Wenn maschinelles Lernen es Organisationen ermöglicht, effizienter zu arbeiten und die besten Entscheidungen zu treffen, müssen die Experten für Datenwissenschaft die verschiedenen Algorithmen der künstlichen Intelligenz beherrschen. Es gibt nämlich mehrere Dutzend davon. Und jeder von ihnen erfüllt einen bestimmten Zweck. In diesem Artikel werden wir uns mit den verschiedenen Algorithmen zur Klassifizierung befassen.
Was sind Klassifizierungsalgorithmen?
Definition
Zunächst einmal solltest du dir ansehen, was ein Algorithmus ist: eine Reihe von Operationen, die in einer bestimmten Reihenfolge befolgt werden, um ein Problem zu lösen oder neue Lösungen zu finden. Zum Beispiel das Lernen durch ein System künstlicher Intelligenz.
Genau das ist die Rolle der Klassifizierungsalgorithmen, die beim maschinellen Lernen verwendet werden. Sie ermöglichen es der Software, selbstständig aus mehreren Datensätzen zu lernen.
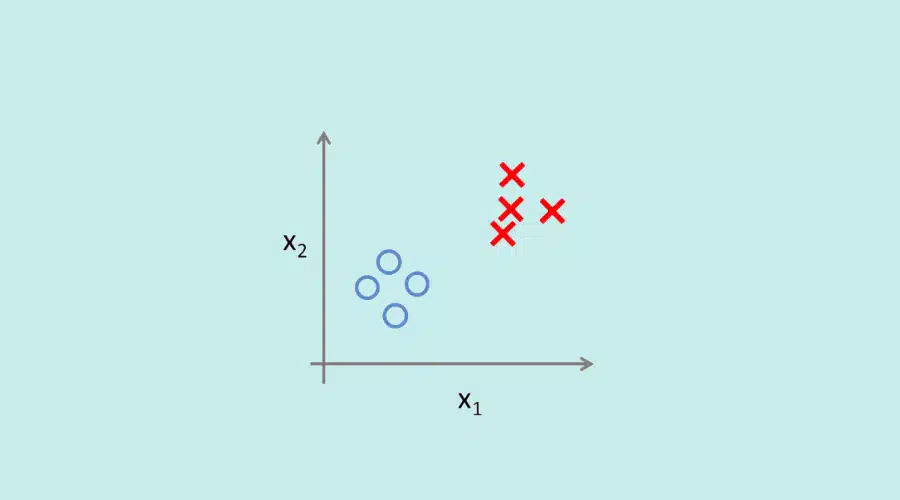
Die Idee ist, die verschiedenen Elemente eines Datensatzes in verschiedene Kategorien zu klassifizieren. Diese gruppieren die Datas nach ihrer Ähnlichkeit. Da die Daten gemeinsame Merkmale aufweisen, ist es einfacher, ihr Verhalten vorherzusagen.
Bei einem E-Commerce-Shop ist es z. B. wahrscheinlicher, dass Nutzer, die mehrmals auf die Seite zurückkehren, etwas kaufen, als diejenigen, die die Seite nie wieder besuchen. Der Klassifizierungsalgorithmus segmentiert die Nutzer also in verschiedene Kategorien, damit das Unternehmen seine Kommunikation anpassen kann.
Diese verschiedenen Lernmodelle können also sowohl für die Datenanalyse als auch für die vorausschauende Analyse verwendet werden.
Eine überwachte Klassifizierung
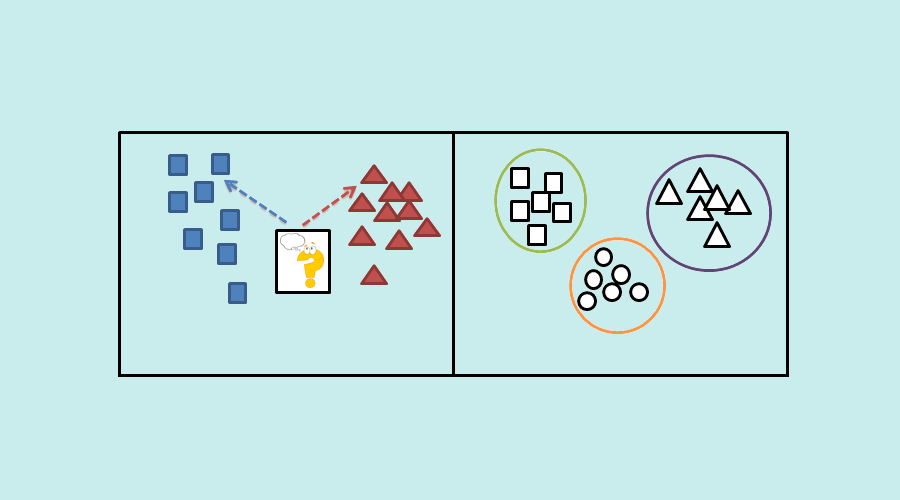
Klassifikationsalgorithmen gehören zu den überwachten Lernmethoden. Das heißt, dass die Vorhersagen anhand von historischen Daten getroffen werden.
Im Gegensatz zum unüberwachten Lernen, bei dem es keine vordefinierten Klassen gibt. Die Klassen müssen also anhand gemeinsamer Attribute gebildet werden, um dann die Vorhersage zu treffen.
Innerhalb der überwachten Algorithmen selbst gibt es einen Gegensatz zwischen klassifizierenden und prädiktiven (oder regressiven) Lernalgorithmen. Im letzteren Fall geht es darum, neue Daten auf der Grundlage eines bestimmten realen Wertes vorherzusagen, und nicht mehr auf der Grundlage einer Kategorie.
Was sind die wichtigsten Klassifizierungsmodelle?
Es gibt viele Algorithmen für überwachtes Lernen, die auf Klassifizierung basieren. Wir haben die wichtigsten in dieser nicht erschöpfenden Liste zusammengefasst.
Die Support Vector Machine (SVM)
Dieser Algorithmus wird als linearer Klassifizierer betrachtet. Seine Aufgabe ist es, die Datensätze durch Linien (sogenannte Hyperebenen) zu trennen.
Um dies zu erreichen, muss der Algorithmus die Abstände zwischen der Trennlinie und den verschiedenen Stichproben auf beiden Seiten maximieren. Diejenigen, die der Linie am nächsten liegen, werden als Stützvektoren bezeichnet.
Die Idee ist also, die optimale Hyperebene zu finden; diejenige, die die beiden Klassen perfekt voneinander unterscheidet, um die Klassifikationsfehler zu minimieren. Dies ermöglicht eine klare Trennung der Daten, um einfache Klassen leicht zu identifizieren. Zum Beispiel große und kleine Städte. Wenn es sich um komplexere Daten handelt, wie z. B. das genetische Material einer Person, ist es nicht so einfach, die verschiedenen Klassen zu identifizieren. Dieser Algorithmus wird daher nicht der relevanteste sein.
SVM wird häufig in der Finanzbranche eingesetzt, um aktuelle und zukünftige Leistungen, Renditen von Investitionen usw. zu vergleichen.
Gut zu wissen: Dieser Algorithmus wird hauptsächlich für die Klassifizierung von Daten verwendet, kann aber auch für Regressionen eingesetzt werden.
Entscheidungsbäume
Der Entscheidungsbaum ist ein Algorithmus, der die verschiedenen Daten in Form von Zweigen klassifiziert. Er geht von einer Wurzel aus, in der die einzelnen Daten je nach ihrem Verhalten eine bestimmte Richtung einschlagen. Dadurch werden dann die Antwortvariablen vorhergesagt.
Wie bei einem Baum werden die Schnittpunkte als Knoten und ihre Zwecke als Blätter bezeichnet. Die Knoten stellen dann die Regeln dar, mit denen die Daten in verschiedene Kategorien aufgeteilt werden, und die Blätter sind die Informationen selbst.
Hier ist ein sehr einfaches Beispiel:
| Mehr als 100 000 Einwohner | Berlin | |
|---|---|---|
| München | Frankfurt | Hamburg |
| Frankfurt | Nein | Ja |
| Hamburg | Nein |
Dieser Klassifikationsalgorithmus ist auch für Nicht-Datenexperten leicht verständlich. Bei großen Datenmengen wird er jedoch schwieriger zu verstehen.
Dieser Algorithmus wird z. B. für die Vorhersage von Zinssatzänderungen, die Reaktion des Marktes auf Änderungen usw. verwendet.
>> Auch interessant: Boosting-Algorithmen
Die Einteilung in K-Mittelwerte (K-means)
Dieser Klassifikationsalgorithmus sortiert die Daten anhand ihrer Eigenschaften in verschiedene Gruppen.
Dazu wird ein Referenzmittelwert aus einem Datensatz ermittelt, der dann ein typisches Profil definiert.
Der Vorteil des K-means-Algorithmus ist seine Genauigkeit. Dies gilt auch für die schnelle Verarbeitung großer Datenmengen.
Aufgrund seiner Effizienz ist K-means vielseitig einsetzbar: Suchmaschinen, um Ergebnisse zu liefern, die den Erwartungen der Nutzer entsprechen, Unternehmen, um das Verhalten von Interessenten oder Internetnutzern vorherzusehen, IT-Manager, um die Leistung von Systemen und Netzwerken zu analysieren, usw.
Der naive Bayes'sche Klassifikator
Dieser Algorithmus greift das Bayes’sche Theorem und die bedingten Wahrscheinlichkeiten auf.
Er baut auf gekennzeichneten Datensätzen auf und verknüpft sie mit anderen, nicht gekennzeichneten Daten, um sie zu klassifizieren.
Der naive Bayes’sche Klassifikator wird hauptsächlich bei der Verarbeitung natürlicher Sprache eingesetzt. Mit anderen Worten: Er ist das, was es Maschinen leichter macht, menschliche Sprache zu verstehen.
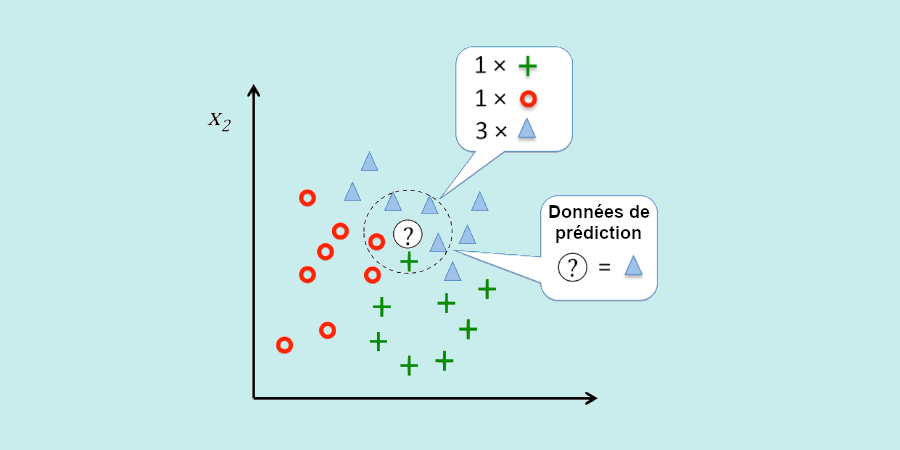
Le KNN (K-nearest neighbors)
Der K-Nearest-Neighbors-Algorithmus kann sowohl als Regressions- als auch als Klassifikationsalgorithmus verwendet werden. Häufig wird er jedoch in der zweiten Hypothese verwendet.
Die Idee ist, die Variablen in einem Datensatz zu klassifizieren, indem man die Ähnlichkeiten zwischen ihnen analysiert. Dazu verwendet das KNN ein Diagramm und berechnet den Abstand zwischen den verschiedenen Punkten. Diejenigen, die sich am nächsten sind, werden in der gleichen Kategorie gespeichert.
Lineare Regression
Dies ist einer der am häufigsten verwendeten Klassifikationsalgorithmen.
Die Idee dahinter ist, einfache Korrelationen zwischen Eingaben und Ausgaben herzustellen. Auf diese Weise kann erklärt werden, wie sich die Veränderung einer Variablen auf die andere auswirkt.
Es ist die Einfachheit dieses Modells, die es bei Datenwissenschaftlern so beliebt macht. Es benötigt nur wenige Parameter, lässt sich leicht grafisch darstellen und ist den Entscheidungsträgern leicht zu erklären.
Daher wird es häufig im Handel verwendet, um die Anzahl der Verkäufe zu prognostizieren oder um Risiken zu antizipieren.
Gut zu wissen:
Gut zu wissen: Im Gegensatz zur logistischen Regression, bei der die Kategorie der abhängigen Variable in Abhängigkeit von der unabhängigen Variable vorhergesagt wird, werden bei der linearen Regression die unabhängigen Variablen behandelt.
Perceptron
Es ist einer der einfachsten und vor allem einer der ältesten Algorithmen, da er 1957 von Frank Rosenblatt erfunden wurde.
Genauer gesagt handelt es sich um einen binären Klassifikationsalgorithmus. Er vergleicht dann die Summe mehrerer Eingangssignale. Wenn die Summe einen bestimmten Schwellenwert überschreitet oder nicht, schließt Perceptron auf ein Ergebnis, das von der vorab definierten Regel abhängt. Diese Regel wird als Perceptron Learning Rule bezeichnet und ermöglicht es dem neuronalen Netz, automatisch zu lernen.
Dieser Algorithmus erweist sich als sehr nützlich, um Trends in den Eingabedaten zu erkennen.
Neben diesen verschiedenen Klassifizierungsalgorithmen gibt es noch weitere, die dir helfen, deine Daten zu klassifizieren.
Wie lerne ich die Algorithmen des maschinellen Lernens kennen?
Klassifizierungsalgorithmen sind für das maschinelle Lernen unerlässlich und werden von Datenwissenschaftlern und Datenanalysten beherrscht. Um sie zu verstehen, muss man jedoch eine spezielle Ausbildung im Bereich Daten absolvieren. Dies ist der Fall bei DataScientest.







