
Das Akronym HDFS steht für Hadoop Distributed File System. Wie der Name schon sagt, ist HDFS eng mit dem Hadoop-Tool verbunden. Wozu dient HDFS? Was ist die Verbindung zwischen HDFS und Hadoop? Wie funktioniert HDFS? All diese Fragen werden wir mithilfe dieses Artikels beantworten.
HDFS: Was ist Hadoop?
Hadoop ist ein Open-Source-Tool, das die Welt der Informatik revolutioniert hat. Es ist insbesondere der Grund für die Entstehung von Big Data. Mit Big Data (Massendaten) sind wir gezwungen, große Datenmengen zu verarbeiten, und das ist mit herkömmlichen Werkzeugen eine langwierige und mühsame Aufgabe. Mit Hadoop gehen wir den Weg über eine verteilte Architektur, die Kosteneinsparungen und Leistungssteigerungen ermöglicht.
Der Unterschied zwischen einer verteilten und einer herkömmlichen Architektur besteht darin, dass ein Cluster von Maschinen, also eine Gruppe von Computern, verwendet wird.
Seit Hadoop werden die Daten zwischen den Rechnern im Cluster geteilt, sodass die Operationen parallelisiert werden. Dabei wird zwischen den Maschinen im Cluster unterschieden: Einige Maschinen besitzen die Daten und verarbeiten sie, während eine Maschine die Daten koordiniert. Diese Architektur wird allgemein als „master-slave“ (Meister-Sklave) bezeichnet. In Hadoop wird der „Master“-Rechner als Namenode bezeichnet und die „Slave“-Rechner werden als Datanodes bezeichnet.
Nachdem wir nun die Grundkenntnisse über Hadoop haben, können wir anfangen, über HDFS zu sprechen. Um mehr Informationen über Hadoop zu erhalten, kannst du diesen Artikel lesen.

Wozu dient HDFS ?
Wir haben die Operationen erwähnt, die mit Hadoop durchgeführt werden, aber dieses Tool besteht aus mehreren Komponenten. Wir verarbeiten die Daten mit MapReduce-Operationen, während die Yarn-Komponente dazu dient, die verschiedenen Maschinen in deinem Cluster zu überwachen und ihnen die nötigen Ressourcen zuzuweisen. HDFS wurde für die Speicherung von Dateien entwickelt. Wie der Name schon sagt (Hadoop Distributed File System zur Erinnerung), handelt es sich um ein Dateisystem.
Ähnlich wie beim Dateisystem unseres Betriebssystems können mit HDFS alle Dateitypen in verschiedenen Ordnern organisiert werden („hierarchical file system“). Dies gilt sowohl für „klassische“ Dateien wie csv oder json als auch für andere Dateitypen, die für Big-Data-Aufgaben verwendet werden, wie parquet, avro und orc. Wir sind nicht wie in einer relationalen Datenbank eingeschränkt, sondern sehen HDFS eher als Data Lake. Wir speichern dort die Rohdaten aus unserer Datenpipeline und verarbeiten sie dann in einem Data Warehouse oder in Datenbanken.
Wie funktionieren HDFS ?
Wenn man es mit einem klassischen Dateisystem eines Betriebssystems vergleichen kann, gibt es jedoch Unterschiede in der Nutzung und Speicherung.
Wir befinden uns in einem Cluster von Maschinen, also wie können wir wissen, auf welcher Maschine im Cluster unsere Daten gespeichert sind?
Wie du wahrscheinlich schon vermutet hast, werden wir Namenode verwenden. Um die verschiedenen Maschinen im Cluster verwalten zu können, muss der Namenode über den Status jeder Maschine Bescheid wissen, weshalb wir dort Metadaten finden können.
Insbesondere werden wir wissen, auf welchen Maschinen die Daten gespeichert sind. Ein weiterer Vorteil eines Hadoop-Clusters ist, dass wir „fault tolerant“ (ausfalltolerant) sind. Da wir mehrere Maschinen zur Verfügung haben, können wir Kopien unserer Daten erstellen und sie auf die Maschinen verteilen. Wenn also ein Rechner ausfällt, können wir immer noch auf die Daten zugreifen. Außerdem werden die Daten nicht „vollständig“ auf die Maschinen verteilt, sondern in Blöcke segmentiert. Dies ermöglicht es uns, uns gegen das Risiko eines Maschinenausfalls zu schützen, indem wir unsere Daten nur teilweise verlieren.
Betrachten wir das folgende Schema, um die Datenspeicherung in HDFS zu verstehen:
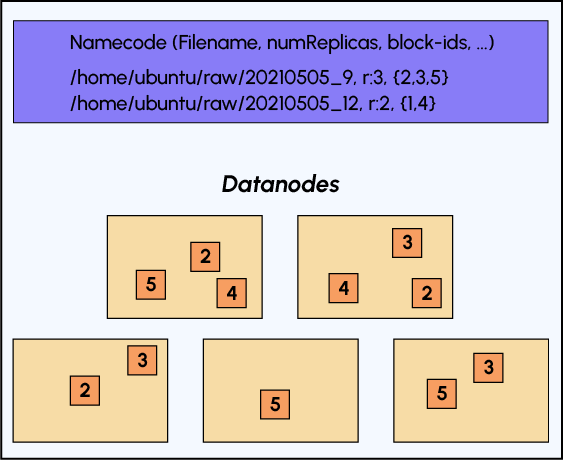
Wie bereits erwähnt, finden wir im Namenode die Metadaten unserer Datei: ihren Namen, die Anzahl der Replikate und ihre Segmentierung in Blöcke, aber es gibt auch andere Metadaten.
Diese Elemente bestätigen, dass sich die Verwendung von HDFS von der Verwendung eines Dateisystems über eine Tortendiagramm-Schnittstelle unterscheidet. Tatsächlich verwenden wir es eher unter dem Aspekt der Batchverarbeitung und greifen auf unsere Daten über einen Link wie diesen zu: „hdfs:/cluster-ip:XXXX//data/users.csv“.
Weiterführende Informationen
Nachdem wir verstanden haben, wie Hadoop funktioniert, wollen wir nun das HDFS-Dateisystem und die Hadoop-Suite üben. Allerdings ist es schwierig, sie als Privatperson zu verwenden.
Der erste Grund ist einfach, dass wir nicht über einen Cluster von Rechnern verfügen. Der zweite Grund ist, dass wir selbst mit einem Maschinencluster immer noch Hadoop darauf installieren und es in Big-Data-Problemen verwenden müssen, was für eine Privatperson selten notwendig ist.
Du kannst mehr über die verschiedenen Komponenten des Hadoop-Tools lernen, indem du den Data Engineer-Kurs von DataScientest absolvierst.
In unserer Weiterbildung wirst Du auch mehr über seinen „kleinen Bruder“ erfahren: Spark, das große Datenmengen viel schneller als Hadoop verarbeiten kann, aber keinen Speicheraspekt hat, weshalb es neben HDFS unterrichtet wird.







