
Heute präsentieren wir dir den vierten Teil unseres spannenden Berichts über NLP.
In diesem Artikel werden wir uns ansehen, wie man einen Übersetzungsalgorithmus auf Python - auf Englisch "machine translation" - erstellt, mit dem man jedes Wort aus einer Ausgangssprache in eine Zielsprache aus den words embeddings übersetzen kann.
Diese Art von Algorithmus zu implementieren, mag auf den ersten Blick etwas unklar erscheinen. Mathematisch gesehen ist es so, als würde man die Übereinstimmungsmatrix (oder Ausrichtungsmatrix) W finden, indem man das folgende Optimierungsproblem löst:
Sei:
Od(R) ist die Menge der orthogonalen Matrizen (d. h. die Menge der Matrizen M mit reellen Koeffizienten, die invertierbar sind und so, dass 𝑀-1=𝑀T ).
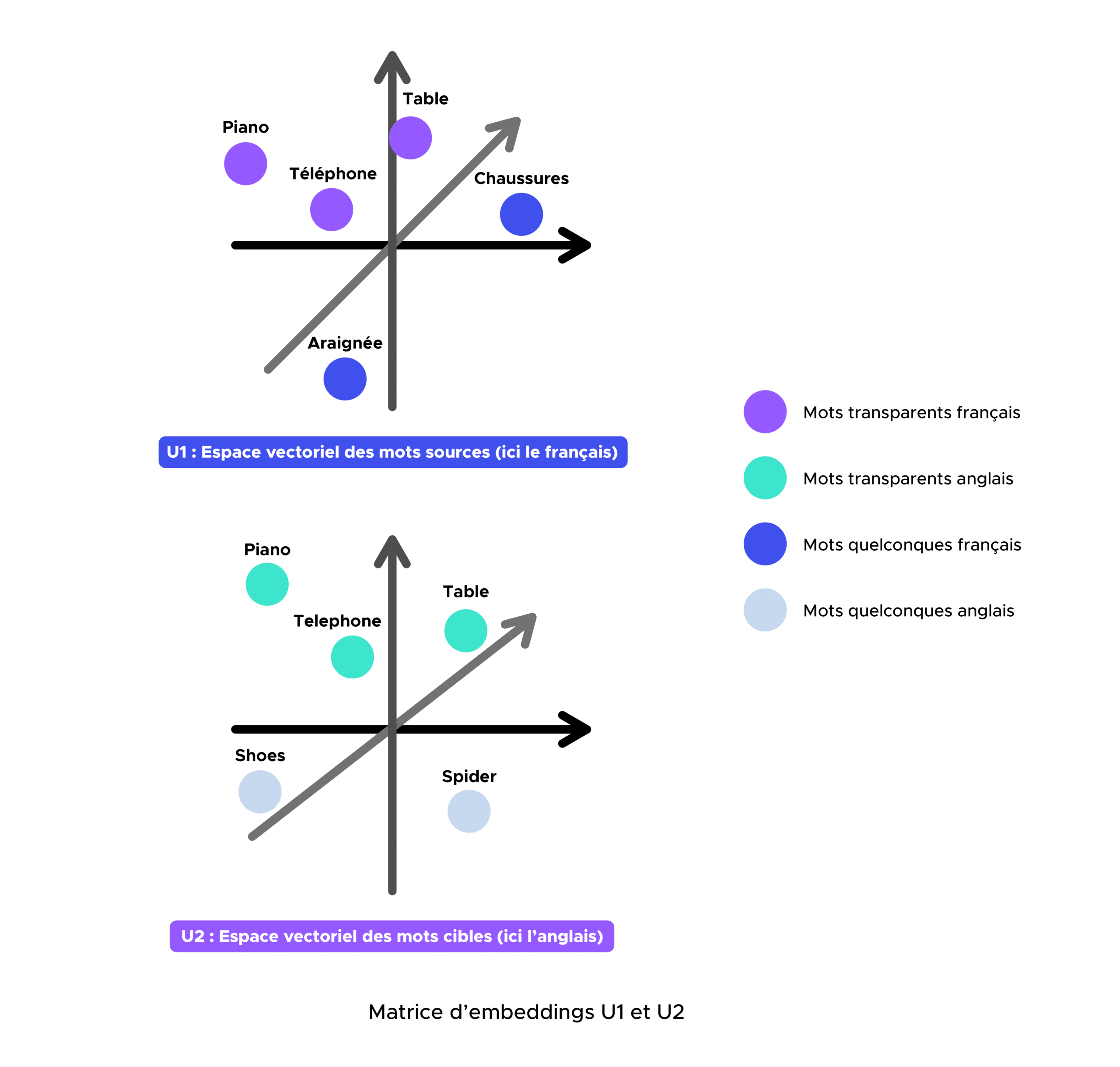
X und Y sind jeweils die Matrizen, die die Einbettungen der transparenten Wörter (z. B. table, television, radio, piano, telephone usw.) enthalten, die in der Ausgangssprache (Französisch) und in der Zielsprache (Englisch) vorkommen. X und Y sind also die Matrizen mit den Einbettungen der französischen und englischen Wörter.
Transparente Wörter sind für die Konstruktion des Übersetzungsalgorithmus entscheidend, da sie Bezugspunkte sind, die es ermöglichen, die beiden Vektorräume der Einbettungen nach Anwendung der Ausrichtungsmatrix W auszurichten. Mit anderen Worten: Die transparenten Wörter werden die geometrische Transformation zwischen den beiden Untervektorräumen bestimmen.
Auch interessant:
| Gradient Boosting Algorithmen |
| Dijkstra Algorithmus |
| t-sne-Algorithmus |
| CAH Algorithmus ML Clustering |
| 3 ML Algorithmen die du kennen solltest |
Übrigens, was ist eine Embedding-Matrix eigentlich?
Um zu erklären, was eine Embedding-Matrix ist, nehmen wir die folgenden drei Sätze:
- Als der Arbeiter weg war.
- Als der Fischer weg war.
- Wenn der Hund weg ist.
Angenommen, wir kennen die Bedeutung der Wörter „Arbeiter“, „Fischer“ und „Hund“ nicht, aber wir können sagen, dass diese drei Sätze bis auf ein Wort identisch sind.
Da die Kontexte ähnlich sind, könnten wir folgern, dass es eine gewisse Ähnlichkeit zwischen ‚Arbeiter‘, ‚Fischer‘ und ‚Hund‘ gibt.
Wenn wir diese Idee auf einen ganzen Korpus anwenden, könnten wir auf diese Weise die Beziehungen zwischen mehreren Wörtern definieren.
Eine Frage bleibt jedoch: Wie lassen sich diese Beziehungen am besten darstellen? Das Konzept der Einbettungsmatrix wurde entwickelt.
Der Einfachheit halber stellen wir uns vor, dass jedes Wort und seine Bedeutung in einem abstrakten dreidimensionalen Raum dargestellt werden können.
Konzeptuell bedeutet dies, dass alle Wörter als singuläre Punkte in einem dreidimensionalen Raum existieren und jedes Wort eindeutig durch seine Position in diesem Raum definiert werden kann, der durch drei Zahlen (x, y, z) beschrieben wird.
In Wirklichkeit ist die Bedeutung eines Wortes jedoch zu kompliziert, um einfach in einem dreidimensionalen Raum beschrieben zu werden, und in der Regel braucht man fast 300 Dimensionen, um ein Wort und seine Bedeutung vollständig zu definieren.
Der Vektor aus 300 Zahlen, der ein bestimmtes Wort identifiziert, wird als das Embedding dieses Wortes bezeichnet.
Letztendlich ist eine Embedding-Matrix nichts anderes als eine Matrix, die eine Vielzahl von Wörtern und ihre entsprechenden Embeddings enthält. Hier ist ein Beispiel für eine englische Embedding-Matrix:
Implementierung eines Übersetzungsalgorithmus und seine Grenzen
In diesem Abschnitt werden wir einen Übersetzungsalgorithmus implementieren und versuchen, sowohl seine Stärken als auch seine Schwächen zu bestimmen.
Schritt 0:
Abruf von zwei vorab trainierten französischen und englischen U1- und U2-Embedding-Matrizen auf Common Crawl und Wikipedia mithilfe von fastText.
Schritt 1:
Zunächst müssen wir ein zweisprachiges Wörterbuch (z. B. Französisch-Englisch) definieren, das alle transparenten Wörter enthält, die in den beiden Vokabularen enthalten sind. Sobald wir dieses erhalten haben, müssen wir die X- und Y-Embedding-Matrizen erstellen, die jeweils den französischen und englischen Matrizen entsprechen, die die Embeddings enthalten, die mit den Wörtern des zuvor definierten zweisprachigen Wörterbuchs verbunden sind.
Schritt 2:
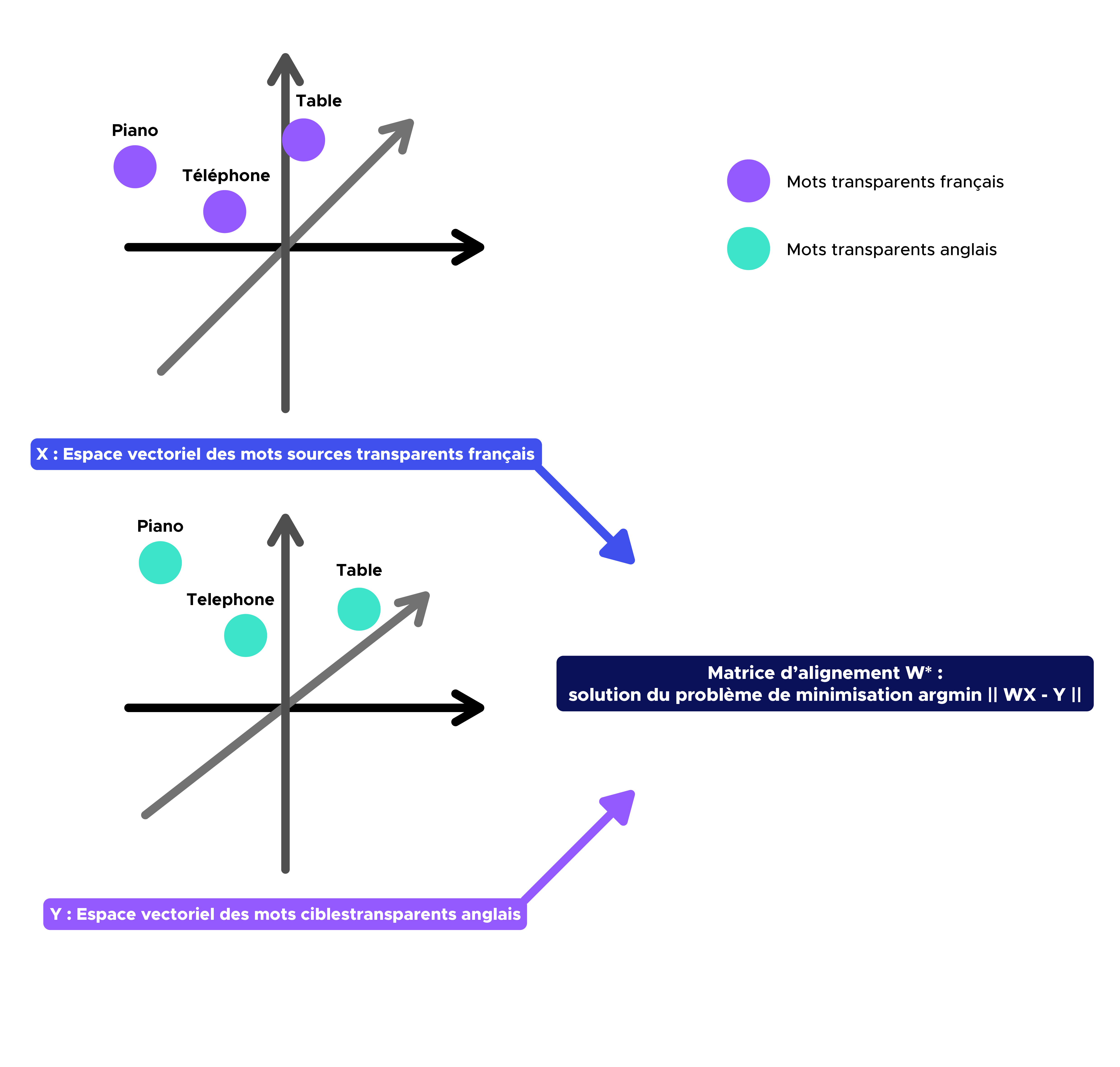
Das Ziel dieses zweiten Schritts ist es, die Anwendung W (Matching-Matrix) zu finden, die den Quellwortvektorraum (z. B. Französisch) auf den Zielwortvektorraum (z. B. Englisch) projiziert.
Es ist offensichtlich, dass diese Methode umso besser funktioniert, je ähnlicher die Struktur der Einbettungsräume ist (was hier bei Englisch und Französisch der Fall ist).
Wie wir in der Einleitung gesehen haben, ist W* = argmin || WX – Y || unter der Bedingung, dass W eine orthogonale Matrix ist.
Wir können unter Verwendung der Orthogonalität und der Eigenschaften der Spur einer Matrix beweisen, dass
W*=UVT mit UΣVT = SVD (YXT).
Dabei ist SVD die Singulärwertzerlegung einer Matrix (Verallgemeinerung des Spektraltheorems, das besagt, dass alle orthogonalen Matrizen durch eine orthonormale Basis von Eigenvektoren diagonalisiert werden können).
Aufgrund des vorherigen Ergebnisses ist das Finden von W einfach die Singulärwertzerlegung der Matrix 𝑌𝑋T.
Hier ist die Matrix W, die du als Ausgabe des Codes erhältst:
Schritt 3:
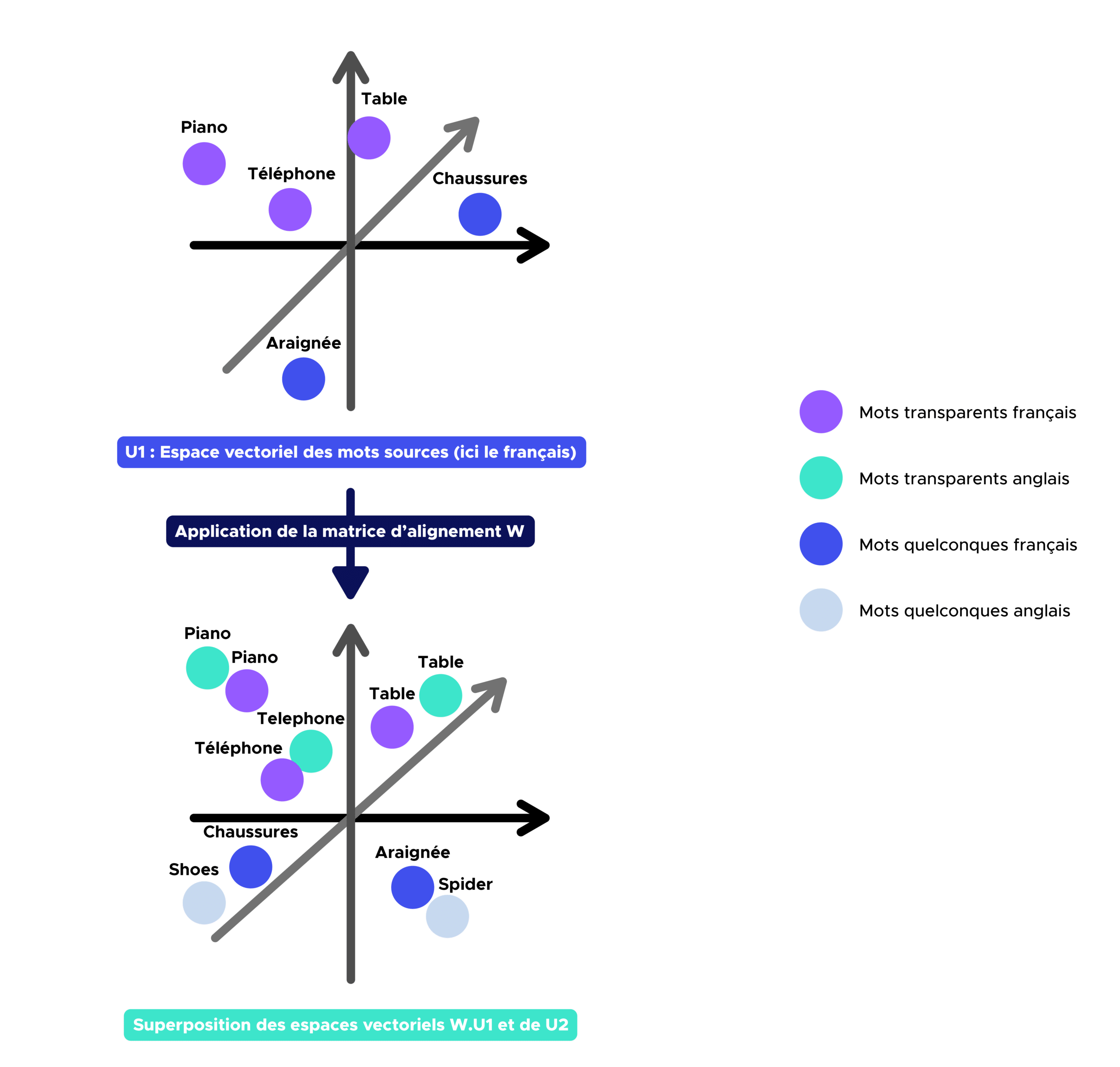
Sobald wir die Alignment-Matrix W erhalten haben, können wir nun die englische Übersetzung eines beliebigen Wortes finden, das im deutschen Wortschatz vorkommt, indem wir die nächsten Nachbarn der Quellwörter im Zielwortvektorraum identifizieren.
Hier sind die Ergebnisse (jeweils 3 englische Begriffe, die der Übersetzung am nächsten kommen, und die Wahrscheinlichkeit, dass sie mit dem zu übersetzenden Wort übereinstimmen):

Wie wir sehen können, ist dieser Algorithmus ziemlich leistungsstark und kann als Übersetzer von Französisch-Englisch-Wörtern dienen.
Wir könnten versuchen, diese Art von Algorithmus zu verwenden, um einen ganzen Text zu übersetzen:
Hier ist das Ergebnis
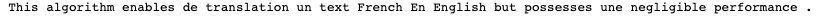
Angesichts der unterschiedlichen Sprachstrukturen im Französischen und Englischen (z. B. die Reihenfolge Substantiv-Adjektiv im Französischen, Adjektiv-Name im Englischen) ist eine Wort-für-Wort-Übersetzung nicht optimal. Außerdem können wir feststellen, dass unser Übersetzungsalgorithmus bei Wörtern wie: de, en, un, une, etc. nicht funktioniert.
Wie wir bereits vermutet haben, ist die Wort-für-Wort-Übersetzung nicht die beste Methode, um einen Text zu übersetzen. Eine mögliche Lösung wäre die Verwendung eines Seq2seq- (oder BERT-) Ansatzes, dem wir in Kürze einen eigenen Artikel widmen werden.
Hat dir dieser Artikel gefallen?
Möchtest du mehr über Deep Learning erfahren?







