
Hadoop ist ein Open-Source-Framework für Speicherung und Verarbeitung von Big Data. Hier erfährst Du alles, was Du wissen musst: Definition, Geschichte, Funktionsweise, Vorteile, Weiterbildungen…
Mehrere Jahrzehnte lang speicherten Unternehmen ihre Daten hauptsächlich in relationalen Datenbanken (RDBMS), um sie zu speichern und Abfragen durchzuführen. Diese Art von Datenbank kann jedoch weder unstrukturierte Daten speichern, noch ist sie für die riesigen Mengen von Big Data geeignet.
Tatsächlich haben die Digitalisierung und das Aufkommen zahlreicher Technologien wie IoT und Smartphones zu einem raschen Anstieg des Rohdatenvolumens geführt. Angesichts dieser Revolution benötigt man neue Technologien für die Speicherung und Verarbeitung von Daten. Software-Framework Hadoop erfüllt diese neuen Anforderungen.
Was ist Hadoop?
Hadoop ist ein Software-Framework für Speicherung und Verarbeitung großer Datenmengen. Es handelt sich um ein Open-Source-Projekt, das von der Apache Software Foundation gesponsert wird.
Ein Produkt ist es eigentlich nicht, sondern ein Framework, das Anweisungen für die Speicherung und Verarbeitung von verteilten Daten zusammenfasst. Verschiedene Softwarehersteller haben Hadoop genutzt, um kommerzielle Produkte zur Verwaltung von Big Data zu erstellen.
Hadoop-Datensysteme sind skalierbar, d. h. es ist möglich, mehr Hardware und Cluster hinzuzufügen, um eine höhere Last zu bewältigen, ohne, dass eine Neukonfiguration oder der Kauf teurer Softwarelizenzen erforderlich ist.
Hadoops Geschichte 📌
Hadoops Ursprung ist eng mit dem exponentiellen Wachstum des „World Wide Web“ im vergangenen Jahrzehnt verbunden. Das Web ist immer größer geworden und vereint mittlerweile mehrere Milliarden Seiten. Infolgedessen ist es schwierig geworden, effizient nach Informationen zu suchen.
Im jetzigen Zeitalter von Big Data ist es komplexer, sowohl Informationen effizient zu speichern, um sie leicht wiederzufinden, als auch Daten nach dem Speichern zu verarbeiten.
Um dieses Problem zu lösen, wurden zahlreiche Open-Source-Projekte entwickelt. Das Ziel: Suchergebnisse im Internet schneller anzubieten. Eine der Lösungen bestand darin, die Daten auf einen Cluster von Servern zu verteilen, um eine gleichzeitige Verarbeitung zu ermöglichen.
So wurde Hadoop geboren. 2002 arbeiteten Doug Cutting und Mike Caferella von Google am Open-Source-Webcrawler-Projekt Apache Nutch. Dabei stießen sie auf Schwierigkeiten bei der Speicherung der Daten und die Kosten waren extrem hoch.
Im Jahr 2003 stellte Google sein Dateisystem GFS vor: Google File System. Dabei handelt es sich um ein verteiltes Dateisystem, das einen effizienten Zugriff auf Daten ermöglichen soll. Das amerikanische Unternehmen veröffentlichte 2004 ein Whitepaper zu Map Reduce: Der Algorithmus sollte die Datenverarbeitung in großen Clustern vereinfachen. Diese Veröffentlichungen von Google haben die Entstehung von Hadoop stark beeinflusst.
Später, im Jahr 2005, enthüllten Cutting und Cafarella ihr neues Dateisystem NDFS (Nutch Distributed File System), das ebenfalls Map Reduce enthielt. Als Doug Cutting 2006 von Google zu Yahoo wechselte, baute er auf dem Nutch-Projekt auf, um Hadoop (dessen Name von einem Plüschelefanten von Cuttings Sohn inspiriert wurde) und sein HDFS-Dateisystem auf den Markt zu bringen. Die Version 0.1.0 wird veröffentlicht.
In der Folgezeit entwickelt sich Hadoop stetig weiter. Es wird 2008 zum schnellsten System, das ein Terabyte an Daten auf einem Cluster mit 900 Knoten in nur 209 Sekunden sortiert. Die Version 2.2 wird 2013 und die Version 3.0 2017 veröffentlicht.
Neben seiner Leistungsfähigkeit für Big Data hat dieses Framework auch viele unerwartete Vorteile gebracht. Vor allem hat es die Kosten für die Bereitstellung von Servern gesenkt.
Was sind die vier Module von Apache Hadoop?
Apache Hadoop basiert auf vier Hauptmodulen. Zunächst wird das Hadoop Distributed File System (HDFS) für Datenspeicherung verwendet. Es ist vergleichbar mit einem lokalen Dateisystem auf einem traditionellen Computer.
Seine Leistung ist jedoch deutlich höher. Das HDFS ist außerdem besonders elastisch. Es ist möglich, sehr leicht von einem einzelnen Rechner auf mehrere Tausend zu wechseln.
Die zweite Komponente ist der YARN (Yet Another Resource Negotiator). Der Name deutet schon darauf hin, dass es sich hier um einen Ressourcenverhandler handelt. Damit werden Aufgaben geplant, Ressourcen verwaltet und Clusterknoten und andere Ressourcen überwacht.
Das Hadoop-Modul MapReduce wiederum unterstützt Programme bei der Durchführung paralleler Berechnungen. Die Map-Task wandelt die Daten in Schlüssel-Wert-Paare um. Die Aufgabe Reduce identifiziert die Eingabedaten, nimmt sie auf und erzeugt das Ergebnis.
Das letzte Modul ist Hadoop Common. Es verwendet Standard-Java-Bibliotheken zwischen den einzelnen Modulen.
Wie wird Big Data mit Hadoop verarbeitet? 🤓
Die Verarbeitung von Big Data mit Hadoop beruht auf der Nutzung der verteilten Speicher- und Verarbeitungskapazität von Clustern. Dies ist die Grundlage für die Erstellung von Big-Data-Anwendungen.
Die Anwendungen können Daten mit verschiedenen Formaten sammeln und über eine API, die eine Verbindung zum NameNode herstellt, im Hadoop-Cluster speichern. Der NameNode erfasst die Struktur des Dateiordners und repliziert Stücke zwischen den verschiedenen DataNodes für die parallele Verarbeitung.
Datenabfragen werden von MapReduce durchgeführt, das auch alle DataNodes auflistet und die mit den Daten verbundenen Aufgaben im HDFS reduziert. Map-Aufgaben werden auf jedem Knoten ausgeführt; Reducer werden ausgeführt, um die Daten zu verknüpfen und das Endergebnis zu organisieren.
Was sind die verschiedenen Werkzeuge des Hadoop-Ökosystems?
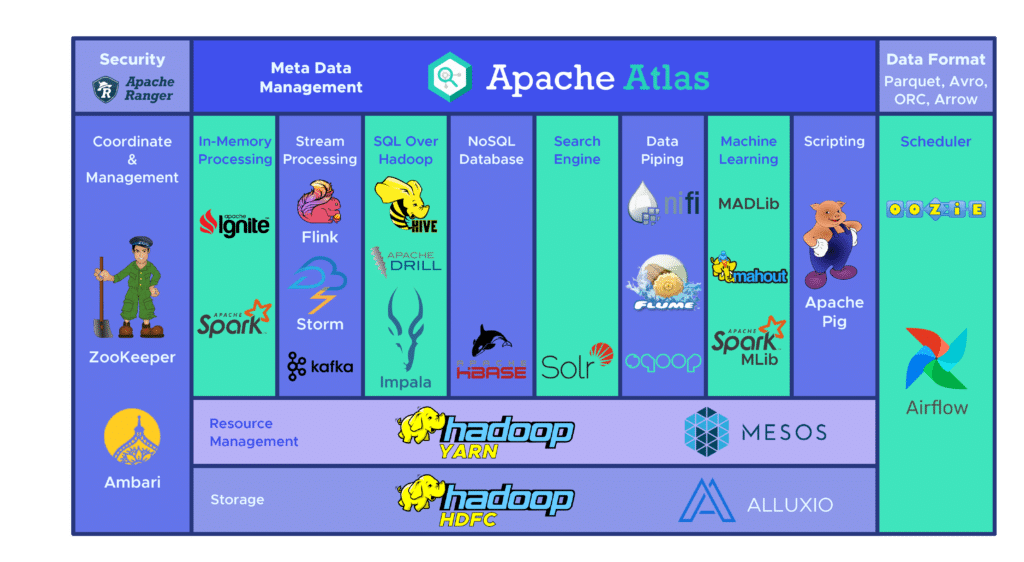
Das Hadoop-Ökosystem umfasst eine Vielzahl von Open-Source Big Data Tools. Diese verschiedenen Tools ergänzen Hadoop und verbessern die Verarbeitungskapazität von Big Data.
Zu den populärsten gehört Apache Hive, nämlich ein Data Warehouse für die Verarbeitung großer, im HDFS gespeicherter Datensätze. Das Tool Zookeeper automatisiert Ausfallsicherungen und reduziert die Auswirkungen eines NameNode-Ausfalls.
Dazu gibt es noch HBase, eine nicht-relationale Datenbank für Hadoop. Der verteilte Dienst Apache Flume ermöglicht das Datenstreaming großer Mengen von Logdaten.
Außerdem gibt es Apache Sqoop, ein Kommandozeilenwerkzeug, das die Datenmigration zwischen Hadoop und relationalen Datenbanken ermöglicht. Mit der Entwicklungsplattform Apache Pig werden Aufgaben entwickelt, die auf Hadoop ausgeführt werden sollen.
Das Planungssystem Apache Oozie erleichtert die Verwaltung von Hadoop-Jobs. HCatalog schließlich ist ein Tabellenverwaltungswerkzeug zum Sortieren von Daten aus verschiedenen Verarbeitungssystemen.
Die Vorteile ☝️
Zahlreich sind die Vorteile von Hadoop. Zunächst werden mit diesem Framework große Datenmengen schneller gespeichert und verarbeitet. Dies ist ein wertvoller Vorteil im Zeitalter der sozialen Netzwerke und des Internets der Dinge.
Dazu bietet Hadoop die Flexibilität, unstrukturierte Daten aller Art wie Texte, Symbole, Bilder oder Videos zu speichern. Im Gegensatz zu einer traditionellen relationalen Datenbank können Daten gespeichert werden, ohne dass sie vorher verarbeitet werden müssen. Die Funktionsweise ist daher mit einer NoSQL-Datenbank vergleichbar.
Darüber hinaus hat Hadoop auch eine erhebliche Rechenleistung. Sein verteiltes Rechenmodell bietet Leistung und Effizienz.
Mit diesem Open-Source-Framework kann man auch Big Data kostengünstig verarbeiten, da es kostenlos und frei genutzt werden kann. Darüber hinaus basiert es auf sehr gängiger Hardware, um die Daten zu speichern.
Ein weiterer großer Vorteil ist die Elastizität. Es genügt, die Anzahl der Knoten in einem Cluster zu ändern, um das System zu erweitern oder zu verkleinern.
Schließlich ist Hadoop von der Hardware unabhängig, um die Verfügbarkeit der Daten zu erhalten. Diese werden automatisch mehrfach auf verschiedene Knoten im Cluster kopiert. Wenn ein Gerät ausfällt, leitet das System die Aufgabe automatisch auf ein anderes um. Das Framework ist daher fehler- und ausfalltolerant.
Die Schwächen 🤫
Trotz all seiner Stärken hat Hadoop auch Schwächen. Zunächst ist der MapReduce-Algorithmus nicht für alles geeignet. Er eignet sich für die einfachsten Informationsabfragen, aber nicht für iterative Aufgaben. Auch für fortgeschrittene analytische Berechnungen ist er nicht effizient, da iterative Algorithmen eine intensive Interkommunikation erfordern.
Für Data Management, Metadaten und Data Governance bietet Hadoop keine geeigneten und verständlichen Werkzeuge. Auch Werkzeuge für die Standardisierung von Daten und die Bestimmung der Qualität fehlen.
Ein weiteres Problem ist, dass Hadoop schwer zu beherrschen ist. Daher gibt es nur wenige Programmierende, die kompetent genug sind, um MapReduce zu nutzen. Aus diesem Grund fügen viele Anbieter eine SQL-Datenbanktechnologie über Hadoop hinzu. Die Zahl der Programmierenden, die SQL beherrschen, ist deutlich höher.
Letzter Schwachpunkt: die Datensicherheit. Das Authentifizierungsprotokoll Kerberos hilft jedoch bei der Sicherung von Hadoop-Umgebungen.
Welche Anwendungsfälle gibt es für Hadoop?
Hadoop bietet viele Möglichkeiten. Einer seiner wichtigsten Anwendungsfälle ist die Verarbeitung von Big Data. Das Framework eignet sich tatsächlich für die Verarbeitung großer Datenmengen, die in der Größenordnung von mehreren Petabytes liegen.
Solche Informationsmengen erfordern eine sehr starke Rechenleistung: Dabei ist Hadoop die passende Lösung. Ein Unternehmen, das kleinere Datenmengen von einigen hunderten von Gigabyte verarbeiten muss, kann hingegen mit einer alternativen Lösung zurecht kommen.
Ein weiterer wichtiger Anwendungsfall für Hadoop ist die Speicherung verschiedener Daten. Die Flexibilität dieses Frameworks ermöglicht die Unterstützung vieler verschiedener Datentypen. Es ist möglich, Texte, Bilder oder sogar Videos zu speichern. Die Art der Datenverarbeitung kann je nach Bedarf ausgewählt werden. Auf diese Weise erhält man die Flexibilität eines Data Lake.
Darüber hinaus wird Hadoop für parallele Datenverarbeitung verwendet. Mithilfe des MapReduce-Algorithmus wird die parallele Verarbeitung der gespeicherten Daten organisiert. Dies bedeutet, dass mehrere Aufgaben gleichzeitig ausgeführt werden können.
Wie nutzen Unternehmen Hadoop?
Unternehmen aus allen Branchen nutzen Hadoop für die Verarbeitung von Big Data. Das Framework hilft zum Beispiel dabei, die Bedürfnisse und Erwartungen der Kundschaft zu verstehen.
Große Unternehmen aus den Branchen Finanzwesen und soziale Netzwerke nutzen diese Technologie, um die Erwartungen der Verbraucher und Verbraucherinnen zu verstehen, indem sie Big Data in Bezug auf ihre Aktivitäten und ihr Verhalten analysieren.
💡Auch interessant:
Ausgehend von diesen Daten ist es möglich, der Kundschaft personalisierte Angebote zu unterbreiten. Das ist das ganze Prinzip der gezielten Werbung in sozialen Netzwerken oder der Empfehlungsmaschinen (recommendation engine) auf E-Commerce-Plattformen.
Darüber hinaus lassen sich mit Hadoop auch Geschäftsprozesse optimieren. Ausgehend von Transaktions- und Kundendaten helfen Trendanalysen und prädiktive Analysen Unternehmen dabei, ihre Produkte und Bestände individuell anzupassen, um den Umsatz zu steigern.
Dadurch können bessere Entscheidungen getroffen und höhere Gewinne eingefahren werden. Durch die Analyse von Daten über das Verhalten und die Interaktionen von Mitarbeitenden kann auch das Arbeitsumfeld verbessert werden.
In der Gesundheitsbranche können medizinische Einrichtungen Hadoop nutzen, um die große Menge an Daten im Zusammenhang mit Gesundheitsproblemen und den Ergebnissen medizinischer Behandlungen zu überwachen. Forscher und Forscherinnen können diese Daten analysieren, um Gesundheitsprobleme zu identifizieren und geeignete Behandlungsmethoden auszuwählen.
Auch Trader und die Finanzwelt nutzen Hadoop. Mit seinem Algorithmus können Marktdaten gescannt werden, um Chancen und saisonale Trends zu erkennen. Finanzunternehmen können mithilfe des Frameworks Operationen automatisieren.
Darüber hinaus wird Hadoop für das Internet der Dinge verwendet. Diese Geräte benötigen Daten, um richtig zu funktionieren. Die Firmen verwenden daher Hadoop als Data Warehouse, um die Milliarden von Transaktionen zu speichern, die durch das IoT aufgezeichnet werden. So kann das Datenstreaming ordnungsgemäß verwaltet werden.
Dies sind nur einige Beispiele. Darüber hinaus wird Hadoop auch im Sport und in der wissenschaftlichen Forschung eingesetzt.
Welche Erweiterungen gibt es für Hadoop?
Hadoop ist ein Open-Source-Framework für die verteilte Verarbeitung großer Datenmengen. Ursprünglich entwickelt von Yahoo, hat es sich zu einem grundlegenden Werkzeug für Big-Data-Analysen und -Verarbeitung entwickelt. Um die Funktionalität von Hadoop zu erweitern und an spezifische Anforderungen anzupassen, wurden im Laufe der Jahre verschiedene Erweiterungen und Projekte entwickelt. Hier ist eine Übersicht über einige der wichtigsten Erweiterungen für Hadoop:
Tabelle der Hadoop-Erweiterungen:
| Erweiterung | Beschreibung |
|---|---|
| Hive | Hive ist eine Data-Warehouse-Infrastruktur, die eine SQL-ähnliche Abfragesprache namens HiveQL verwendet, um Abfragen auf Hadoop-Daten durchzuführen. Es ermöglicht die Verarbeitung von Daten in Tabellenformaten. |
| Pig | Pig ist eine Plattform zur Abfrage und Analyse von Daten in Hadoop. Es verwendet eine Skriptsprache namens Pig Latin, um Datenverarbeitungsaufgaben zu definieren und auszuführen. |
| HBase | HBase ist eine verteilte NoSQL-Datenbank, die auf Hadoop aufbaut und die Speicherung von Big-Data-Daten in Tabellen mit spaltenorientierter Struktur ermöglicht. |
| Mahout | Mahout ist eine Apache-Softwarebibliothek für maschinelles Lernen und Data Mining. Es bietet Algorithmen und Werkzeuge für die Entwicklung von Klassifikatoren, Clustern und Empfehlungssystemen auf Hadoop. |
| Oozie | Oozie ist ein Workflow-Planungssystem für Hadoop-Jobs. Es ermöglicht die Definition, Planung und Ausführung von komplexen, sequenziellen Datenverarbeitungsworkflows. |
| Sqoop | Sqoop (SQL to Hadoop) ist ein Tool zum Importieren von Daten aus relationalen Datenbanken in Hadoop und umgekehrt. Es erleichtert den Datenimport und -export zwischen Hadoop und SQL-Datenbanken. |
| Flume | Apache Flume ist ein verteiltes System zur Sammlung und Übertragung von Protokolldaten von verschiedenen Quellen in Hadoop. Es ist nützlich für das Sammeln von Streaming-Daten in Echtzeit. |
| Spark | Spark ist ein schnelles und in-memory-fähiges Big-Data-Framework, das auf Hadoop aufbaut. Es bietet eine Vielzahl von APIs und Bibliotheken für Datenverarbeitung, maschinelles Lernen und Echtzeitanalysen. |
| Tez | Apache Tez ist ein Framework zur Verbesserung der Leistung von Hadoop MapReduce-Jobs. Es ermöglicht die effizientere Ausführung von Aufgaben und die Optimierung von Abfrageverarbeitungen. |
| Kafka | Kafka ist ein verteiltes Streaming-Plattform- und Event-Streaming-System, das in Hadoop-Ökosystemen zur Echtzeitdatenverarbeitung und -analyse verwendet wird. Es kann Datenströme in Echtzeit verarbeiten und speichern. |
Was ist ein Hadoop Cluster?
Ein Hadoop-Cluster ist eine verteilte Computing-Umgebung, die auf dem Open-Source-Framework Hadoop basiert und entwickelt wurde, um große Mengen an Daten zu speichern, zu verarbeiten und zu analysieren. Ein solcher Cluster besteht aus mehreren miteinander verbundenen Rechnerknoten oder Servern, die gemeinsam arbeiten, um Big Data-Aufgaben effizient zu bewältigen. Hier sind die wichtigsten Merkmale und Komponenten eines Hadoop-Clusters:
Merkmale eines Hadoop-Clusters:
Verteilte Speicherung: Ein Hadoop-Cluster verwendet ein verteiltes Dateisystem namens Hadoop Distributed File System (HDFS), um große Datenmengen über verschiedene Knoten zu speichern. Dies ermöglicht die Skalierung der Speicherkapazität je nach Bedarf.
Verteilte Verarbeitung: Die Verarbeitung von Daten erfolgt auf verteilten Rechnerknoten im Cluster. Das Herzstück der Datenverarbeitung ist der MapReduce-Algorithmus, der die Arbeit auf die Knoten aufteilt und Ergebnisse zusammenführt.
Skalierbarkeit: Hadoop-Cluster sind äußerst skalierbar und können leicht erweitert werden, indem neue Knoten hinzugefügt werden. Dies ermöglicht es, mit wachsenden Datenmengen umzugehen, indem mehr Rechenleistung und Speicherressourcen zur Verfügung gestellt werden.
Fehlertoleranz: Hadoop ist auf Fehlertoleranz ausgelegt. Bei Hardwarefehlern oder Abstürzen auf einem Knoten kann Hadoop die Verarbeitung auf anderen Knoten fortsetzen, ohne dass Datenverlust oder Ausfallzeiten auftreten.
Parallele Verarbeitung: Hadoop ermöglicht die parallele Verarbeitung von Daten, indem es Aufgaben auf verschiedene Knoten verteilt. Dies führt zu schnelleren Verarbeitungszeiten, insbesondere für Batch-Verarbeitungsaufgaben.
Komponenten eines Hadoop-Clusters:
HDFS (Hadoop Distributed File System): Dies ist das verteilte Dateisystem, das zur Speicherung von Daten in einem Hadoop-Cluster verwendet wird. Es teilt Daten in Blöcke auf und repliziert sie über verschiedene Knoten, um Redundanz und Fehlertoleranz sicherzustellen.
YARN (Yet Another Resource Negotiator): YARN ist das Ressourcenverwaltungssystem von Hadoop, das die Zuweisung von Rechen- und Speicherressourcen für Anwendungen im Cluster koordiniert. Es ermöglicht die gleichzeitige Ausführung verschiedener Workloads.
MapReduce: MapReduce ist das Verarbeitungsmodell, das in Hadoop verwendet wird, um große Datenmengen in parallele Aufgaben aufzuteilen und sie auf den Knoten im Cluster auszuführen. Es besteht aus den zwei Phasen „Map“ (Aufteilen) und „Reduce“ (Zusammenführen).
Hadoop-Komponenten: Zusätzlich zu den grundlegenden Hadoop-Komponenten gibt es Erweiterungen und Tools wie Hive, Pig, Spark und HBase, die spezifische Datenverarbeitungs- und Analyseaufgaben in einem Hadoop-Cluster ermöglichen.
Insgesamt ermöglicht ein Hadoop-Cluster die kostengünstige und effiziente Verarbeitung großer Datenmengen, was für Unternehmen und Organisationen in einer datengetriebenen Welt von entscheidender Bedeutung ist. Es hat in verschiedenen Branchen Anwendung gefunden, von der Finanzdienstleistungsbranche über die Gesundheitsversorgung bis hin zur wissenschaftlichen Forschung.
Was ist der Unterschied zwischen Hadoop und einer relationalen Datenbank? 📍
| Merkmal | Hadoop | Relationale Datenbank |
|---|---|---|
| Datenmodell | Hadoop verwendet ein verteiltes Dateisystem (HDFS) und speichert Daten in Form von unstrukturierten oder semi-strukturierten Dateien. | Relationale Datenbanken verwenden ein tabellenbasiertes Datenmodell, bei dem Daten in Tabellen mit vordefinierten Schemata organisiert sind. |
| Skalierbarkeit | Hadoop ist äußerst skalierbar und kann leicht erweitert werden, um mit wachsenden Datenmengen umzugehen. | Relationale Datenbanken haben in der Regel eine begrenzte Skalierbarkeit und erfordern vertikales Wachstum durch Hardware-Upgrades. |
| Verarbeitung von Big Data | Hadoop ist auf die Verarbeitung von Big Data ausgelegt und ermöglicht die parallele Verarbeitung großer Datenmengen auf verteilten Knoten. | Relationale Datenbanken sind besser für die Verarbeitung kleinerer bis mittelgroßer Datenmengen geeignet. |
| Datenstruktur | Hadoop speichert Daten in unstrukturierten oder semi-strukturierten Formaten wie Text, JSON oder Avro. | Relationale Datenbanken erfordern eine klare Datenstruktur mit festen Spalten und Datentypen. |
| Verarbeitungsmodell | Hadoop verwendet das MapReduce-Verarbeitungsmodell, um Aufgaben in Map- und Reduce-Schritte aufzuteilen und parallel zu verarbeiten. | Relationale Datenbanken verwenden SQL (Structured Query Language) für Abfragen und Transaktionen. |
| Lesegeschwindigkeit | Hadoop kann bei großen Lesevorgängen langsam sein, da es auf die Verarbeitung verteilter Dateien ausgerichtet ist. | Relationale Datenbanken bieten in der Regel schnelle Lesevorgänge für transaktionsorientierte Abfragen. |
| Schreibgeschwindigkeit | Hadoop bietet eine gute Schreibgeschwindigkeit, insbesondere bei der Durchführung von Batch-Verarbeitungsaufgaben. | Relationale Datenbanken bieten effiziente Schreibvorgänge für Transaktionen, jedoch möglicherweise weniger für Masseninsertionen. |
| Datenkonsistenz | Hadoop bietet hohe Skalierbarkeit, aber unter Umständen nicht dieselbe Datenkonsistenz wie relationale Datenbanken. | Relationale Datenbanken gewährleisten ACID-Eigenschaften (Atomicity, Consistency, Isolation, Durability) und eine hohe Datenkonsistenz. |
| Anwendungsfälle | Hadoop eignet sich für Big Data-Analysen, maschinelles Lernen und die Verarbeitung von unstrukturierten Daten. | Relationale Datenbanken sind für transaktionsbasierte Anwendungen, Unternehmensanwendungen und Berichtswesen geeignet. |
Wie unterscheiden sich Spark und Hadoop Map Reduce❓
| Merkmal | Hadoop MapReduce | Apache Spark |
|---|---|---|
| Verarbeitungsmodell | Hadoop MapReduce basiert auf einem Batch-Verarbeitungsmodell und eignet sich am besten für Stapelverarbeitungsaufgaben. | Apache Spark unterstützt sowohl Batch- als auch Echtzeitverarbeitung und bietet eine flexible Verarbeitungsumgebung. |
| In-Memory-Verarbeitung | Hadoop MapReduce speichert Zwischenergebnisse auf der Festplatte, was zu langsameren Verarbeitungsgeschwindigkeiten führen kann. | Apache Spark nutzt In-Memory-Verarbeitung, um Zwischenergebnisse im RAM zu speichern, was erheblich schnellere Verarbeitung ermöglicht. |
| Datenverarbeitungsgeschwindigkeit | Hadoop MapReduce kann bei großen Datenmengen langsamer sein, da es auf Festplattenzugriff angewiesen ist. | Apache Spark ist in der Regel schneller, insbesondere bei iterativen Algorithmen und Echtzeitverarbeitung. |
| API und Programmiersprachen | Hadoop MapReduce verwendet Java als Hauptsprache für die Programmierung von Aufgaben. | Apache Spark bietet APIs in mehreren Programmiersprachen, darunter Scala, Java, Python und R. |
| Abstraktionsebenen | Hadoop MapReduce ist auf niedriger Ebene und erfordert Entwickler, sich um viele Details wie Partitionierung und Speicherung zu kümmern. | Apache Spark bietet höhere Abstraktionsebenen wie DataFrames und Datasets, die die Entwicklung erleichtern. |
| Zwischenergebnisse | Hadoop MapReduce schreibt Zwischenergebnisse auf die Festplatte, was den Speicherbedarf erhöhen kann. | Apache Spark hält Zwischenergebnisse im Speicher, was den Speicherbedarf reduziert. |
| Integration | Hadoop MapReduce kann in Hadoop-Ökosysteme wie HDFS, HBase und Hive integriert werden. | Apache Spark kann auch in Hadoop-Ökosysteme integriert werden und bietet auch Integrationen mit anderen Datenquellen und Datenbanken. |
| Ökosystem und Bibliotheken | Hadoop MapReduce hat ein etabliertes Ökosystem und eine große Anzahl von Bibliotheken für verschiedene Anwendungen. | Apache Spark verfügt über ein wachsendes Ökosystem und bietet Bibliotheken für maschinelles Lernen, Graphenverarbeitung und mehr. |
| Streaming und Iteration | Hadoop MapReduce ist nicht gut für Streaming-Anwendungen oder iterative Algorithmen geeignet. | Apache Spark ist für Streaming-Anwendungen und iterative Algorithmen optimiert. |

Wie lerne ich, Hadoop zu benutzen? Die Weiterbildungen bei Data-Scientest
Zusammenfassend kann man sagen, dass Hadoop bei richtiger Implementierung und Nutzung sehr nützlich für die Verarbeitung von Big Data ist. Dieses vielseitige Werkzeug ist ideal für Unternehmen, die mit großen Datenmengen arbeiten.
Deshalb kann es sehr hilfreich sein, zu lernen, wie man Hadoop benutzt. Deine Fähigkeiten werden bei vielen Organisationen in allen Branchen sehr gefragt, sodass Du leicht einen gut bezahlten Job finden kannst.
Wenn Du Unternehmer oder Unternehmerin bist, kannst Du auch unsere Hadoop-Weiterbildung Deinen Mitarbeitenden finanzieren. So können sie mit Big Data umgehen und alle angebotenen Möglichkeiten nutzen.
In der Weiterbildung zum/r Data Engineer von DataScientest lernst Du, Hadoop und alle Werkzeuge und Techniken des Data Engineering zu beherrschen. Der Lehrplan ist in fünf Module unterteilt: Programmierung, Datenbank, Big Data Volume, Big Data Vitesse und Automatisierung und Einsatz.
Im Laufe des Kurses werden die Lernenden Hadoop, aber auch Hive, Hbase, Pig, Spark, Bash, Cassandra, SQL oder Kafka kennenlernen. Am Ende des Kurses wird ein von der Pariser Universität La Sorbonne zertifiziertes Diplom als Data Engineer verliehen.
Mit dieser Weiterbildung kann man sich als Dateningenieur oder als Dateningenieurin ausbilden lassen. 93 % unserer Alumni haben unmittelbar nach ihrem Abschluss einen Arbeitsplatz. Die erworbenen Fähigkeiten können direkt in Unternehmen eingesetzt werden.
Innerhalb 9 Monaten kannst Du unsere berufsbegleitende Ausbildung absolvieren oder innerhalb 11 Wochen unseren Vollzeit-Intensivkurs. Alle unsere Kurse verfolgen einen innovativen hybriden Blended-Learning-Ansatz, der Präsenz- und Fernunterricht verbindet.
Der Kurs kostet 5.000 €, wobei Du die Möglichkeit einer Ratenzahlung hast. Deine Weiterbildung kann aber auch durch den Bildungsgutschein gefördert werden.
Du weißt alles über Hadoop. Du kannst gerne einen Artikel über Data Warehouse fortsetzen oder andere Themen entdecken💡:







