
Wenn du schon einmal versucht hast, Zeitreihen zu modellieren, hast du wahrscheinlich schon von ARMA- oder ARIMA-Modellen gehört. In Python ist die am häufigsten verwendete Bibliothek dafür Statsmodels. In diesem Artikel bieten wir dir einen kurzen Überblick über die Verwendung von statsmodels und einige Anwendungsbeispiele.
Was kann man mit Statsmodels machen?
Statsmodels ist eine Bibliothek zur Analyse und Modellierung von statistischen Daten. Sie bietet eine Reihe von Funktionen, die in klassischen Bibliotheken nicht vorhanden sind, z. B. sklearn.
Lineare Regression
Zunächst einmal ergänzt Statsmodels die klassische lineare Regression weitgehend, indem es neue Schätzer für die kleinsten Quadrate anbietet. Normalerweise werden die gewöhnlichen kleinsten Quadrate (OLS) verwendet, um die lineare Regression zu schätzen. Wenn jedoch einige Residuen korreliert sind, ist die lineare Regression nicht mehr effizient. Die verallgemeinerte kleinste Quadrate (GLS) kann dieses Problem lösen.
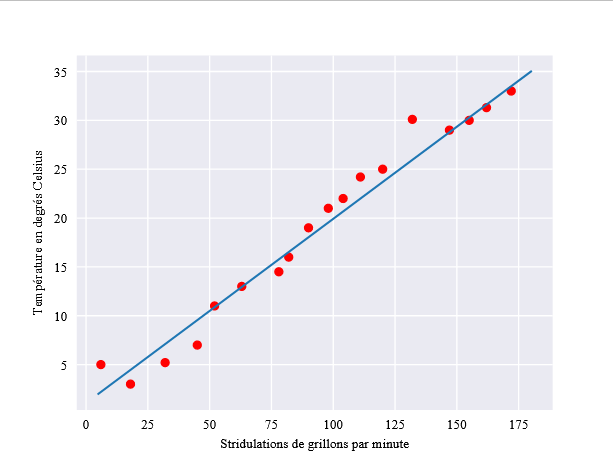
Parallel zu dieser Methode stellt statsmodels zwei weitere, komplexere Schätzer der gewöhnlichen kleinsten Quadrate vor: die rekursiven kleinsten Quadrate (RLS) und die mobilen kleinsten Quadrate (MLS).
Außerdem stellt die klassische lineare Regression eine Reihe von Annahmen auf, die während des Prozesses überprüft werden müssen. Statsmodels stellt verschiedene statistische Tests vor, mit denen :
- die Nicht-Multikollinearität der Variablen
- Homoskedastizität (Breusch-Pagan-Test)
- die Normalität der Rückstände (Jarque-Bera-Test)
Sehen wir uns ein Anwendungsbeispiel in Python an:
Verallgemeinerte lineare Modelle
Parallel dazu ermöglicht die statsmodels-Bibliothek die Verwendung von verallgemeinerten linearen Modellen (GLM), die eine Verallgemeinerung der klassischen linearen Regression darstellen.
Die lineare Regression geht davon aus, dass die zu erklärende Variable einer Normalverteilung folgt (diese Annahme wird durch die Normalverteilung der Residuen auferlegt). Bei der GLM kann eine beliebige Verteilung aus der Familie der Exponentialverteilungen verwendet werden.
Außerdem verbindet das GLM die zu erklärende Variable mit dem Modell über eine Verknüpfungsfunktion, was die klassische lineare Regression noch flexibler macht.
Ein Spezialfall des verallgemeinerten linearen Modells ist die logistische Regression. Die zu erklärende Variable folgt einer Binomialverteilung und es wird eine Logit-Link-Funktion verwendet.
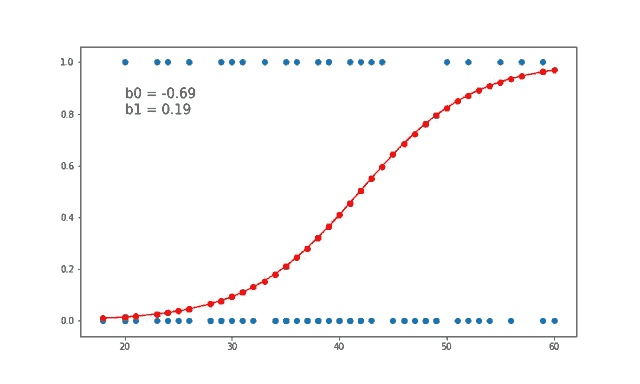
Zeitreihen :
Statsmodels stellt insbesondere zahlreiche Werkzeuge vor, die bei der Untersuchung von Zeitreihen sehr nützlich und umfangreich sind.
Zunächst einmal die Zerlegung in Trend, Saisonalität und Nachlauf. Wenn du mit diesen klassischen Komponenten von Zeitreihen nicht vertraut bist, empfehlen wir dir, unseren Artikel über Zeitreihen zu lesen.
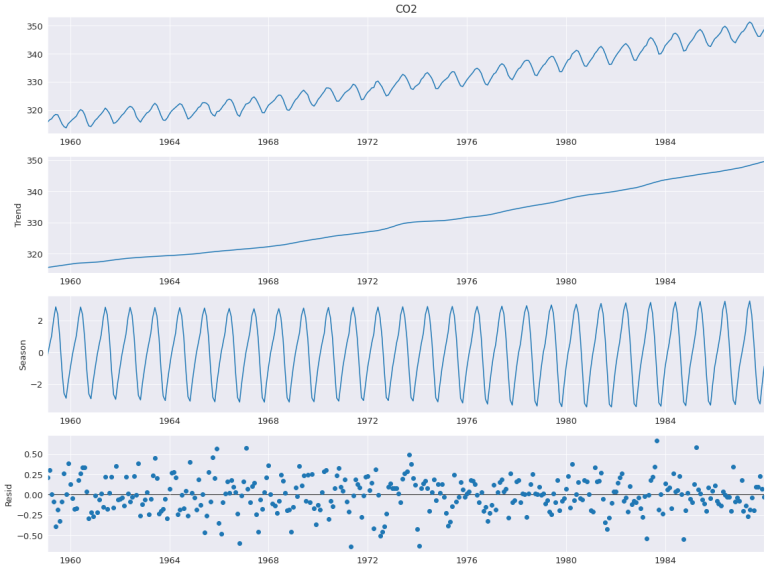
Diese Funktion ermöglicht es, auf einen Blick den Einfluss der verschiedenen Komponenten in unserem Modell zu erkennen, aber auch die Residuen zu visualisieren, um einen ersten Eindruck von ihrer Stationarität zu erhalten.
Statsmodels implementiert auch zwei statistische Tests, um die Stationarität von Zeitreihen zu überprüfen: den Augmented Dickey-Fuller-Test (ADF) und den KPSS-Test (Kwiatkowski-Phillips-Schmidt-Shin).
Und nicht zuletzt bietet statsmodels eine ganze Reihe klassischer Modelle zur Modellierung von Zeitreihen:
- Selbstregulierende Prozesse
- Gleitende Durchschnitte
- Die ARMA und ARIMA
- Die SARIMA, SARIMAX, VARIMAX
SARIMAX ist einfach ein SARIMA-Prozess, der parallel exogene Variablen verwendet, um die Zeitreihe vorherzusagen. VARIMAX ist ein vektorisierter ARIMAX-Prozess, der mehrere Werte gleichzeitig vorhersagen kann.
Zusätzlich zu den in diesem Artikel vorgestellten Funktionen bietet die Bibliothek statsmodels viele weitere Möglichkeiten und wird ständig erweitert. Um mehr zu erfahren, ist ihre Dokumentation mit vielen detaillierten Beispielen versehen.
Schlussfolgerung
Statsmodels ist ein unverzichtbares Werkzeug für Statistiker und Data Scientists, insbesondere bei der Untersuchung von Zeitreihen. Seine leicht verständliche und reproduzierbare Syntax ermöglicht es, statistische Reihen problemlos zu verwenden, zu modellieren und zu untersuchen.
Die Werkzeuge, die ein Data Scientist beherrschen muss, umfassen jedoch weitaus mehr Themen (Data Vizualisation, Machine Learning, Deep Learning, …), die du in unserer Data Scientist-Ausbildung kennenlernen kannst.







