgenden Befehl in der Shell aus:
# Erstelle ein Projekt (Beispiel Projekt trustdst).
scrapy startproject trustdst
Nach der Ausführung siehst du dann :

Der soeben ausgeführte Befehl hat einen Ordner mit initialisierten Python-Dateien erstellt. Wir können dann die folgende Architektur sehen :
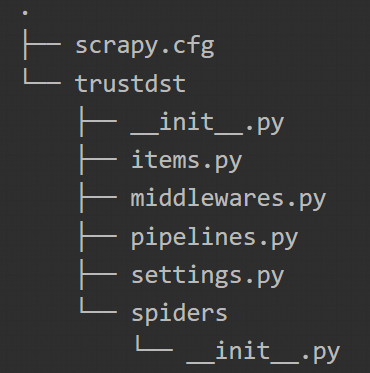
Schritt 4: Erstellen des Spiders
Wir werden uns auf die im vorherigen Schritt erstellte Architektur stützen, um die Python-Klassendatei zu erstellen, mit der wir alle Informationen einer Seite auf einmal extrahieren können. Auch hier wird Scrapy uns erlauben, die Datei mit dem folgenden Befehl zu initialisieren:
# Erstelle die Klasse Scraping Spider.
scrapy genspider trustpilotspider de.trustpilot.com/review/datascientest.com
Mit diesem Befehl wird die Datei trustpilotspider.py erstellt, die wir bearbeiten und für das Scraping von Daten verwenden werden.
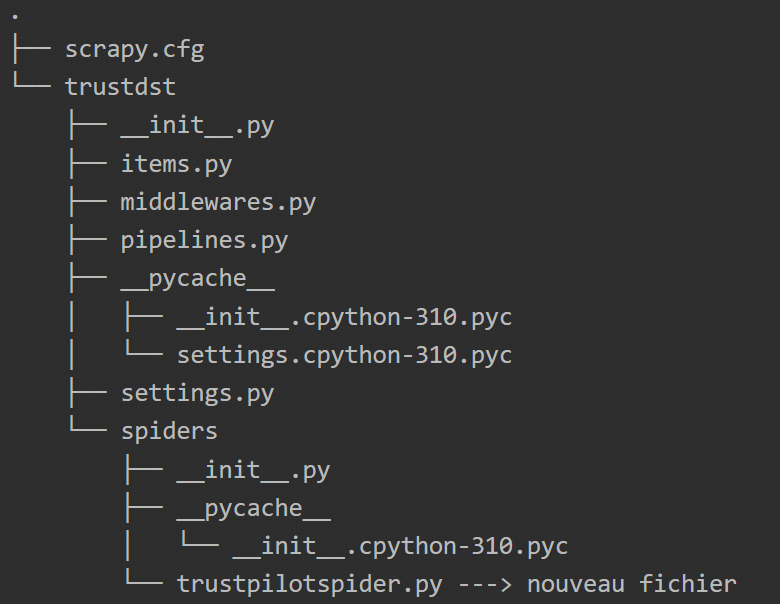
Du kannst die Datei dann wie folgt bearbeiten:
# import von scrapy
import scrapy
# Definition des Sipders
class TrustpilotspiderSpider(scrapy.Spider):
„““
name: Ein Klassenattribut, das dem Spider einen Namen gibt.
Wir werden dies verwenden, wenn wir unseren Spider später scrapy crawl laufen lassen.
<spider_name>.
allowed_domains: ein Klassenattribut, das Scrapy mitteilt, dass es
nur Seiten der Domäne chocolate.co.uk crawlen soll.
Dies verhindert, dass der Spider weitergeht.
star_urls: ein Klassenattribut, das Scrapy die erste Url
er scrape sollte. Wir werden dies in Kürze ändern.
parse: Die Parse-Funktion wird aufgerufen, nachdem eine Antwort von
von der Zielwebsite abgerufen wird.
„““
name = „trustpilotspider“.
allowed_domains = [„de.trustpilot.com“].
start_urls = [„https://fr.trustpilot.com/review/datascientest.com“] # Umbruch der URL.
def parse(self, response):
„““
Modul zum Abrufen von Informationen
„““
# Schleife über alle Informationsblöcke.
selectors = response.css(‚.styles_reviewContentwrapper__zH_9M‘)
# Iterative Extraktion der Informationen
for selector in selectors:
# Die Informationen, die zurückgegeben werden sollen
yield{
’notes‘: selector.css(‚img::attr(alt)‘).extract(),
‚titel‘: selector.css(‚.typography_heading-s__f7029::text‘).get(), # .extract()[0].
‚exp_date‘: selector.css(‚.typography_color-black__5LYEn::text‘).extract()[-1],
‚comments‘: “.join([text for text in selector.css(‚.typography_color-black__5LYEn::text‘).extract()[:-1]]),
‚comment_date‘: selector.css(‚div.typography_body-m__xgxZ_.typography_appearance-subtle__8_H2l.styles_datesWrapper__RCEKH > time::text‘).get()
}
Um die Datei auszuführen, führe einfach den folgenden Befehl aus:
scrapy crawl trustpilotspider ou scrapy crawl trustpilotspider -O myonepagescrapeddata.json
(wenn man das Ergebnis in einer JSON-Datei speichern möchte)
Fazit
Daten gehören zu den wertvollsten Vermögenswerten, die ein Unternehmen besitzen kann. Sie sind das Herzstück von Data Science und Datenanalyse. Unternehmen, die aktiv Daten sammeln, können einen Wettbewerbsvorteil gegenüber Unternehmen entwickeln, die dies nicht tun. Mit ausreichenden Daten können Organisationen die Ursachen von Problemen besser bestimmen und fundierte Entscheidungen treffen.
Es gibt Szenarien, in denen eine Organisation möglicherweise nicht über genügend Daten verfügt, um daraus die notwendigen Lehren zu ziehen. Dies ist z. B. bei einigen Start-up-Unternehmen der Fall, die fast immer ohne Daten beginnen. Eine Lösung für solche Fälle ist der Einsatz einer Datenerfassungstechnik wie Web Scraping.
Scrapy ist ein Open-Source-Framework mit einer großen Community, mit dem man effizient Daten aus dem Web extrahieren kann. Es eignet sich daher vollständig für große Web-Scraping-Projekte, da es eine klare Struktur und Instrumente zur Verarbeitung der abgerufenen Informationen bereitstellt.
Dieser Artikel sollte lediglich Scrapy mit einigen seiner grundlegenden Funktionen vorstellen, die von Data Engineers, Data Scientists oder Data Analysts zum Extrahieren von Informationen verwendet werden.
Si vous souhaitez aller plus loin avec Scrapy n’hésitez pas à consulter la documentation officielle : Scrapy Tutorial — Scrapy 2.8.0 documentation. Pour en apprendre davantage sur les technologies et les méthodologies d’acquisition de l’information, n’hésitez pas à consulter les formations de DataScientest.







