
Die Ursprünge von Apache Flink
Apache Flink wurde ursprünglich an der Technischen Universität Berlin entwickelt. Die ersten Versionen wurden 2011 veröffentlicht und sollten komplexe Probleme bei der Verarbeitung von Daten in einer verteilten Echtzeitumgebung lösen. Flink wurde im Laufe der Jahre zu einer Referenz für eine Vielzahl von Unternehmen, bis es schließlich zu einem der beliebtesten Open-Source-Frameworks wurde. Es war im Jahr 2014, als Flink als Apache Incubator-Projekt akzeptiert wurde, und 2015 wurde es zu einem Apache Top-Level-Projekt. Seitdem hat sich Flink stetig verbessert und ist stolz auf seine aktive Entwickler- und Nutzergemeinschaft.
Zusammensetzung des Flink-Ökosystems
Das Ökosystem von Apache Flink besteht aus mehreren Schichten und Abstraktionsebenen, wie in der folgenden Abbildung dargestellt:
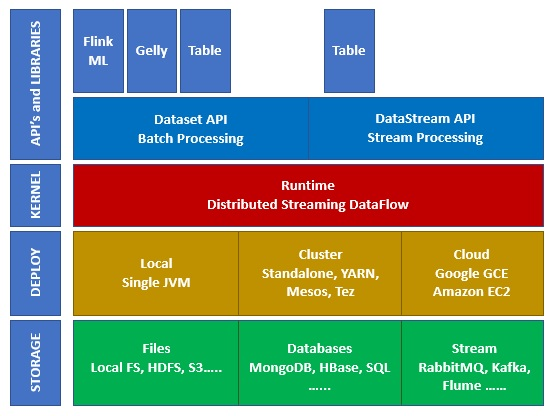
Storage (Speicherung) : Flink hat mehrere Möglichkeiten, Daten zu lesen/schreiben, z. B. HDFS (Hadoop), S3, lokal, Kafka, u. v. m.
Deploy (Einsatz): Flink kann lokal, auf Clustern oder in der Cloud eingesetzt werden.
Kernel (Kern): Hierbei handelt es sich um die Ausführungsschicht, die die Fehlertoleranz, die verschiedenen verteilten Berechnungen usw. vorgibt.
API’s & Libraries (APIs und Bibliotheken): Dies ist die oberste Schicht des Flink-Ökosystems. Hier befinden sich die Datastream-API, die für die Verarbeitung von Datenströmen zuständig ist, die Dataset-API, die für die Stapelverarbeitung zuständig ist, und andere Bibliotheken wie Flink ML (Machine Learning), Gelly (Graph Processing) und Table (für SQL).
Wie ist die Architektur von Flink aufgebaut?
Apache Flink ist eine verteilte Verarbeitungsmaschine für zustandsbehaftete Berechnungen auf begrenzten oder unbegrenzten Datenströmen.
Sie wurde so konzipiert, dass sie in allen gängigen Cluster-Umgebungen funktioniert und in der Lage ist, Berechnungen mit sehr hoher Geschwindigkeit und in beliebigem Maßstab durchzuführen.
Jede Art von Daten wird als Stream produziert, seien es Messwerte von Sensoren (IoT), Ereignisprotokolle (Logs) oder sogar Benutzeraktivitäten auf Webseiten.
Wie wir gerade gesehen haben, können die verarbeiteten Ströme entweder begrenzt oder unbegrenzt sein, aber was bedeutet das genau?
Unbegrenzte Feeds haben einen Anfang, aber kein definiertes Ende, was bedeutet, dass sie die Daten so liefern, wie sie erzeugt werden. Sie müssen kontinuierlich verarbeitet werden, d. h. unmittelbar nach der Aufnahme.
Daher kann man nicht warten, bis der gesamte Strom eingetroffen ist, um ihn zu verarbeiten, sondern muss die Ströme in der Reihenfolge verarbeiten, in der sie eintreffen.
Die genaue Kontrolle von Zeit und Status ermöglicht es Apache Flink, jede Art von Anwendung auf diesen Streams auszuführen.
Begrenzte oder beschränkte Streams haben einen definierten Anfang und ein definiertes Ende. Im Gegensatz zu unbegrenzten Streams können sie erst verarbeitet werden, nachdem sie alle Daten für Berechnungen aufgenommen haben. Ihre geordnete Verarbeitung ist daher nicht notwendig. Die Verarbeitung dieser Streams wird auch als Stapelverarbeitung oder Batch-Processing bezeichnet.
Diese Streams werden intern mit Algorithmen und Berechnungen verarbeitet, die speziell für Datasets mit fester Größe entwickelt wurden.
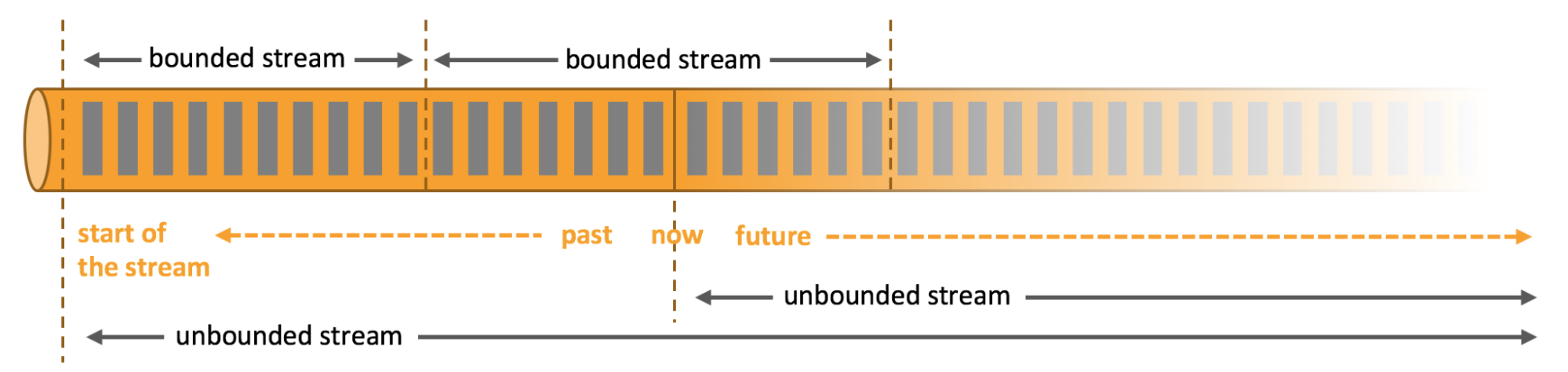
Es ist leicht zu verstehen, dass Flink eine hervorragende Leistung bei der Verarbeitung von begrenzten oder unbegrenzten Datenmengen bietet.
💡Auch interessant:
| Apache Spark |
| Apache Kafka |
| Apache Cassandra |
| Apache Schulung |
| Apache Airflow |
| Apache Flume |
| Apache Storm |
Welche Anwendungen sind durch API's mit Flink verbunden?
Apache Flink bietet eine Reihe von umfangreichen APIs, mit denen Transformationen sowohl auf Batch- als auch auf Streaming-Daten durchgeführt werden können. Diese Transformationen werden auf verteilten Daten durchgeführt und ermöglichen es Entwicklern, eine Anwendung zu bauen, die ihren Anforderungen entspricht.
Hier sind die wichtigsten APIs, die Flink anbietet:
Die API Datastream :
Diese API ist die wichtigste Programmierschnittstelle für die Erstellung von Datenströmen (Stream Processing).
Sie bietet eine hohe Abstraktionsebene für deren Manipulation und native Unterstützung für die Partitionierung von Daten für die parallele Verarbeitung.
Die API Dataset :
Die API ist eine Programmierschnittstelle für die Verarbeitung von Batchdaten. Sie bietet auch native Unterstützung für die parallele Verarbeitung in großem Maßstab.
Sie basiert auf dem MapReduce-Modell, bietet aber erweiterte Möglichkeiten, wie z. B. verteilte Zustände, Fehlerbehandlung und automatische Optimierung.
Die API Tabelle :
Diese API ist eine Programmierschnittstelle für die Verarbeitung von relationalen Daten. Sie ermöglicht es Entwicklern, Datenverarbeitungsprogramme zu erstellen, die auf Tabellen und SQL-Abfragen basieren, und dabei die Vorteile von Flink zu nutzen.
Sie ist mit den anderen APIs von Flink kompatibel, so dass du die verschiedenen Schnittstellen leicht kombinieren kannst, um spezifische Datenverarbeitungsanforderungen zu erfüllen.
Die mit diesen APIs erstellten Programme sind dank der verteilten Architektur von Flink leicht skalierbar und ausfallsicher. Sie können auf großen Rechenclustern ausgeführt werden und garantieren so eine hohe Leistung und Verfügbarkeit.
Beachte: Es gibt auch API's FlinkML für Machine Learning, Gelly für graphorientierte Datenbanken oder CEP für komplexe Verarbeitung (Complex Event Processing).
Schlüsselfunktionen von Flink
Apache Flink verfügt über die im Folgenden aufgeführten Schlüsselbegriffe:
- Parallelisierung ermöglicht Apache Flink die Verarbeitung von Daten durch die Verteilung von Aufgaben auf mehrere Verarbeitungsknoten (sog. „Slots“) gleichzeitig.
- Dadurch wird die Zeit für die Datenverarbeitung erheblich verkürzt, da die Ressourcen der verteilten Umgebung voll ausgenutzt werden. Aufgaben können in mehrere Teilaufgaben aufgeteilt werden, die dann parallel ausgeführt werden, wodurch die Verarbeitungseffizienz gesteigert wird.
- Bei der Datenverteilung werden die Daten in kleine Gruppen, sogenannte „Partitionen“, aufgeteilt, die dann auf mehrere Verarbeitungsknoten verteilt werden.
- Die Partitionen können anhand von Schlüsseln, Werten oder anderen Verteilungskriterien aufgeteilt werden, damit sie effizienter verarbeitet werden können und somit Engpässe vermieden werden.
- Diese Funktion ist ein grundlegender Aspekt der Parallelisierung in Apache Flink.
Apache Flink ist so konzipiert, dass es durch Checkpointing fehlertolerant ist, d. h. es kann die Daten auch dann weiterverarbeiten, wenn ein oder mehrere Verarbeitungsknoten ausfallen. - Es kann Ausfälle automatisch erkennen und die Daten entsprechend replizieren.
Vergleich zwischen Flink und Spark Streaming
| Eigenschaft | Apache Flink | Spark Streaming |
|---|---|---|
| Echtzeitverarbeitung | ✅ | ✅ |
| Stream-Verarbeitung | ✅ Verarbeitung von endlosen Streams mit sehr geringer Latenz |
✅ Beschränkt durch Batchgrößen und zugehörige Latenzzeiten |
| Batch-Verarbeitung | ✅ | ❌ |
| Modell | ✅ Basiert auf Operator-Transformationen |
✅ Basiert auf RDD-Transformationen |
| Graphen | ✅ Über die Gelly-API |
❌ Nicht unterstützt |
| Sprachen | ✅ Python, Java und Scala |
✅✅ Python, Java und Scala |
| Fehlerkorrektur | ✅ Behandelt Ausfälle von Verarbeitungsknoten |
✅ Tolerant gegenüber Fehlern, aber weniger effizient |
Wo liegen die Grenzen von Flink?
Welche Einschränkungen hat Flink? Es hat jedoch einige Einschränkungen, die berücksichtigt werden müssen:
- Ressourcenbedarf: Es benötigt eine Menge Ressourcen, um effizient ausgeführt zu werden, insbesondere für die Datenspeicherung und die Rechenleistung.
- Komplexe Implementierung: Es kann für Entwickler mit wenig Erfahrung in der Echtzeitdatenverarbeitung schwierig zu implementieren sein. Die Lernkurve kann sehr hoch sein.
- Dokumentation: Seine Dokumentation ist umfassend, aber je nach Erfahrung des Lesers schwer zu verstehen.
- Ökosystem: Flink wurde schnell entwickelt, ist aber im Vergleich zu anderen Tools auf dem Markt relativ neu. Daher kann es sein, dass es in einigen Bereichen noch nicht ausgereift ist oder es an Funktionen mangelt.
- Upgrades: Code, der in früheren Versionen entwickelt wurde, ist nach einem API-Update nicht mehr kompatibel, was zeitaufwändig sein kann, um den Code wieder kompatibel zu machen.
Fazit
Zusammenfassend lässt sich sagen, dass Apache Flink ein äußerst leistungsfähiges und vielseitiges Framework für die Datenverarbeitung ist. Es bietet fortschrittliche Funktionen für Stream- und Batch-Verarbeitung und ermöglicht es den Benutzern, Datenverarbeitungsaufgaben in Echtzeit effizient und skalierbar durchzuführen.
Die Programmier-APIs von Flink sind einfach zu verwenden und bieten Entwicklern viel Flexibilität. Seine Fähigkeit, große Arbeitslasten zu bewältigen, macht ihn zu einer erstklassigen Wahl für Unternehmen und Organisationen aller Größen.
Obwohl Flink gewisse Einschränkungen hat, entwickelt es sich weiterhin schnell weiter, um den sich ändernden Bedürfnissen von Unternehmen gerecht zu werden.
Jetzt, da du alles über Apache Flink weißt, beginne einen Kurs, der dich in die Lage versetzt, dieses Tool zur Verarbeitung von Datenströmen vollständig zu beherrschen. Entdecke DataScientest!







