
Was ist Apache Storm ?
Apache Storm ist ein verteiltes Open-Source-System zur Verarbeitung von Echtzeit-Datenströmen, das hauptsächlich in Clojure entwickelt wurde. Es ermöglicht die Verwaltung von kontinuierlichen Datenströmen. Storm wird heute vielfach in sozialen Netzwerken, Online-Spielen oder auch in industriellen Überwachungssystemen eingesetzt.
Apache Storm wurde ursprünglich von Nathan Marz für das Startup Backtype entwickelt, das von Twitter aufgekauft wurde.
Apache Storm legt großen Wert darauf, so einfach wie möglich zu bleiben, was es Entwicklern ermöglicht, Topologien mit jeder Programmiersprache zu erstellen. Die Entwicklung von Storm erfordert die Manipulation von Tupeln (zur Erinnerung: Ein Tupel ist eine benannte Liste von Werten).
Diese Tupel können jeden beliebigen Objekttyp enthalten, und selbst wenn Apache Storm den Typ nicht kennt, ist es leicht möglich, einen Serialisierer zu implementieren.
Wie ist Apache Storm aufgebaut?
Apache Storm verwendet eine „Master – Slave“ Architektur mit den folgenden Komponenten:
- Nimbus: Dies ist der Masterknoten, der für die Verteilung des Codes unter den Supervisoren, die Zuweisung der Eingabedatensätze an die Maschinen zur Verarbeitung und die Überwachung von Ausfällen verantwortlich ist.
- Zookeeper: Koordiniert und verwaltet die Prozesse der Datenverteilung.
Supervisors: Dienste, die auf jedem Worker-Knoten ausgeführt werden, die die Arbeitsprozesse verwalten und ihre Ausführung überwachen. - Workers: Sind die mehreren oder einzelnen Prozesse auf jedem Knoten, die von den Supervisors gestartet werden. Sie führen eine parallele Verwaltung von Dateneingaben durch und senden die Daten an eine Datenbank oder ein Dateisystem.
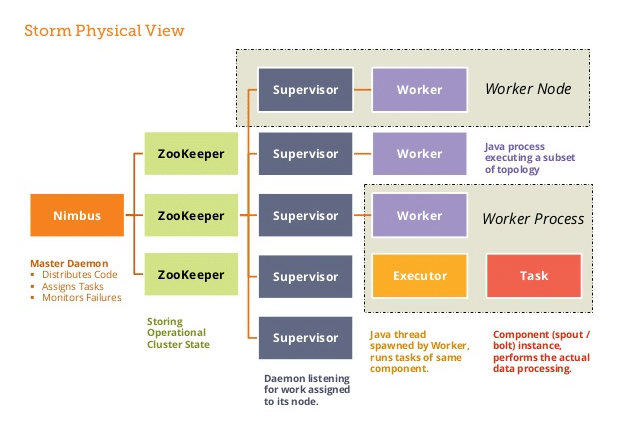
Topologie des Tools
Die Topologie in Apache Storm verwendet ein azyklisches gerichtetes Graphensystem (DAG). Sie funktioniert ähnlich wie die MapReduce-Jobs in Hadoop.
Die Topologie besteht aus den folgenden Elementen:
- Spouts: Sie sind der Eingangspunkt für die Datenströme. Sie verbinden sich mit der Datenquelle, rufen die Daten kontinuierlich ab, wandeln die Informationen in Tupelströme um und senden diese Ergebnisse an die Bolts.
- Bolts: Sie speichern die Verarbeitungslogik. Sie führen verschiedene Funktionen aus (z. B. Aggregation, Joining, Filtern usw.). Die Ausgabe erzeugt über zusätzliche Bolts neue Ströme für eine neue Verarbeitung oder speichert die Daten in einer Datenbank oder einem Dateisystem.
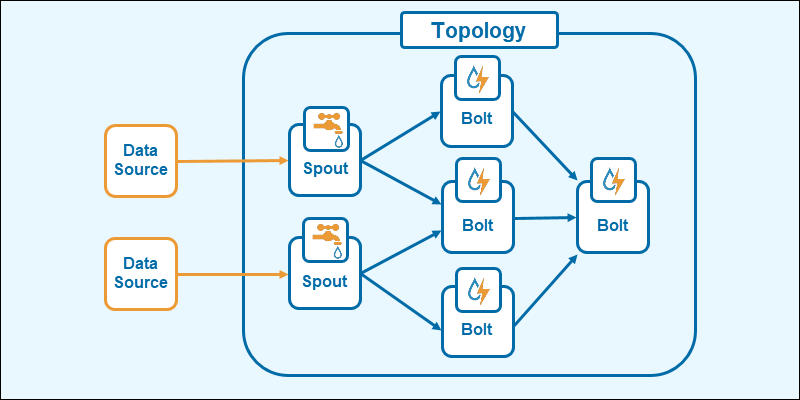
Dieses Schema zeigt, dass die Topologie in Apache Storm eine Verkettung von Verarbeitungsschritten ist, deren Verteilung von Bolts und Spouts sehr schnelle Ergebnisse ermöglicht.
Modell der Parallelität in Apache Storm: Was ist das?
Apache Storm verwendet ein auf Tasks und Bolts basierendes Parallelisierungsmodell. Die Daten werden von einer Reihe paralleler Tasks verarbeitet, die mithilfe von Bolts miteinander verbunden sind.
Jede der Aufgaben verarbeitet eine Teilmenge der Eingabedaten, und die Bolts ermöglichen es, die Aufgaben miteinander zu verbinden, um Datenströme zu erzeugen.
Dadurch kann Storm die Daten auf verteilte Weise verarbeiten, was die Leistung erhöht, wenn mehrere Maschinen die Daten gleichzeitig verarbeiten.
DRPCs (Distributed Remote Procedure Call) ermöglichen die Parallelisierung von sehr intensiven und verbrauchsintensiven Berechnungen. Sie verhalten sich mehr oder weniger wie ein Spout, mit dem Unterschied, dass die Datenquellen die Argumente der Funktion sind und diese eine Antwort in Form von Text oder json für jeden dieser Streams zurückgibt.
Sie sind nützlich für zeitraubende Berechnungen, um die Antwortzeiten zu verkürzen.
Auch interessant: Apache Schulung
Fehlertoleranz in Apache Storm
Bei der Verwaltung von Big-Data-Prozessen kann die Informationsüberlastung zu Fehlern oder Ausfällen auf bestimmten Clustern führen. Daher ist es wichtig, dass Storm trotz eines Ausfalls weiterarbeiten kann.
Wenn ein Worker fehlschlägt oder ausfällt, wird er von Storm automatisch neu gestartet.
Wenn ein ganzer Knoten abstürzt, startet Storm die Aufgaben, die auf anderen Workern liefen, neu. Auch wenn der Nimbus oder die Supervisoren abstürzen, werden sie automatisch neu gestartet.
Es ist sogar möglich, das Beenden eines Prozesses zu erzwingen (z. B. mit taskkill -9), ohne Cluster oder Topologien zu beeinflussen.
Auch interessant: Transactional Database
Die verschiedenen Garantieniveaus
Storm bietet mehrere Garantiestufen für die Verarbeitung von Datenströmen an:
- At most once: Dies ist die Standard-Garantiestufe. Sie garantiert, dass jedes Tupel mindestens einmal verarbeitet wird.
- At least once: Diese Garantie bedeutet, dass jedes Tupel mindestens einmal verarbeitet wird. Sie kann dazu führen, dass einige Tupel doppelt verarbeitet werden.
- Exactly once: Diese Garantie bedeutet, dass jedes Tupel genau einmal verarbeitet wird. Dies ist die höchste Garantiestufe, aber auch die komplizierteste, da sie Bibliotheken von Drittanbietern erfordert.
Trident
Trident ist eine High-Level-Abstraktion, die eine API für die Transformation und Aggregation von Daten in Echtzeit bereitstellt. Es ermöglicht Entwicklern, sich auf die Geschäftslogik zu konzentrieren, anstatt sich mit den Details der Implementierung von Verarbeitungsaufgaben zu beschäftigen. Es bietet eine Statusverwaltung, was die Verwaltung von Daten im Speicher für langfristige Verarbeitungsaufgaben erleichtert, und es unterstützt verteilte Transaktionen, um die Zuverlässigkeit der Daten zu gewährleisten.
Apache Storm vs. Apache Spark
Obwohl diese beiden Technologien, Apache Storm und Apache Spark, unterschiedliche Verwendungszwecke haben, werden sie dennoch beide häufig bei der Verwaltung von Big Data eingesetzt. Die folgende Tabelle zeigt den Vergleich zwischen diesen beiden Technologien.
| Storm | Spark | |
|---|---|---|
| Architektur | Micro-batch | Micro-batch/batch |
| Type de traitement | Streaming Echtzeit | Streaming Echtzeit und Batch-Bearbeitung |
| Latenz | Ein paar Millisekunden | Ein paar Sekunden |
| Skalierbarkeit | Tausende Knoten | Zehntausende Knoten |
| Unterstützte Sprachen | Keine Unterscheidung | Java, Scala, Python, R |
| Benutzung | Bearbeitung von Datenströmen in Echtzeit | Bearbeitung von Datenströmen in Echtzeit und Stapelverarbeitung |
Fazit
Zusammenfassend lässt sich sagen, dass Apache Storm ein System zur Verarbeitung von verteilten Datenströmen ist, mit dem große Datenmengen in Echtzeit effizient und zuverlässig verarbeitet werden können.
Mit seiner flexiblen und skalierbaren Plattform hat sich Apache Storm als beliebte Wahl für Unternehmen erwiesen, die Daten in Echtzeit verarbeiten und entsprechende Entscheidungen treffen wollen.







