
In der Welt der Computer müssen wir oft Aufgaben erledigen, die mit Textverarbeitung zu tun haben. Es gibt ein universelles Werkzeug namens Regex, das oft die leistungsfähigsten Lösungen in diesem Bereich anbietet. Reguläre Ausdrücke sind jedoch weitgehend unbekannt, da sie manchmal etwas verwirrend aussehen.
Was ist Regex?
Ein regulärer Ausdruck, auch umgangssprachlich Regex genannt, ist auf den ersten Blick eine einfache Zeichenkette. Was unterscheidet ihn davon? Eine spezielle Syntax, die, wenn sie interpretiert wird, eine größere Menge von Zeichenketten beschreibt.
Diese beschreibende Zeichenkette wird als Muster oder Pattern bezeichnet.
Es handelt sich nicht um eine Programmiersprache im eigentlichen Sinne: Fast alle Sprachen verfügen über eine Regex-Bibliothek, die die Verwendung von regulären Ausdrücken ermöglicht. Außerdem unterscheidet sich die Syntax der einzelnen Sprachen nur geringfügig, was die Kompatibilität zwischen den verschiedenen Plattformen erheblich erleichtert, daher der eingangs verwendete Begriff „universell“.
Wozu dient ein Regex / regulärer Ausdruck?
Du hast es vielleicht schon erraten: Mithilfe von Regexen können wir eine bestimmte Art von Text isolieren und mit den entnommenen Proben eine spezielle Verarbeitung durchführen.
Der einfachste Fall ist, ein Wort in einem Dokument durch ein anderes zu ersetzen. Wir können unsere Toleranz auch verringern, indem wir bestimmte Abweichungen zulassen. Nachfolgend ein Beispiel:
Dieser Code findet Vorkommen des Ausdrucks „regex“ und seiner Varianten im Absatz und ersetzt sie durch „reguläre(n) Ausdruck(e)“.
Andere Verwendungen von Regexen gibt es in der Cybersicherheit: Wenn du ein Konto auf einer neuen Website erstellst, verlangt diese normalerweise ein Passwort, das eine Reihe von Regeln erfüllt. Um zu überprüfen, ob das Passwort, das du eingibst, nicht mit dem Vertrag in Konflikt steht, wird ein Regex angewendet. Ebenso muss bei der Eingabe einer gültigen E-Mail-Adresse sichergestellt werden, dass das arobase vorhanden ist (um nur eine Einschränkung zu nennen); dies ist relativ einfach in Form von Regexen zu übertragen.

Schließlich findet man Regexe auch in der maschinellen Verarbeitung natürlicher Sprache (NLP), beim Webscraping, bei der Mustererkennung usw. Diese Liste ist keineswegs vollständig, und du wirst sehr wahrscheinlich ein Data Science-Problem lösen müssen, bei dem Regexe eine Rolle spielen!
Ein sehr kontroverses Aussehen
Der obige Code ist vielleicht etwas gewöhnungsbedürftig: Ohne Kenntnisse der Regex-Architektur ist es schwierig, ihn zu verstehen… Es ist dieser unverdauliche Aspekt, der diesem Werkzeug schadet, obwohl es alles andere als kompliziert zu beherrschen ist! Es gibt nur eine Handvoll Gesetze, die diese Syntax regeln, und wir werden versuchen, sie zu erläutern.
Betrachten wir den folgenden Ausdruck:
[regex to determine a valid nickname (make a coloured and multiple part image)]

Um festzustellen, wie eine Regex funktioniert, muss sie zunächst in mehrere Untergruppen zerlegt werden. Das trifft sich gut, denn das Konzept der Gruppen existiert formal:
- Sie werden durch Klammern abgegrenzt.
- Einige Klammern sind nicht fesselnd (wie die, die mit einem Lookahead verbunden sind), aber in der Regel wird jede Gruppe in der Reihenfolge gezählt, in der die Klammer geöffnet wurde. Eine Gruppe kann durch die Eingabe des Zeichens „?:“ am Anfang der Klammer gefangen werden oder nicht.
- Um es deutlicher zu sagen: Eine auffangende Gruppe ist eine Teilmenge des gesamten Musters, die bei der Suche nach einem Muster isoliert werden kann.
- Das Zirkumflexzeichen „^“ am Anfang einer Liste ist ein Sonderzeichen; es bedeutet, dass der reguläre Ausdruck nur die Vorkommen am Anfang der Zeile erfasst.
- Umgekehrt sorgt das Dollarzeichen $ dafür, dass das Ende des Vorkommens dem Ende einer Zeile entspricht.
- [A-ZÉ]: Wenn eckige Klammern vorhanden sind, bedeutet dies, dass ein (und nur ein, wenn es wie hier keine weitere Angabe gibt) Zeichen aus der gelieferten Menge akzeptiert wird. A-Z entspricht „jedem Buchstaben zwischen großem A und großem Z“ (Groß-/Kleinschreibung beachten!), zu dem der Buchstabe É hinzugefügt wird. Dieser erste Teil der Regex nimmt also einen Großbuchstaben auf.
- (pattern)+: Das +-Zeichen fängt pattern zwischen 1 und unendlich vielen Malen ein.
- ((pattern1)|(pattern2)): Das Symbol | bedeutet „wir fangen entweder pattern1 oder pattern2“.
- ([a-zéèà\- ])(?!\3{2}) ) : Die erste Klammer funktioniert genauso wie die erste Gruppe. Es werden nur die Zeichen erfasst, die sich in der Klammer befinden; von a bis z Kleinbuchstaben, dann Akzente, ein Leerzeichen und das Sonderzeichen -. Um ein Sonderzeichen aufzurufen, muss man einen Backslash \ hinzufügen.
- Die zweite Klammer ist ein negativer Lookahead. Ein Lookahead beobachtet, wie der Name schon sagt, den weiteren Verlauf der Zeichenkette und fügt eine Bedingung hinzu, damit der Ausdruck angewendet werden kann. Hier wird dies durch die Bedingung „Der Ausdruck ([a-zeèà- ]) erfasst nur dann Text, wenn ihm nicht der Ausdruck \3{2} folgt“ umgesetzt.
- \3{2} : Wenn eine Zahl entfällt (d. h. wenn einer Zahl ein \-Zeichen vorangestellt ist), bezieht sich die Zahl auf die zugehörige Gruppe. \3 bezieht sich also auf die dritte Gruppe im Regex!
- Wenn eine Zahl hingegen in geschweiften Klammern steht, gibt sie die genaue Anzahl der Vorkommen der vorherigen Gruppe an.
- In anderen Worten, dieses Muster bedeutet „fange ein Zeichen aus der Gruppe [a-zeèà\- ] ein, vorausgesetzt, es kommt nicht öfter als zweimal vor“.
- (?<s)([A-ZE])(?!![A-ZE]): Ähnlich wie bei einem Lookahead ist die erste Gruppe von Klammern ein positiver Lookbehind. \captures any white space (a space, a tab). Wenn man der gleichen Logik folgt, kann man erahnen, dass dieser Ausdruck in den Satz „fängt einen Großbuchstaben (A, B, …, Z oder É) nur dann ein, wenn ihm ein Leerzeichen vorausgeht und KEIN anderer Großbuchstabe folgt“ übersetzt werden kann.
- Schließlich bedeutet (.+), dass jedes beliebige Zeichen unbegrenzt akzeptiert wird.
Mit all diesen Regeln an Ort und Stelle wird die gesamte Regex plötzlich sehr intuitiv!
regex101: eine Plattform, um deine Regexe zu überprüfen
Um das Verhalten eines frisch erstellten Ausdrucks zu überprüfen, gibt es eine sehr praktische Seite: https://regex101.com/.
Auf dieser Seite kannst du deine Regex und die zugehörige Programmiersprache eingeben und dann eine beliebige Zeichenkette in das dafür vorgesehene Feld eintragen. Wenn das Pattern einen Text erfasst, wird dieser hervorgehoben und von der Website erfasst.
Wenn du dich über den vorherigen Teil gewundert hast, sieh dir den Text an, den das Pattern erfasst (oder auch nicht):
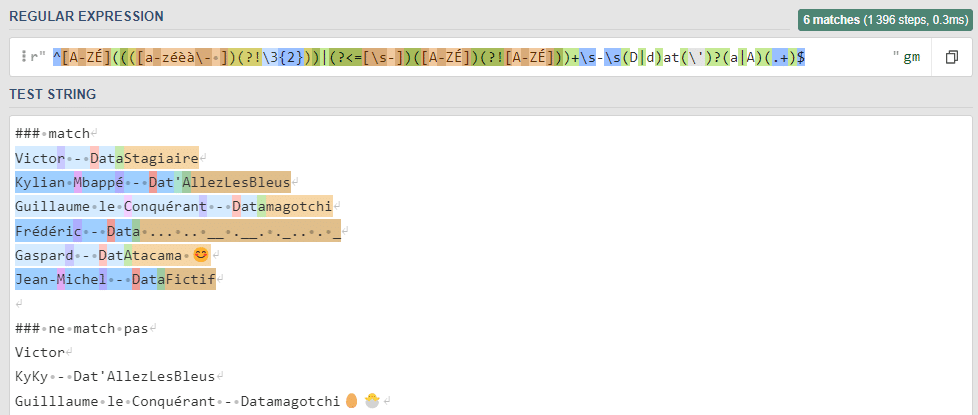
Dieses Pattern nimmt nur gültige Pseudonyme nach einer festgelegten Syntax.
Zusammenfassend
Regexe sind einfach zu benutzen und sehr vielseitig, und es ist ein großer Vorteil, dieses Werkzeug zu beherrschen. Es ist zwar möglich, ein Problem auch ohne Regex zu lösen, aber die Regex-Lösung ist oft die effektivste von allen.







