
Apache Pig ist die Programmiersprache, mit der du Hadoop und MapReduce nutzen kannst. Hier erfährst du alles, was du wissen musst: Einführung, Anwendungsfälle, Vorteile, Schulungen...
Das MapReduce-Programmiermodell des Apache Hadoop-Frameworks ermöglicht es, große Mengen an Big Data zu verarbeiten. Allerdings beherrschen Data Analysts dieses Paradigma nicht immer. Aus diesem Grund wurde suivi
Was ist Apache Pig?
Die Apache Pig High Level Programming Language ist sehr nützlich, um große Datensätze zu analysieren. Sie wurde ursprünglich 2006 intern von Yahoo! entwickelt, mit dem Ziel, MapReduce-Jobs auf allen Datasets zu erstellen und auszuführen.
Der Name „Pig“ wurde gewählt, weil diese Programmiersprache so konzipiert ist, dass sie auf jeder Art von Daten funktioniert, wie ein Schwein, das alles und jedes verschlingt.
Im Jahr 2007 wurde Pig über den Apache-Inkubator zu Open Source gemacht. Im Jahr 2008 wurde die erste Version von Apache Pig veröffentlicht. Der Erfolg ist groß und Pig wird 2010 zu einem Apache-Projekt der ersten Stufe.
Durch den Einsatz von Apache Pig können Datenanalysten weniger Zeit mit dem Schreiben von MapReduce-Programmen verbringen. So können sie sich weiterhin auf die Analyse von Datensätzen konzentrieren.
Apache Pig ist also eine Abstraktion für MapReduce. Dieses Werkzeug wird verwendet, um große Datasets zu analysieren, indem es sie als Datenströme darstellt. Alle Datenmanipulationsoperationen auf Hadoop können mit Apache Pig durchgeführt werden.
Die Apache Pig-Architektur
Die Apache Pig-Architektur basiert auf zwei Hauptkomponenten: der Sprache Pig Latin und der Laufzeitumgebung, die die Ausführung von PigLatin-Programmen ermöglicht.
Die Sprache Pig Latin ermöglicht das Schreiben von Programmen zur Datenanalyse. Sie liefert verschiedene Operatoren, die Programmierer verwenden können, um ihre eigenen Funktionen zum Lesen, Schreiben oder Verarbeiten von Daten zu entwickeln.
Ein Pig Latin-Programm besteht aus einer Reihe von Transformationen oder Operationen, die auf die „Input“-Daten (Eingabe) angewendet werden, um eine „Output“-Daten zu erzeugen. Diese Operationen beschreiben einen Datenstrom, der von der Hadoop-Pig-Laufzeitumgebung in eine ausführbare Darstellung übersetzt wird.
Um Daten mithilfe von Apache Pig zu analysieren, müssen Programmierer unbedingt Skripte mit der Sprache Pig Latin schreiben. Alle diese Skripte werden intern in Map- und Reduce-Aufgaben umgewandelt. Die Pig-Engine-Komponente übernimmt die Aufgabe, die Skripte in MapReduce-Jobs umzuwandeln.
Der Programmierer hat jedoch nicht einmal Kenntnis von diesen Jobs. Auf diese Weise ermöglicht Pig den Programmierern, sich auf die Daten zu konzentrieren, anstatt auf die Art der Ausführung.
Bei Pig wird zwischen zwei Ausführungsmodi unterschieden. Der lokale Modus wird auf einer einzelnen JVM ausgeführt und verwendet das lokale Dateisystem. Dieser Modus eignet sich für die Analyse kleiner Datensätze.
Im Map Reduce-Modus werden die in Pig Latin geschriebenen Anfragen in MapReduce-Jobs übersetzt und auf einem Hadoop-Cluster ausgeführt. Dieser kann teilweise oder vollständig verteilt sein. Der MapReduce-Modus in Kombination mit einem vollständig verteilten Cluster ist nützlich, um Pig auf großen Datensätzen auszuführen.
Warum Apache Pig verwenden?
In der Vergangenheit war es für Programmierer, die Java nicht beherrschten, schwierig, Hadoop zu nutzen. Besonders schwierig war es für sie, MapReduce-Aufgaben zu erledigen.
Dieses Problem konnte mit Apache Pig gelöst werden. Durch die Verwendung der Sprache Pig Latin können Programmierer MapReduce-Aufgaben einfach durchführen, ohne komplexe Codes in Java eintippen zu müssen.
Darüber hinaus basiert Apache Pig auf einem „Multi-Request“-Ansatz, der die Länge des Codes reduziert. Eine Operation, die in Java 200 Zeilen Code erfordern würde, kann mit Pig auf nur 10 Zeilen reduziert werden. Im Durchschnitt reduziert Apache Pig die Entwicklungszeit um den Faktor 16.
Ein Vorteil der Sprache Pig Latin ist, dass sie der Sprache SQL relativ ähnlich ist. Eine Person, die an SQL gewöhnt ist, wird Pig leicht beherrschen.
Schließlich werden viele Operatoren nativ bereitgestellt. Sie unterstützen die verschiedenen Datenoperationen. Das Tool bietet auch Datentypen wie Tupel, Bags und Maps, die in MapReduce fehlen.
💡Auch interessant:
| Apache Spark |
| Apache Kafka |
| Apache Cassandra |
| Apache Schulung |
| Apache Airflow |
| Apache Flume |
| Apache Storm |
Die Anwendungen von Apache Pig
Apache Pig wird in der Regel von Datenwissenschaftlern verwendet, um Aufgaben zu erledigen, die Hadoop-Verarbeitung und Rapid Prototyping beinhalten. Es wird insbesondere zur Verarbeitung riesiger Datenquellen wie Web-Logs verwendet.
Das Tool ermöglicht auch die Verarbeitung von Daten für Forschungsplattformen. Schließlich kann es auch zeitkritische Datenlasten verarbeiten.
Die Eigenschaften und Stärken von Apache Pig
Hier sind die wichtigsten Merkmale und Funktionen von Apache Pig. Die Programmiersprache Pïg Latin, die SQL ähnelt, macht es einfach, ein Pig-Skript zu schreiben.
Ein großer Satz von Operatoren ermöglicht eine Vielzahl von Datenoperationen. Ausgehend von diesen Operatoren können die Benutzer ihre eigenen Funktionen zum Lesen, Verarbeiten und Schreiben von Daten entwickeln.
Es ist auch möglich, UDFs (user-defined functions) oder benutzerdefinierte Funktionen in anderen Programmiersprachen wie Java zu erstellen. Sie können dann aufgerufen oder in Pig-Skripte eingebaut werden.
Darüber hinaus optimieren Apache-Pig-Aufgaben automatisch ihre Ausführung. Programmierer können sich also ausschließlich auf die Semantik der Sprache konzentrieren.
Mit Apache Pig ist es möglich, alle Arten von strukturierten und unstrukturierten Daten zu analysieren. Die Ergebnisse der Analysen werden im HDFS von Apache Hadoop gespeichert.
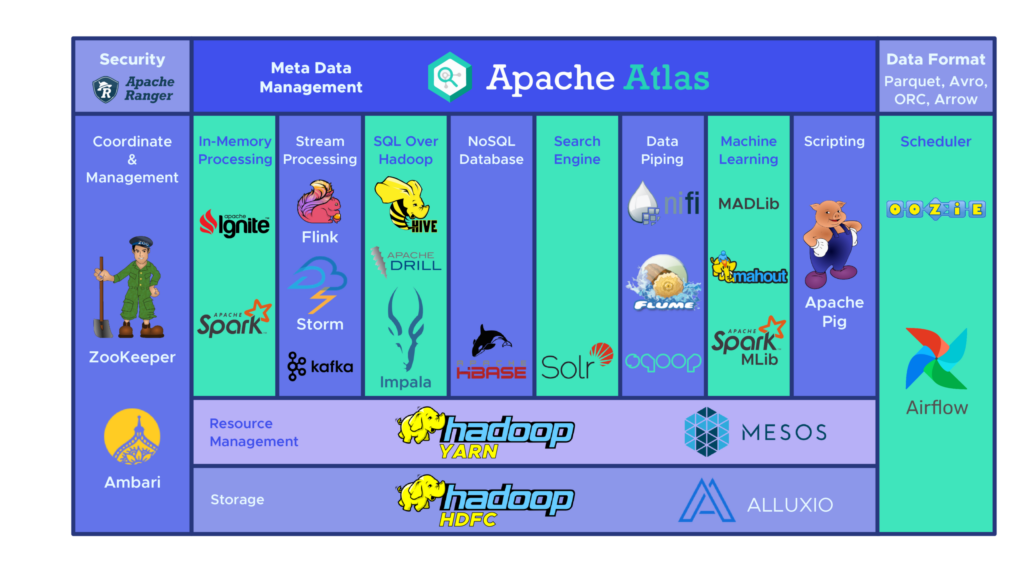
Apache Pig vs MapReduce
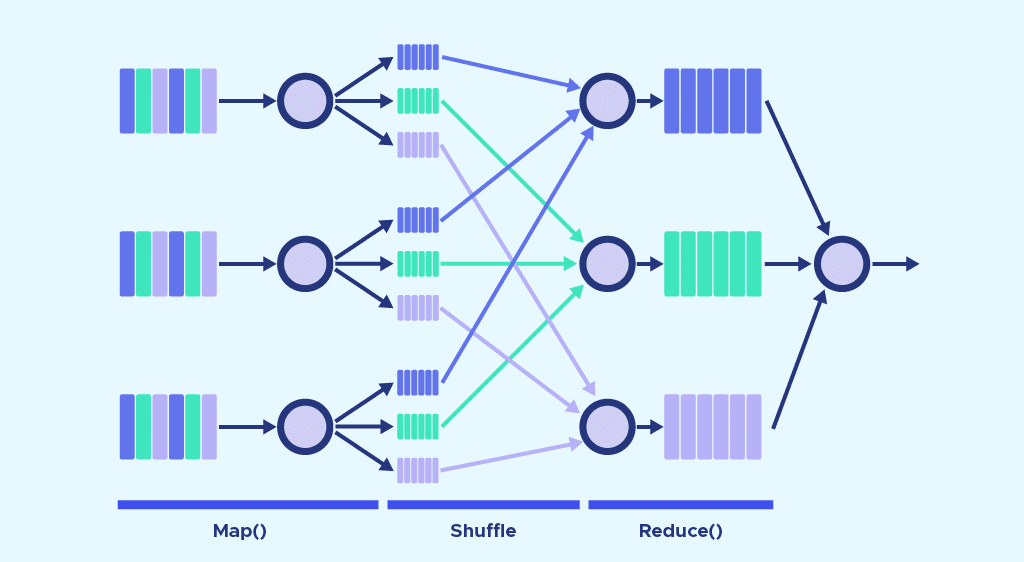
Es gibt einige wichtige Unterschiede zwischen Apache Pig und MapReduce. Zunächst einmal ist MapReduce ein Paradigma zur Datenverarbeitung, während Pig eine Sprache für Datenströme ist.
Es ist eine Hochsprache, während MapReduce eine Low-Level-Sprache ist. Es ist schwierig, mit MapReduce eine Joint-Operation zwischen Datasets durchzuführen, während dies mit Pig eine einfache Aufgabe ist.
Jeder Programmierer mit Kenntnissen in SQL kann mit Apache Pig arbeiten, während für MapReduce Java-Kenntnisse erforderlich sind.
Ein weiterer Unterschied betrifft die Länge der Codezeilen. Dank seines Multi-Query-Ansatzes benötigt Apache Pig 20-mal weniger Zeilen als MapReduce, um die gleiche Aufgabe zu erledigen.
Schließlich beinhalten Mapreduce-Aufgaben einen langen Kompilierungsprozess. Bei Pig ist keine Kompilierung erforderlich, da jeder Operator zur Laufzeit intern in einen MapReduce-Job umgewandelt wird.
Apache Pig vs SQL
Apache Pig hat Ähnlichkeiten mit SQL, aber auch Unterschiede. Während Pig Latin eine prozedurale Sprache ist, ist SQL eine deklarative Sprache.
Außerdem ist ein Schema in SQL obligatorisch, während es bei Pig optional ist. Es ist möglich, Daten zu speichern, ohne ein Schema zu entwerfen.
Es gibt mehr Möglichkeiten zur Abfrageoptimierung in SQL, während diese in Pig eingeschränkt sind. Außerdem kann man mit Pig Latin eine Pipeline zerlegen, Daten überall in der Pipeline speichern und ETL-Funktionen (Extraktion, Transformation, Laden) ausführen.
Apache Pig vs Hive

Apache Pig wurde von Yahoo und Hive von Facebook entwickelt. Ersteres verwendet die Sprache Pig Latin, letzteres die Sprache HiveQL.
Während Pig Latin eine Datenflusssprache und eine prozedurale Sprache ist. HiveQL ist eine Sprache zur Verarbeitung von Abfragen und eine deklarative Sprache.
Hive schließlich unterstützt hauptsächlich strukturierte Daten. Pig wiederum kann strukturierte, unstrukturierte und halbstrukturierte Daten unterstützen.
Da immer mehr Unternehmen Big Data einsetzen, ist die Beherrschung von Apache Pig eine sehr gefragte Fähigkeit. Sie ist sehr nützlich, um große Datensätze mit Hadoop einfach zu verarbeiten und zu analysieren.
Um den Umgang mit diesem Werkzeug zu erlernen, kannst du dich für die DataScientest-Schulungen entscheiden. Das Apache Hadoop-Framework und seine verschiedenen Komponenten wie Pig, Hive, Spark und HBase stehen auf dem Lehrplan des Moduls Big Data Volume der Data Engineer-Ausbildung.
Die anderen Module dieses Lehrgangs sind Programmierung, Datenbanken, Automatisierung und Einsatz. Nach Abschluss dieses Kurses wirst du alle Fähigkeiten besitzen, um als Data Engineer zu arbeiten.
Alle unsere Kurse werden als Weiterbildung oder als Bootcamp angeboten. Unser innovativer „Blended Learning“-Ansatz verbindet Präsenzlernen mit Online-Fernunterricht.
Die Lernenden erhalten ein von der Universität Sorbonne zertifiziertes Diplom, und 93 % der Alumni haben sofort einen Job gefunden. Warte nicht länger und entdecke die berufsbegleitende Weiterbildung zum Data Engineer.







