
Ein Machine-Learning-Modell ist in der Lage, selbstständig aus einem Datensatz zu lernen, mit dem Ziel, Verhalten in einem anderen Datensatz vorherzusagen. Dazu findet es zugrunde liegende Beziehungen zwischen unabhängigen erklärenden Variablen und einer Zielvariablen im ursprünglichen Datensatz. Dann verwendet er diese Muster, um neue Daten vorherzusagen oder zu klassifizieren.
Wie wird die Funktion train_test_split definiert?
Um die Effektivität eines Machine-Learning-Modells zu überprüfen, wird der ursprüngliche Datensatz in zwei Sets aufgeteilt: ein Trainingsset und ein Testset. Das Trainingsset wird verwendet, um das Modell auf einem Teil der Daten zu fitten, d. h. zu trainieren. Das Testset wird verwendet, um die Leistung des Modells auf dem anderen Teil der Daten zu bewerten. Die Funktion train_test_split aus der ScikitLearn-Bibliothek (sklearn) in Python ermöglicht diese Aufteilung in zwei Sets.
Als Erstes solltest du daran denken, die Funktion train_test_split aus dem model_selection-Paket von sklearn zu importieren, indem du den folgenden Code benutzt:
Wenn die Funktion einmal importiert ist, hat sie mehrere Argumente:
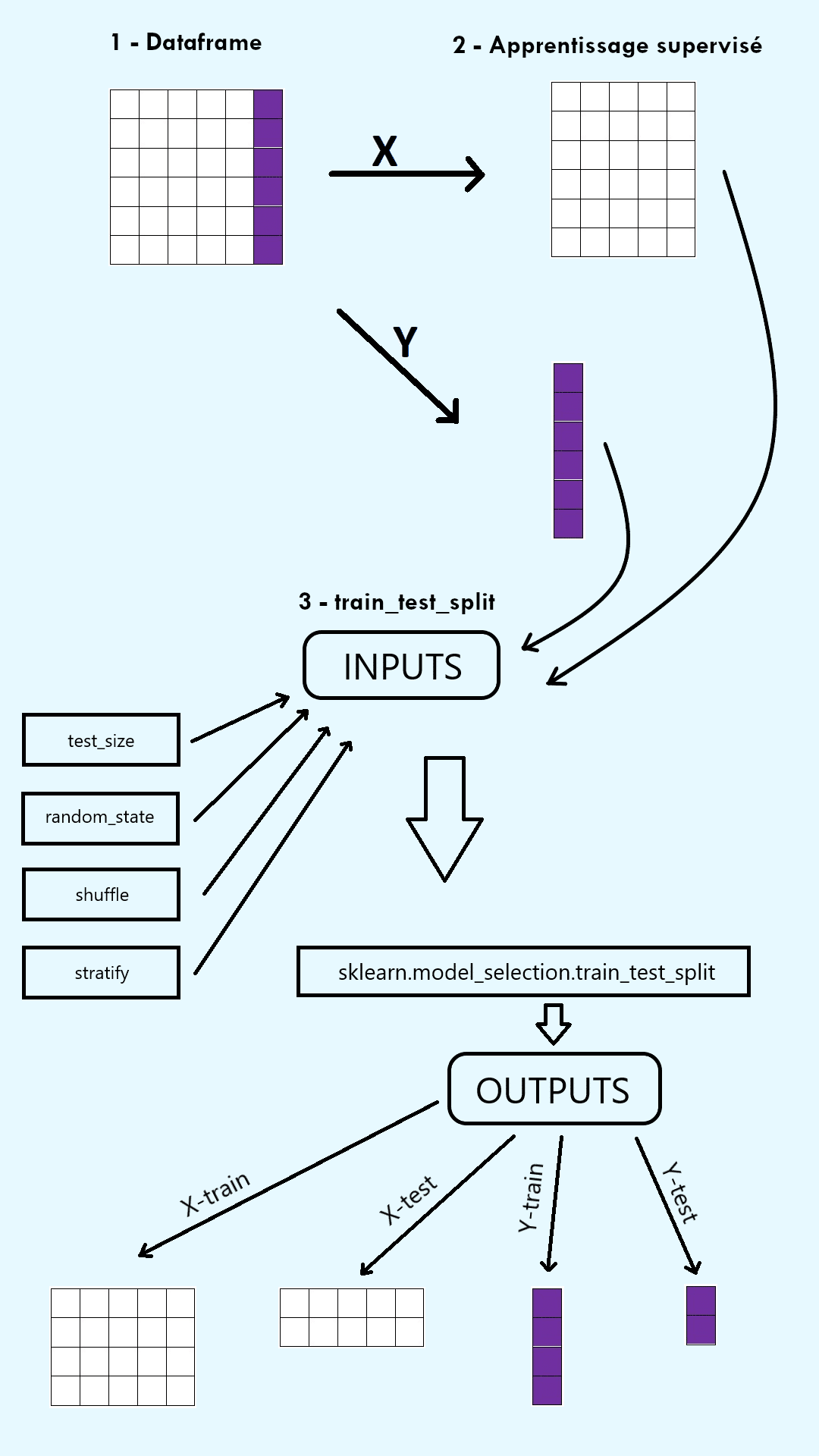
1) Arrays, die aus dem zu teilenden Datensatz entnommen wurden.
Beim überwachten Lernen sind diese Arrays das Input-Array X, das aus den erklärenden Variablen in den Spalten besteht, und das Output-Array y, das aus der Zielvariablen (d. h. den Labels) besteht.
Beim unbeaufsichtigten Lernen ist das einzige Array als Argument das Input-Array X, das aus den erklärenden Variablen in den Spalten besteht.
Hinweis: Achte auf die Dimensionen! X muss ein zweidimensionales Array sein. y muss ein eindimensionales Array sein, das der Anzahl der Zeilen in X entspricht. Um dies zu erreichen, kannst du gerne die Funktion .reshape verwenden.
2) Die Größe des Testsets (test_size) und die Größe des Trainingssets (train_size).
Die Größe jedes Satzes ist entweder eine Dezimalzahl zwischen 0 und 1, die einen Anteil des Datensatzes darstellt, oder eine ganze Zahl, die eine Anzahl von Beispielen des Datensatzes darstellt.
Hinweis: Es ist ausreichend, nur eines dieser Argumente zu setzen, das zweite ist komplementär dazu.
3) Der random state (random_state).
Der random state ist eine Zahl, die steuert, wie der Pseudo-Zufallsgenerator die Daten aufteilt.
Hinweis: Wenn du eine ganze Zahl als random state wählst, werden die Daten bei jedem Aufruf der Funktion auf die gleiche Weise aufgeteilt. Dies macht den Code also reproduzierbar.
4) Le shuffle (shuffle).
Shuffle ist ein Boolean-Wert, der auswählt, ob die Daten vor dem Trennen gemischt werden sollen oder nicht. Im Falle, dass sie nicht gemischt werden, werden die Daten also in der Reihenfolge getrennt, in der sie ursprünglich waren.
Hinweis: Der Standardwert ist True.
5) Stratify (stratify).
Der Stratify-Parameter wählt aus, ob die Daten so getrennt werden, dass der Anteil der Beobachtungen in jeder Klasse in den train- und test-Sets gleich bleibt wie im Ausgangsdatensatz.
Anmerkungen:
Diese Einstellung ist besonders nützlich angesichts von „unbalanced“-Daten mit sehr unausgewogenen Anteilen zwischen den verschiedenen Klassen.
Der Standardwert ist None.
Die Funktion train_test_split gibt eine Anzahl von Outputs zurück, die doppelt so hoch ist wie die Anzahl ihrer Inputs, und zwar in Form eines Arrays. Beim überwachten Lernen gibt sie also vier Outputs zurück: X_train, X_test, y_train und y_test. Beim unüberwachten Lernen gibt sie zwei Outputs zurück: X_train und X_test.
Wie kann man die Leistung eines Modells mit der Funktion train_test_split bewerten?
Sobald die Funktion train_test_split definiert ist, gibt sie eine Train- und eine Testmenge zurück. Dieses Datensplitting ermöglicht es, ein Machine-Learning-Modell aus zwei verschiedenen Blickwinkeln zu bewerten.
Das Modell wird mit der von der Funktion zurückgegebenen Trainmenge trainiert. Dann werden seine Vorhersagefähigkeiten anhand der Testmenge, die von der Funktion zurückgegeben wird, bewertet.
Für diese Bewertung können mehrere Metriken verwendet werden. Im Falle einer linearen Regression werden das Bestimmtheitsmaß, der RMSE und der MAE bevorzugt. Im Falle einer Klassifikation werden die Genauigkeit, die Präzision, der Recall und der F1-Score bevorzugt. Die Ergebnisse des Testsatzes zeigen also, wie gut das Modell ist und wie sehr es verbessert werden muss, bevor es auf einem neuen Datensatz vorhergesagt werden kann.
Die von der Funktion train_test_split zurückgegebenen train- und test-Sets spielen auch eine wichtige Rolle bei der Erkennung von Overfitting oder Underfitting. Zur Erinnerung: Overfitting beschreibt eine Situation, in der das erstellte Modell zu komplex ist (z. B. mit zu vielen erklärenden Variablen), so dass es die Trainingsdaten perfekt lernt, aber nicht in der Lage ist, auf andere Daten zu verallgemeinern.
Umgekehrt beschreibt Underfitting eine Situation, in der das Modell zu einfach oder schlecht gewählt ist (z. B. die Wahl einer linearen Regression für Daten, die nicht den Annahmen entsprechen), so dass es schlecht lernt.
Diese beiden Probleme können durch verschiedene Techniken behoben werden, aber sie müssen erst einmal gefunden werden, was mit der Funktion train_test_split möglich ist.
Wir können nämlich die Leistung des Modells in der Train- und der Testmenge, die von der Funktion erstellt wurden, vergleichen.
Wenn die Leistung in der Trainmenge gut ist, aber in der Testmenge schlecht, handelt es sich wahrscheinlich um Overfitting.
Wenn die Leistung im Trainsatz genauso schlecht ist wie im Testsatz, handelt es sich wahrscheinlich um Underfitting. Die beiden Mengen, die die Funktion zurückgibt, sind daher entscheidend für die Erkennung dieser wiederkehrenden Probleme im Machine Learning.
Wie löst man ein vollständiges Machine-Learning-Problem mithilfe der Funktion train_test_split?
Nachdem wir nun die Verwendung und die Funktionen der Funktion train_test_split verstanden haben, wollen wir sie anhand eines echten Machine-Learning-Problems in die Praxis umsetzen.
Schritt 1: Verständnis des Problems
Wir entscheiden uns dafür, ein überwachtes Lernproblem so zu lösen, dass die erwarteten Labels bekannt sind. Genauer gesagt konzentrieren wir uns auf eine binäre Klassifizierung. Ziel ist es, anhand von Körpermerkmalen vorherzusagen, ob eine Person an Brustkrebs erkrankt ist oder nicht.
Schritt 2: Daten wiederherstellen
Wir verwenden das Dataset „breast_cancer“, das in der Sklearn Library enthalten ist.
Mit den folgenden Codezeilen rufen wir die erklärenden Variablen (features) und die Zielvariable (target) ab:
Wir erhalten, dass die vorherzusagenden Zielvariablen zwei Werte annehmen („malignant“ und „benign“) und dass das Problem tatsächlich eine binäre Klassifizierung ist.
Schritt 3: Erstellen von X und y
Wir erstellen das zweidimensionale Input-Array X und das eindimensionale Output-Array y. Für dieses Dataset wird die binäre Kodierung der Zielvariablen von sklearn durchgeführt und kann direkt abgerufen werden.
Wir überprüfen, dass die Dimensionen von X und y übereinstimmen: y hat die gleiche Anzahl an Zeilen wie X.
Schritt 4: Erstellen von Train- und Testsets
Wir teilen die Daten in einen train_test_split.
Da wir der Funktion train_test_split zwei Arrays X und y übergeben, gibt sie vier Elemente zurück. Wir wählen einen Testsatz, der aus 10 % der Daten besteht. Wir wählen eine Zahl vom Typ „int“ als random state, um die Reproduzierbarkeit des Codes zu gewährleisten. Wir verwenden nicht die letzten Parameter der Funktion, da diese für ein so einfaches Problem nicht notwendig sind.
Schritt 5: Klassifikationsmodell
Um die Klassifizierungsaufgabe zu lösen, erstellen wir ein Modell der k-nächsten Nachbarn. Wir trainieren das Modell auf dem train set mit der Methode .fit(). Dann testen wir die Leistung des Modells auf dem Testset mit der Methode .predict(). So erhalten wir die vorhergesagten Klassen für die Beobachtungen des Testsets.
Schritt 6: Bewertung des Modells
Wir wählen als Metrik die Genauigkeit (accuracy). Die Genauigkeit ist die Anzahl der richtigen Vorhersagen im Verhältnis zur Gesamtzahl der Vorhersagen. Wir berechnen sie für die Train- und Testmenge mithilfe der Methode .score(), die die wahren Klassen im Datensatz mit den vom clf-Klassifikator vorhergesagten Klassen vergleicht.
Wir erhalten eine accuracy von 0,95 für die Trainmenge und von 0,93 für die Testmenge. Das Modell hat also eine gute Klassifikationsleistung.
Außerdem ist die Genauigkeit der Testmenge nur geringfügig geringer als die der Trainmenge. Das bedeutet, dass sich das Modell gut auf neue Daten verallgemeinern lässt. Wir haben es also nicht mit einem Overfitting-Problem zu tun.
Die Funktion train_test_split ist also einfach zu verwenden und sehr effizient, um ein komplettes Machine-Learning-Problem zu lösen.
Gibt es Grenzen für die Funktion train_test_split?
Die Funktion train_test_split hat jedoch eine Hauptbeschränkung, die mit dem Parameter random_state zusammenhängt. Wenn der Wert für random state eine ganze Zahl ist, werden die Daten mithilfe eines Pseudo-Zufallsgenerators, der mit dieser ganzen Zahl initialisiert wird und seed genannt wird, getrennt.
Die durchgeführte Trennung ist reproduzierbar, da derselbe Seed beibehalten wird. Es hat sich jedoch gezeigt, dass die Wahl des Seed die Leistung des zugehörigen Machine-Learning-Modells beeinflusst: Unterschiedliche Seds können unterschiedliche Sets und unterschiedliche Punktzahlen erzeugen.
Eine Lösung für dieses Problem besteht darin, die Funktion train_test_split mehrmals mit unterschiedlichen Werten für random_state zu verwenden. Wir können dann den Durchschnitt der erzielten Punktzahlen berechnen.
So ist die Funktion train_test_split aus der Python-Bibliothek sklearn bei richtiger Anwendung essentiell für die Durchführung eines Data Science-Projekts und die Bewertung eines Machine Learning-Modells!







