
Phi-4 ist das neueste Sprachmodell, das von Microsoft entwickelt wurde und die Grenzen der Small Language Models mit nicht weniger als 14 Milliarden Parametern verschiebt. Es wurde für Spitzenleistungen im komplexen Denken entwickelt, insbesondere in der Mathematik, während es gleichzeitig in der klassischen Sprachverarbeitung brilliert.
Phi-4: Was genau ist das?
Phi-4 ist ein kleines Sprachmodell (SLM), das von Microsoft entwickelt wurde und 14 Milliarden Parameter umfasst. Ursprünglich auf Azure AI Foundry verfügbar, ist es nun als Open Source auf Hugging Face unter der MIT-Lizenz zugänglich.
Dieses Modell zeichnet sich durch seine überlegene Leistung im Vergleich zu Google Gemini Pro 1.5 und OpenAI GPT-4 aus, insbesondere bei komplexen Aufgaben wie dem mathematischen Denken, während es weniger Rechenressourcen benötigt als große Sprachmodelle (LLM).
Entwickelt aus einer Mischung von synthesischen Daten, Webseiten aus der öffentlichen Domäne, wissenschaftlicher Literatur und Frage-Antwort-Datensätzen, wurde Phi-4 optimiert, um hochqualitative Ergebnisse mit fortgeschrittenem Denken zu liefern. Microsoft hat großen Wert auf die Robustheit und Sicherheit des Modells gelegt, indem es Techniken des supervisierten Feinabstimmens (SFT) und der direkten Präferenzoptimierung (DPO) verwendet hat, um eine präzise Befolgung von Anweisungen und starke Sicherheitsmaßnahmen zu gewährleisten.
Phi-4 ist besonders geeignet für Umgebungen mit Speicher- und Berechnungseinschränkungen sowie für Szenarien, die eine geringe Latenz erfordern. Insgesamt stellt es einen signifikanten Fortschritt in der Forschung zu Sprachmodellen dar und bietet eine leistungsfähige und ressourcensparende Alternative für Generative AI-Anwendungen.
Wie sind die Leistungen von Phi-4?
In einer Landschaft, in der die Leistung von Sprachmodellen oft mit ihrer Größe assoziiert wird, stellt Phi-4 diese Tendenz infrage, indem es beweist, dass ein kompaktes Modell mit weitaus größeren Architekturen konkurrieren kann. Dank starker Optimierungen erreicht es ein hohes Leistungsniveau in Verständnis und Denken, während es eine reduzierte Größe beibehält.
Während andere Modelle zig Milliarden aktive Parameter benötigen, um vergleichbare Ergebnisse zu liefern, positioniert sich Phi-4 als perfekte Balance zwischen Effizienz und Leistung. Diese strategische Positionierung erfüllt die wachsende Nachfrage nach zugänglicheren und ressourcenschonenderen KI-Lösungen, ohne bei der Qualität Kompromisse einzugehen.
Seine optimierte Architektur ermöglicht nicht nur eine schnellere Ausführung, sondern auch eine bessere Anpassungsfähigkeit an ressourcenbeschränkte Umgebungen wie eingebettete Anwendungen oder energieeffiziente Server. Indem es die Abhängigkeit von massiven Infrastrukturen reduziert, ebnet Phi-4 den Weg für die Demokratisierung der künstlichen Intelligenz, bei der hohe Leistungen und Energieeffizienz nicht mehr unvereinbar sind. Es verdeutlicht damit eine neue Generation von Modellen, die in der Lage sind, den industriellen und akademischen Bedürfnissen gerecht zu werden, und gleichzeitig agil und skalierbar zu bleiben.
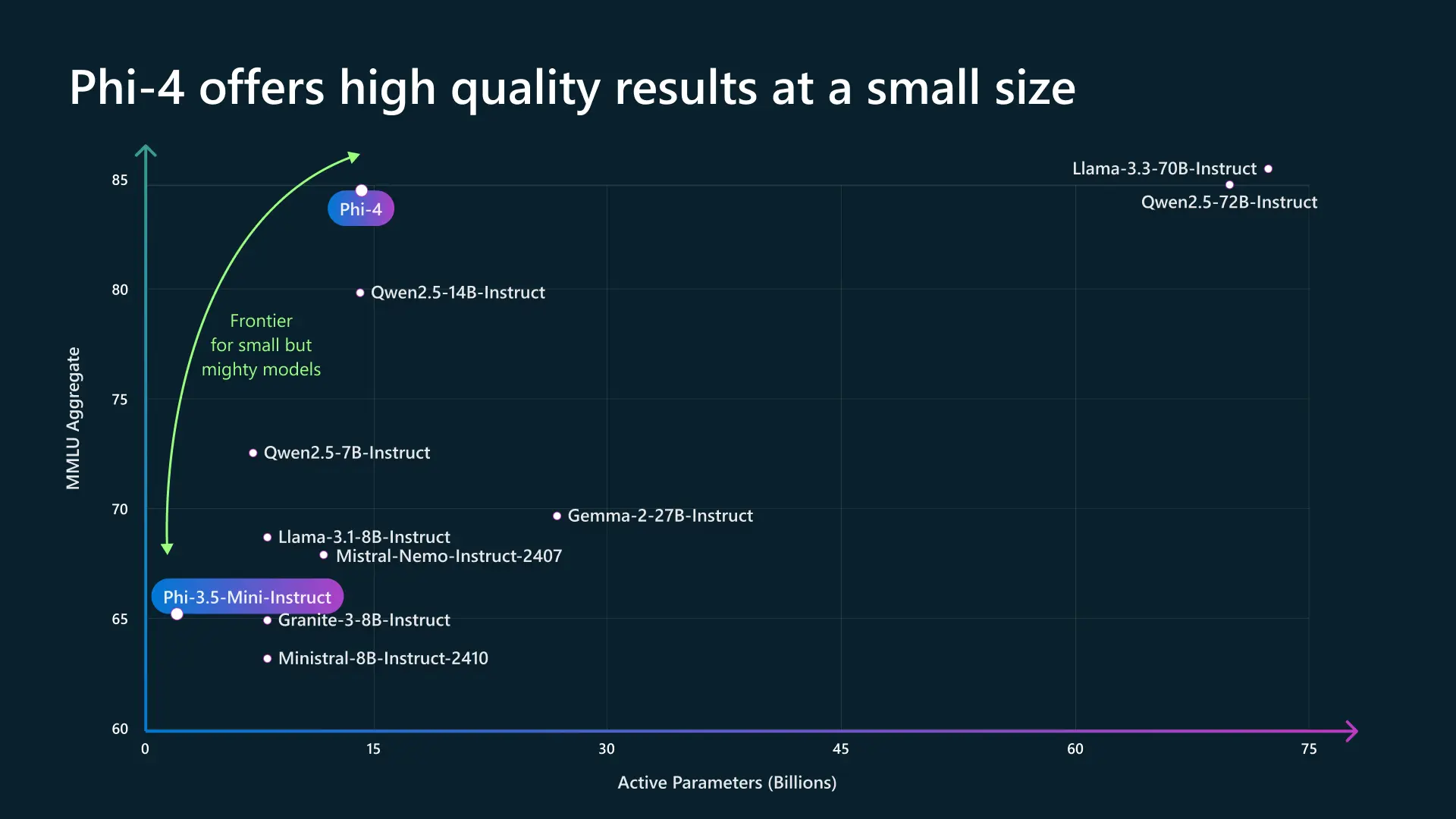
Was unterscheidet Phi-4 von anderen ähnlichen Modellen?
Phi-4 zeichnet sich durch seine exzellente Optimierung aus, indem es mit leicht größeren Modellen (wie Qwen2.5-14B oder Mixtral) konkurriert, während es leicht und leistungsstark bleibt. Sein MMLU-Score von 85 macht es zu einem sehr wettbewerbsfähigen Modell in der Kategorie der SLM (Small Language Models).
| Modell | Aktive Parameter (B) | MMLU-Score | Typ | Hauptvorteile | Nachteile |
| Phi-4 | ~10B | ~85 | Optimiertes, kompaktes Modell | Exzellente Leistung für seine Größe, effiziente Inferenz, gutes Denken | Weniger leistungsstark als größere Modelle wie GPT-4 oder Llama 3-70B |
| Mixtral (Mistral AI) | 12.9B (MoE, 2 aktive Experten) | ~82-83 | MoE (Mixture of Experts) | Sehr gutes Gleichgewicht zwischen Leistung und Effizienz, schnell und optimiert | Schwerfälliger in der Inferenz als Phi-4 |
| Qwen2.5-14B-Instruct | 14B | ~80 | Dichtes Modell | Gutes Verständnis der natürlichen Sprache, stark bei allgemeinen Aufgaben | Weniger optimiert als Phi-4, erfordert mehr Leistung |
| Llama 3.1-8B-Instruct | 8B | ~70 | Dichtes Modell | Leicht und effizient, guter Kompromiss für bestimmte Aufgaben | In der Gesamtleistung unterlegen zu Phi-4 |
| Mistral-8B-Instruct | 8B | ~68-70 | Dichtes Modell | Sehr effizient in der Inferenz, Open-Source | MMLU-Score niedriger als Phi-4, weniger vielseitig |
| Granite-3-8B-Instruct | 8B | ~65-67 | Dichtes Modell | Kompakt und schnell | Weniger leistungsfähig als Phi-4 in Denken und Analyse |
Während andere Modelle mehr Parameter benötigen, um ähnliche Leistungen zu erreichen, nutzt Phi-4 fortschrittliche Architektur und spezifische Optimierungen, um seine Effizienz zu maximieren. Dies ermöglicht es ihm, nicht nur Modelle vergleichbarer Größe zu übertreffen, sondern auch die Fähigkeiten größerer Modelle zu erreichen, während es gleichzeitig eine reduzierte Größe beibehält.
Seine schnelle Inferenz und das Gleichgewicht zwischen Leistungsfähigkeit und Ressourcenverbrauch machen es ideal für verschiedene Anwendungsfälle, insbesondere in professionellen und akademischen Umgebungen. Im Gegensatz zu schweren Modellen, die robuste Infrastrukturen für optimale Funktionsweise erfordern, positioniert sich Phi-4 als agile Lösung, die perfekt an Systeme mit eingeschränkter Rechenleistung angepasst ist. Durch die Integration fortschrittlicher Sprach- und Denkmechanismen sticht es als strategische Wahl für diejenigen heraus, die eine leistungsfähige, zugängliche und effiziente KI suchen.

Anwendungsfall: Phi-4 vor einem Problem der mathematischen Logik
Stellen wir uns einen Studenten vor, der sich auf eine Mathematikprüfung vorbereitet und mit einem komplexen Problem konfrontiert ist:
„Eine Schnecke klettert eine 10 Meter hohe Wand hinauf. Jeden Tag steigt sie 3 Meter hoch, rutscht aber nachts 2 Meter zurück. In wie vielen Tagen wird sie den Gipfel erreichen?“
Ein klassisches Modell könnte einfach eine Antwort durch mechanisches Rechnen geben:
- Tag 1: Sie steigt auf 3 m, rutscht auf 1 m zurück
- Tag 2: Sie steigt auf 4 m, rutscht auf 2 m zurück
- Usw.
Aber Phi-4 geht weiter, indem es strukturiertes Denken anwendet:
- Es identifiziert das wiederkehrende Muster: Jeden Tag macht die Schnecke tatsächlich einen Nettovorschritt von 1 Meter.
- Es optimiert das Denken: Nach 7 Tagen wird sie 7 Meter erreicht haben.
- Es entdeckt eine Ausnahme: Am achten Tag klettert sie direkt 3 Meter und erreicht den Gipfel, ohne zurückzurutschen.
- Es schließt also korrekt, dass die Schnecke 8 Tage benötigt, um oben anzukommen.
Diese Art von strukturiertem Denken zeigt, wie Phi-4 sich nicht auf automatische Antworten beschränkt: Es zerlegt ein Problem, identifiziert versteckte Fallen und gelangt auf logische und effiziente Weise zu einer Lösung.
Fazit
Abschließend verkörpert Phi-4 einen bedeutenden Fortschritt im Bereich der kleinen Sprachmodelle (SLM), indem es Leistung, Effizienz und Zugänglichkeit kombiniert. Dieses Modell positioniert Microsoft an der Spitze der Innovation in der generativen KI und bietet eine leistungsstarke und vielseitige Alternative für verschiedene Anwendungen, insbesondere in komplexem Denken und Sprachverarbeitung.







