MapReduce ist das Programmiermodell des Hadoop-Frameworks. Es ermöglicht die Analyse riesiger Mengen von Big Data durch parallele Verarbeitung. Hier erfährst Du alles, was Du wissen musst: Einführung, Funktionsweise, Alternativen, Vorteile, Weiterbildungen…
Die riesigen Mengen in Zeiten von Big Data bieten zahlreiche Chancen für Unternehmen. Allerdings kann es schwierig sein, diese Daten mit herkömmlichen Systemen schnell und effizient zu verarbeiten. Daher ist es notwendig, auf neue, speziell für diesen Zweck entwickelte Softwarelösungen zurückzugreifen.
Das Programmiermodell MapReduce gehört dazu. Es wurde ursprünglich von Google entwickelt, um die Ergebnisse seiner Suchmaschine zu analysieren. Im Laufe der Zeit wurde dieses Tool aufgrund seiner Fähigkeit, enorme Datenmengen zu zerlegen und parallel zu verarbeiten, äußerst beliebt. Dieser Ansatz liefert schnellere Ergebnisse.
💡Auch interessant:
Was ist MapReduce?
Das Programmiermodell MapReduce ist eine der Hauptkomponenten des Hadoop-Frameworks. Es wird verwendet, um auf Big Data zuzugreifen, die innerhalb des Hadoop File System (HDFS) gespeichert sind.
Der Vorteil von MapReduce besteht darin, dass es die gleichzeitige Verarbeitung von Daten erleichtert. Um dies zu erreichen, werden große Datenmengen in der Größenordnung von mehreren Petabytes in kleinere Teile zerlegt.
Diese Datenstücke werden parallel auf Hadoop-Servern verarbeitet. Nach der Verarbeitung werden die Daten von den verschiedenen Servern zusammengefasst, um ein einheitliches Ergebnis an die Anwendungssoftware zu übertragen.
Hadoop ist in der Lage, MapReduce-Programme auszuführen, die in verschiedenen Sprachen geschrieben sind: Java, Ruby, Python, C++…
Der Datenzugriff und die Datenspeicherung sind festplattenbasiert. Der Input sowie der Output werden in Form von Dateien gespeichert. Sie enthalten strukturierte, halbstrukturierte oder unstrukturierte Daten.
Nehmen wir als Beispiel einen Datensatz von 5 Terabyte. Verteilt man die Verarbeitung auf einen Hadoop-Cluster mit 10.000 Servern, muss jeder Server etwa 500 Megabyte an Daten verarbeiten. Der gesamte Datenbestand kann also viel schneller verarbeitet werden als bei einer herkömmlichen sequentiellen Verarbeitung.
Grundsätzlich ermöglicht MapReduce, die Logik direkt auf dem Server auszuführen, auf dem sich die Daten befinden. Diese Vorgehensweise unterscheidet sich von dem Ansatz, bei dem die Daten an jenen Speicherort gesendet werden, an dem sich die Logik oder die Anwendung befindet. Dadurch wird die Verarbeitung beschleunigt.
Alternativen zu MapReduce: Hive, Pig...
Früher war MapReduce die einzige Methode, um die in HDFS gespeicherten Daten abzurufen. Dies ist heute nicht mehr der Fall. Es gibt andere, auf Abfragen basierende Systeme wie Hive und Pig.
Diese ermöglichen es, Daten aus HDFS mithilfe von SQL-Abfragen abzurufen. Meistens werden sie jedoch parallel zu Aufträgen ausgeführt, die mit dem MapReduce-Modell geschrieben wurden, um dessen vielfältige Vorteile zu nutzen.
Wie funktioniert MapReduce?
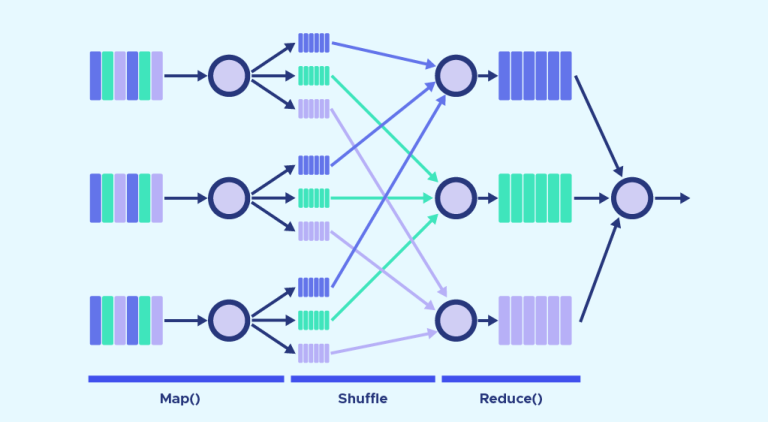
Die Funktionsweise von MapReduce dreht sich hauptsächlich um zwei Funktionen: Map und Reduce. Einfach ausgedrückt: Map dient dazu, Daten zu zerlegen und abzubilden. Reduce mischt und reduziert die Daten.
Diese Funktionen werden nacheinander ausgeführt. Um die Server zu kennzeichnen, die die Funktionen Map und Reduce ausführen, werden die Begriffe Mappers und Reducers verwendet. Es kann sich jedoch auch um die gleichen Server handeln.
Die Map-Funktion
Die Inputdaten werden in kleinere Blöcke zerlegt. Jeder dieser Blöcke wird für die Verarbeitung einem „Mapper“ zugewiesen.
Nehmen wir als Beispiel eine Datei mit 100 Datensätzen, die verarbeitet werden sollen. Es ist möglich, 100 Mapper gleichzeitig zu verwenden und damit jeden Datensatz einzeln zu verarbeiten. Es können jedoch auch jedem Mapper mehrere Datensätze zugeteilt werden.
In der Praxis übernimmt das Hadoop-Framework die automatische Entscheidung, wie viele Mapper verwendet werden sollen. Diese Entscheidung hängt von der Größe der zu verarbeitenden Daten und den auf jedem Server verfügbaren Speicherblöcken ab.
Die Map-Funktion erhält den Input von der Festplatte in Form von Schlüssel-Wert-Paaren. Diese Paare werden verarbeitet und dadurch ein weiterer Satz von Schlüssel-Wert-Paaren wird als Zwischenergebnis erzeugt.
Die Reduce-Funktion
Nachdem alle Mapper ihre Verarbeitungsaufgaben abgeschlossen haben, mischt und organisiert das Framework die Ergebnisse. Anschließend werden sie an die „Reducer“ weitergeleitet. Ein Reducer kann nicht gestartet werden, solange ein Mapper noch aktiv ist.
Die Reduce-Funktion erhält ebenfalls Inputs in Form von Schlüssel-Wert-Paaren. Alle Werte, die von einer Map mit demselben Schlüssel erzeugt werden, werden einem einzigen Reducer zugewiesen. Dieser übernimmt die Aufgabe, die Werte für diesen Schlüssel zu vereinen. Reduce erzeugt dann einen endgültigen Output, ebenfalls in Form von Schlüssel/Wert-Paaren.
Die Art der Schlüssel und Werte variiert jedoch je nach Anwendungsfall. Alle Inputs und Outputs werden im HDFS gespeichert. Es sei darauf hingewiesen, dass die Funktion Map zwingend erforderlich ist, um die Ausgangsdaten zu filtern und zu sortieren. Die Funktion Reduce ist dagegen optional.
Kombinieren und Partitionieren
Es gibt zwei Zwischenstufen zwischen Map und Reduce. Diese beiden Schritte werden Combine und Partition genannt.
Der Combine-Prozess ist optional. Ein Combine ist ein Reducer, der individuell auf jedem Mapper-Server ausgeführt wird. Dadurch wird eine weitere Reduzierung der Daten auf jedem Mapper in vereinfachter Form ermöglicht. Dank der reduzierten Datenmenge wird so das Shuffling und die Verwaltung erleichtert.
Im Rahmen der Partition wiederum werden die von den Mappern erzeugten Key-Value-Paare in einen anderen Satz von Key-Value-Paaren übersetzt, bevor sie an den Reducer weitergeleitet werden. Dieser Prozess entscheidet, wie die Daten dem Reducer übermittelt werden sollen und weist sie einem bestimmten Reducer zu.
Der Standardpartioner bestimmt den Hash-Wert für den vom Mapper erzeugten Schlüssel und weist ihm anhand dieses Wertes eine Partition zu. Die Anzahl der Partitionen entspricht der Anzahl der Reducer. Sobald die Partitionierung abgeschlossen ist, werden die Daten aus jeder Partition an einen bestimmten Reducer gesendet.
Beispiele für Anwendungsfälle
Das Programmierparadigma MapReduce ist ideal für jedes komplexe Problem, das durch Parallelisierung gelöst werden kann. Es ist daher ein geeigneter Ansatz für Big Data.
Unternehmen können MapReduce nutzen, um den optimalen Preis für ihre Produkte zu ermitteln oder um herauszufinden, wie effektiv eine Werbekampagne ist. Außerdem können sie Klicks, Online-Verkäufe oder Twitter-Trends analysieren, um zu entscheiden, welches Produkt sie auf den Markt bringen sollten, um die Nachfrage der Verbraucher zu befriedigen.
Während diese Berechnungen früher sehr kompliziert waren, macht MapReduce sie heute einfach und für jeden umsetzbar. Sie können auf einem kostengünstigen Servernetzwerk ausgeführt werden, wodurch auch die Verarbeitung von Big Data wesentlich günstiger wird.
Was sind die Vorteile von MapReduce?
Die Verwendung von MapReduce hat viele Vorteile. Zunächst einmal macht dieses Programmiermodell Hadoop hochgradig skalierbar, indem es die Speicherung großer Datensätze auf mehreren Servern ermöglicht.
Dadurch wird die Parallelverarbeitung erst möglich. Map- und Reduce-Aufgaben sind voneinander getrennt. Die parallele Ausführung reduziert die gesamte Bearbeitungszeit.
Außerdem handelt es sich um eine kostengünstige Methode zur Speicherung und Verarbeitung von Daten. Das Preis-Leistungs-Verhältnis ist unübertroffen.
Gepaart mit MapReduce ist Hadoop auch extrem flexibel. So können Daten aus verschiedenen Quellen und sogar unstrukturierte Daten gespeichert und verarbeitet werden.
Auch die Geschwindigkeit ist eine besondere Stärke. Durch das verteilte Dateisystem werden die Daten auf der lokalen Festplatte eines Clusters und die MapReduce-Programme auf denselben Servern gespeichert. Dadurch können die Daten schneller verarbeitet werden, da ein Zugriff von anderen Servern aus nicht erforderlich ist.
Wie lerne ich den Umgang mit MapReduce?
Unternehmen in allen Branchen sammeln immer mehr größere Datenmengen. Um daraus Nutzen zu ziehen, müssen sie diese Daten verarbeiten. Dafür ist MapReduce eine der führenden Anwendungen.
Daher eröffnet der Umgang mit Hadoop und MapReduce viele berufliche Möglichkeiten. Es handelt sich schließlich um eine sehr geschätzte Fachkompetenz.
Um den Umgang mit diesem Tool zu erlernen, können Sie sich an DataScientest wenden. Das Hadoop-Framework und seine verschiedenen Module stehen im Fokus unserer Data-Engineer-Weiterbildung innerhalb des Moduls Big Data Volume.
Sie lernen insbesondere den Umgang mit Hadoop, Hive, Pig, Hbase und Spark und erfahren alles über den theoretischen Aspekt von Big-Data-Architekturen. Die anderen Module dieses Kurses befassen sich mit der Programmierung in Python, Datenbanken, Big Data Velocity und schließlich mit den Themen Automatisierung und Implementierung.
Nach Abschluss dieses Kurses verfügen Sie über alle erforderlichen Fähigkeiten, um sofort als Data Engineer eingesetzt zu werden. Dieser Beruf erlebt einen Aufschwung und verspricht Ihnen einen Arbeitsplatz mit hohem Gehalt in dem von Ihnen gewählten Bereich.
Wie alle unsere Weiterbildungen verfolgt auch der Kurs Data Engineer einen Blended-Learning-Ansatz, der Präsenzunterricht und Fernunterricht miteinander verbindet. Er kann als berufsbegleitende Weiterbildung oder als Intensivkurs absolviert werden.
Nach Abschluss des Programms erhalten die Absolventen ein Zertifikat der Universität Sorbonne. 93 % unserer Alumni haben sofort einen Job gefunden. Verschwenden Sie also keine weitere Zeit und entdecke die Weiterbildung zum Data Engineer.
Du weisst alles über MapReduce. Lesen Sie unser umfassendes Dossier über Hadoop und unsere Einführung in die Programmiersprache Python.







