Verteilte Architekturen sind Informationssysteme, die verfügbare Ressourcen verteilen und nutzen, die sich nicht am gleichen Ort oder auf dem gleichen Rechner befinden. In diesem Artikel erklären wir ausführlich, was diese Architekturen sind, welche Vorteile sie gegenüber anderen Architekturen haben und wie sie in der Praxis in der Data Science eingesetzt werden.
Was ist eine verteilte Architektur?
Mit der exponentiellen Entwicklung der Technologie und der Erleichterung des Zugangs zu Informationen werden immer mehr Computersysteme wie Anwendungen oder deren Einsatz über ein Netzwerk miteinander verbunden und kommunizieren Daten. Um ein komplexes System zu realisieren, das die Ausführung mehrerer miteinander verbundener Dienste erfordert, sind monolithische Architekturen daher unbrauchbar und veraltet geworden.
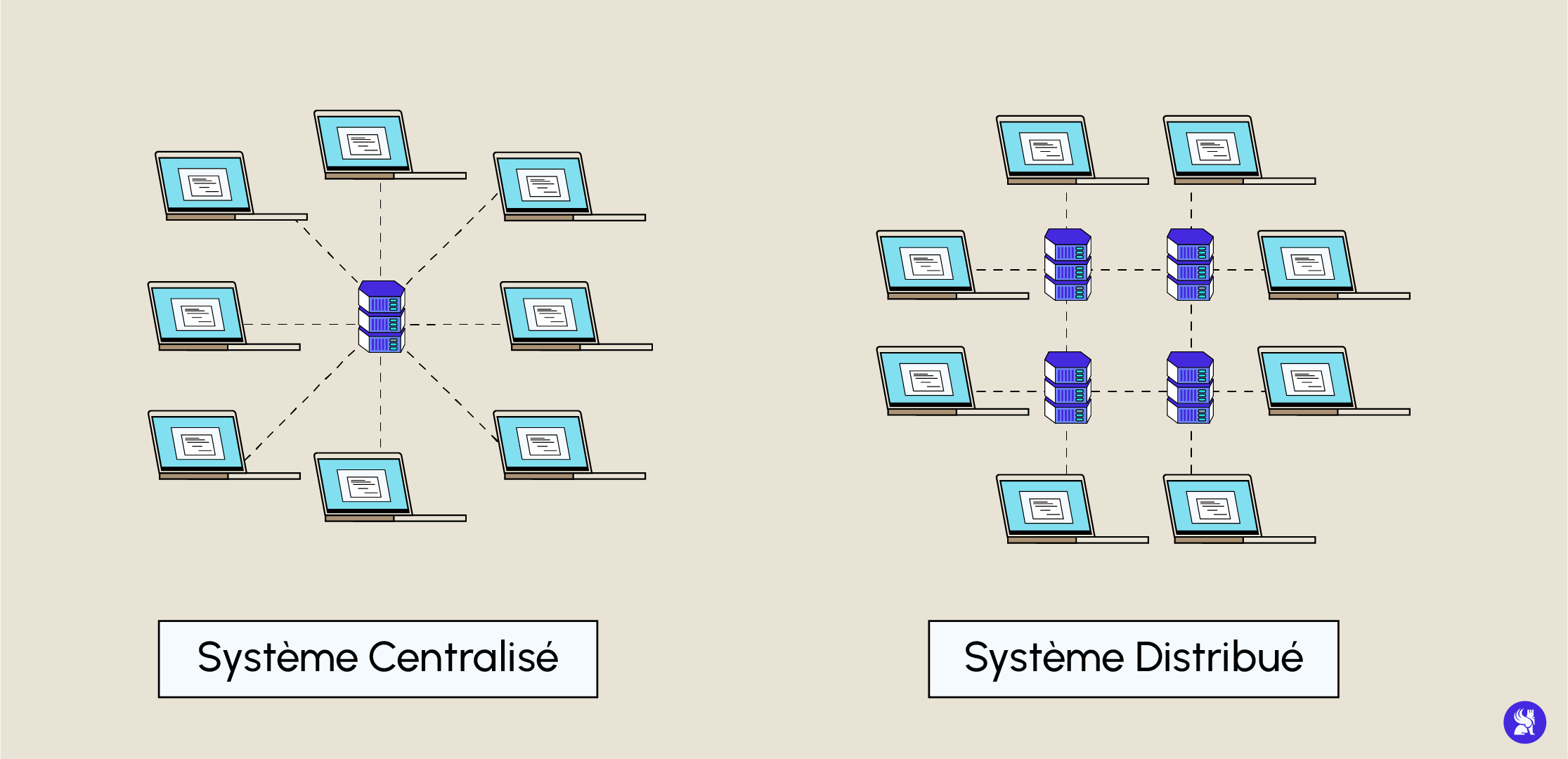
In einer solchen Architektur befinden sich alle verfügbaren Ressourcen am gleichen Ort und auf dem gleichen Rechner, und wenn du einen Teil davon ändern willst, musst du alle Teile ändern (damit sie zusammenhängend bleiben), was in einem System, in dem potenziell Tausende von Diensten miteinander kommunizieren, nicht möglich ist.
Um die Grenzen der monolithischen Architektur zu überwinden, kann man eine verteilte Architektur verwenden, aber was genau ist das?
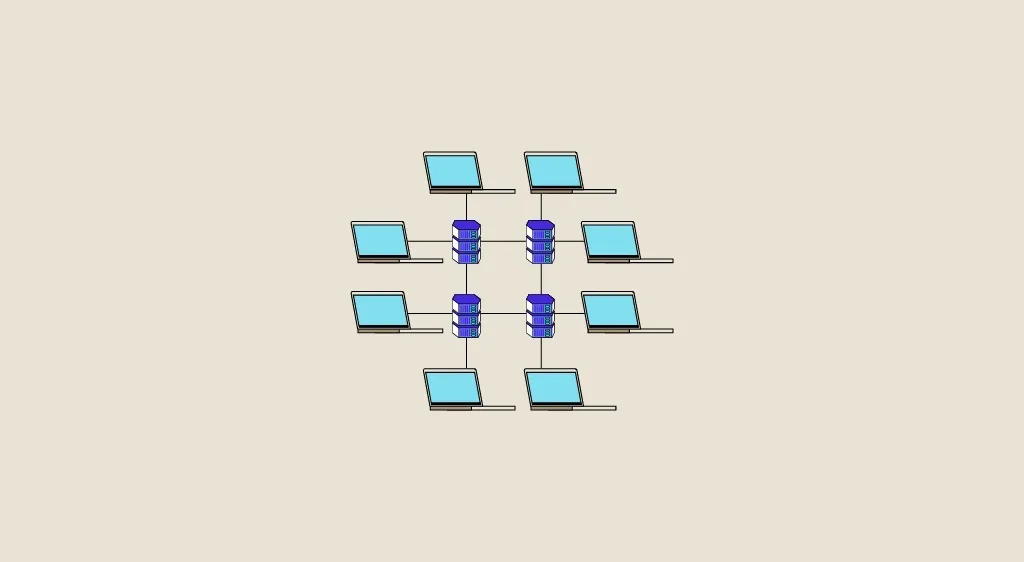
Eine verteilte Architektur ist eine Architektur, die sich genau entgegengesetzt zu einer monolithischen Architektur organisiert. Während eine monolithische Architektur alle Ressourcen und Systeme an einem Ort und auf demselben Rechner zentralisiert, nutzt eine verteilte Architektur Ressourcen, die auf verschiedenen Rechnern an verschiedenen Orten verfügbar sind. Eine solche Architektur kann sowohl ein Informationssystem als auch ein Netzwerk oder beides sein. Das Internet ist ein Beispiel für ein verteiltes Netzwerk, da es keinen zentralen Knotenpunkt hat und auf verschiedene Ressourcen zugreift, die auf mehrere Knotenpunkte verteilt sind (über das Netzwerk verteilt), die über Nachrichten über das Netzwerk kommunizieren. Ein Merkmal verteilter Architekturen ist, dass jeder Knoten Client-Server-Funktionen bereitstellen kann, d. h. er kann sowohl als Anbieter als auch als Verbraucher von Diensten oder Ressourcen fungieren. Man hat also Zugriff auf eine vollständige gemeinsame Nutzung von Ressourcen.
Vor etwa 50 Jahren erforderte es genaue Kenntnisse der Netzwerkprotokolle und manchmal sogar der Netzwerkhardware, um zwei Maschinen über das Netzwerk miteinander kommunizieren zu lassen. Mit der Einführung der objektorientierten Programmierung wichen die monolithischen Architekturen den verteilten Architekturen, die nun dank neuer High-Level-Bibliotheken, die es verschiedenen Rechnern ermöglichen, mehrere Objekte, die auf verschiedenen Rechnern laufen, miteinander in Dialog zu bringen, praktikabel geworden sind.
So beruhen verteilte Architekturen auf der Möglichkeit, über das Netzwerk verteilte Objekte zu verwenden. Die über das Netzwerk verteilten Objekte (die sich nicht am selben Ort befinden) kommunizieren über Nachrichten und stützen sich dabei auf spezielle Technologien wie Common Object Request Broker Architecture oder CORBA, die es verschiedenen Objekten, die in unterschiedlichen Sprachen wie C++ oder Java geschrieben sind, ermöglichen, miteinander zu kommunizieren. Ein weiteres bekanntes Werkzeug ist die Java EE-Software, die es ermöglicht, mehrere Objekte in einer verteilten Architektur mithilfe ihres Katalogs an spezialisierten Bibliotheken miteinander kommunizieren zu lassen.
Heutzutage rührt einer der Nachteile dieser Art von Architektur paradoxerweise von ihrer ursprünglichen Stärke her: der Isolation der verschiedenen Abteilungen und damit der Entwicklerteams, die unabhängig voneinander an ihnen arbeiten.
Aufgrund der potenziellen geografischen Entfernung, der Heterogenität der Aufgaben und der Isolation der technischen Verantwortlichkeiten ist die verteilte Architektur anfällig für schlechte Wartbarkeit, was ernsthafte Auswirkungen auf die Kosten oder die Funktionalität der Dienste haben kann. Wenn du unkontrolliert und unabhängig voneinander „Bausteine“ übereinander stapelst, besteht die Gefahr exponentieller Fehlentwicklungen.
Die Architektur würde dann sofort ihre Fähigkeit verlieren, die verschiedenen entwickelten Dienste und ihre Verbindungen untereinander schnell zu verstehen.
Beziehung zwischen Big Data und verteilter Architektur
Es ist wichtig zu wissen, dass in einer Big-Data-Architektur die Verteilung ein Schlüsselelement ist. Früher hatten wir ein System der vertikalen Skalierbarkeit, d. h. man fügte RAM, CPU usw. hinzu, um alle Probleme zu lösen, die mit der Speicherung oder der Rechenleistung der Computer zusammenhingen. Das Problem war, dass dies sehr teuer war und dass man Hardware verwendete, die dazu bestimmt war, weggeworfen zu werden.
Seit dem Aufkommen von Big Data sind wir zu einer Architektur der horizontalen Skalierbarkeit übergegangen, um dieses Problem zu lösen. Das bedeutet, dass man bevorzugt Computer in eine Architektur einbaut, um die Probleme von Big Data zu lösen. Diese Architektur hat einige Vorteile. Zunächst einmal werden alle Daten mit einem bestimmten Replikationsfaktor repliziert und auf den verschiedenen Rechnern partitioniert.
Dies führt zu einer erhöhten Sicherheit auf der Ebene der Daten. Da wir verschiedene Maschinen verwenden, sind außerdem die Berechnungen in einer verteilten Architektur parallelisierbar, also gewinnen wir an Rechengeschwindigkeit und die Rechenleistung wird erhöht. Schließlich ist auch die Skalierung einfacher. Angenommen, wir haben keinen Speicherplatz mehr in unseren Maschinen, dann können wir, anstatt den Computer gegen einen leistungsstärkeren auszutauschen (vertikale Skalierbarkeit), unsere Architektur um eine Maschine erweitern, wodurch das Speicherproblem gelöst wird.
Insbesondere in der Data Science, um erfolgreich Berechnungen mit einer verteilten Architektur durchzuführen und die Speicherung zwischen den verschiedenen Knoten dieser verteilten Architektur zu verwalten, wird hauptsächlich Hadoop verwendet.
Dieses Framework besteht aus drei Unterframeworks:
HDFS ist der Speichermanager in Hadoop. Es ermöglicht die Speicherung der verschiedenen Partitionsblöcke auf den verschiedenen Knoten der verteilten Architektur.
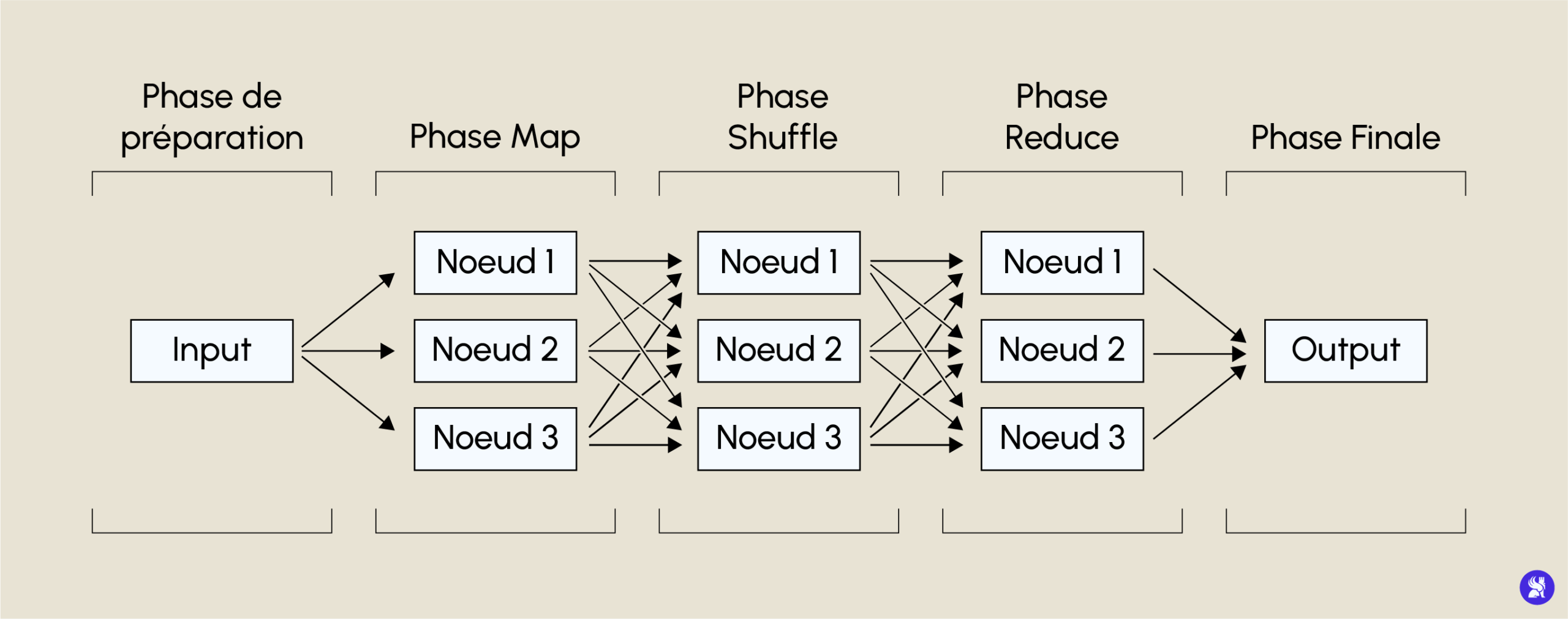
MapReduce ist das Rechensystem in einer verteilten Architektur. Es führt parallele Berechnungen auf den verschiedenen Knoten der Architektur durch, um ein Endergebnis zu erhalten. Es funktioniert in Form von Schlüssel/Werten mit verschiedenen Phasen. Die erste ist die Mapping-Phase, in der die Anfrage anhand eines Schlüssels über alle Blöcke unseres Dokuments aggregiert wird.
Danach folgt die Shuffle-Phase, in der die Ergebnisse der verschiedenen Aggregationen nach diesem Schlüssel sortiert werden. Dann gibt es die Reduktionsphase, in der die Anfrage (z. B. eine Summe) auf unsere verschiedenen sortierten Schlüssel angewendet wird. Schließlich gibt es noch die letzte Phase, in der unsere verschiedenen Reduktionen erneut in einem einzigen Knoten zusammengefasst werden.
Das dritte Subframework, YARN, ist der Orchestrierungsmanager von Hadoop. Er weiß, wie die Daten repliziert werden, wie die verschiedenen Blöcke an die verschiedenen Knoten gesendet werden und welche Partition für MapReduce verwendet werden soll.
Hadoop ist natürlich nur eines von vielen Werkzeugen, die es für den Aufbau verteilter Architekturen gibt. Ein weiteres, viel genutztes Werkzeug heißt Spark und ist in verschiedenen Programmiersprachen verfügbar: Scala, Python, Java und R.
Wenn du mehr über verteilte Architekturen und ihre Verwendung erfahren möchtest, kannst du gerne einen Termin mit unseren Experten vereinbaren, um mehr über Data Science zu erfahren und um Informationen über unseren Data Engineer-Kurs zu erhalten, dessen Broschüre du hier findest!







