Ableitung – Was war das nochmal gleich ?
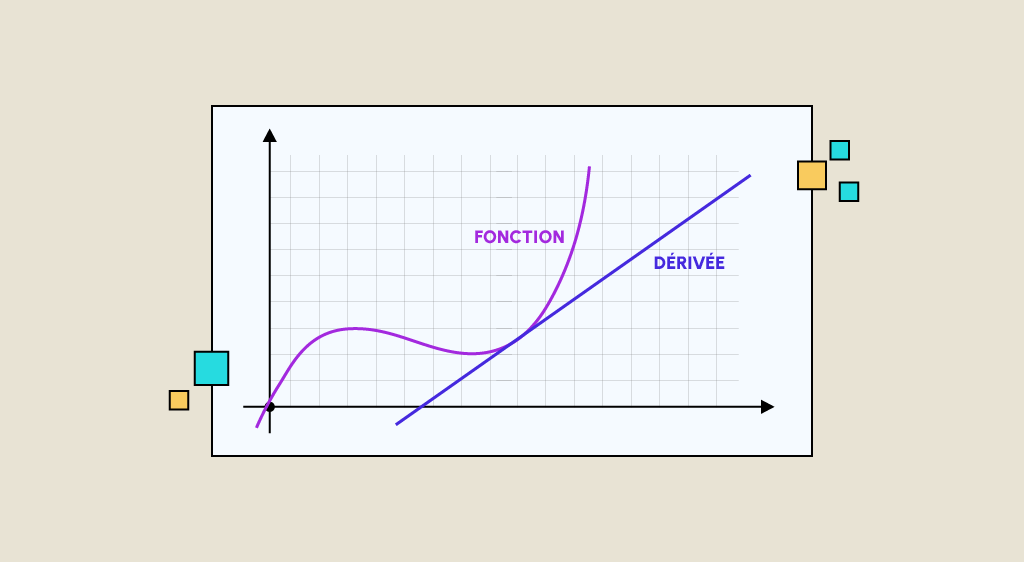
Der Begriff der Ableitung wird insbesondere in der DataScience sehr häufig verwendet, um Modelle für das maschinelle Lernen zu erlernen. Abgesehen von dem, was Du wahrscheinlich in der Schule gesehen hast, sind die Anwendungen dieses mathematischen Werkzeugs viel breiter gefächert, und wir werden am Ende dieses Artikels darauf zurückkommen. In diesem Artikel erfährst Du zunächst, […]
SpaCy: Die Open-Source Python-Bibliothek für NLP

spaCy Open-Source ist eine der wichtigsten Bibliotheken in der Programmiersprache Python für die Natürliche Sprachverarbeitung (NLP). Hier erfährst Du alles, was du wissen musst: Einführung, Funktionen, Vorteile, Schulungen… Natürliche Sprachverarbeitung oder NLP ist ein Zweig der künstlichen Intelligenz, der immer häufiger eingesetzt wird. Im Allgemeinen geht es dabei um alle Formen der Interaktion zwischen Computern […]
Datenvisualisierung mit Plotly

Übrigens, wusstest Du, dass Plotly, bevor es eine sehr bekannte Python-Bibliothek wurde, ein Unternehmen mit Sitz in Montreal ist, das von vier Personen gegründet wurde ? Ihr Ziel ist es, Werkzeuge zur Visualisierung sowie zur Analyse von Daten zu entwickeln. In diesem Artikel werden wir uns insbesondere mit der Python-Bibliothek plotly beschäftigen. Welche Tools bietet […]
FastAPI: Alles über den meistgenutzten Python-Framework

Ein Framework ist eine Sammlung von Modulen und Paketen, die zur Entwicklung von Software verwendet werden und den Entwicklern dabei helfen, dass sie sich nicht um Low-Level-Details kümmern müssen. Die drei am häufigsten verwendeten Frameworks für die Entwicklung von Webanwendungen in der Programmiersprache Python sind Django Flask und FastAPI. Jedes hat seine Vor- und Nachteile, […]
VAR-Modell Data Science: Pipeline – Geschäftsansatz bis zum Plotten der Ergebnisse

Das VAR-Modell: Eine umfassende Pipeline vom Geschäftsansatz bis zum Plotten der Ergebnisse Präsentation und Dankeschön Hallo zusammen und willkommen zu diesem Artikel, der darauf abzielt, mit Dir eine Pipeline für die Ausführung eines VAR-Modells unter Python zu entwickeln, von der Integration der Daten bis zum Plotten der Ergebnisse. Nach meiner Ausbildung in Management und Marktfinanzierung […]
Was ist Data Marketing? Antwort in 4 Anwendungen

Marketing nimmt einen zentralen Platz im Entscheidungsprozess eines Unternehmens ein. Die genaue Analyse der Bedürfnisse der Verbraucher und das Verständnis der Zielsegmente, die es beinhaltet, ermöglichen eine effektive und kohärente Strategie. Das weltweite Datenvolumen wird bis 2025 voraussichtlich um das 3,7-fache auf 175 Zettabytes ansteigen. Diese Datenexplosion ermöglicht eine Zunahme der gesammelten Kundendaten. Dies ist […]
Machine Learning & Clustering: Der CAH-Algorithmus
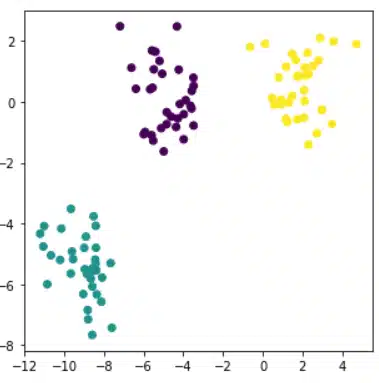
Clustering ist eine spezielle Disziplin des Machine Learning, deren Ziel es ist, Ihre Daten in homogene Gruppen mit gemeinsamen Merkmalen aufzuteilen. Dies ist z. B. ein beliebter Bereich im Marketing, wo oft versucht wird, Kundenstämme zu segmentieren, um bestimmte Verhaltensweisen zu erkennen. In einem früheren Artikel haben wir einen ersten Clustering-Algorithmus vorgestellt: den K-Mittelwert- oder […]
NLTK: Natürliche Sprachverarbeitung in Python

In diesem Artikel lernst du ein Dutzend nativer Python-Funktionen (buit-in) kennen, die dir mit Sicherheit sehr nützlich sein werden! Bist du ein Python-Anfänger? In unserem Kapitel findest Du alle Grundlagen, die Du brauchst. Zur Wiederholung: Native Funktionen sind Funktionen, die keine zusätzlichen Bibliotheken importieren müssen, um sie zu verwenden. NLTK ist eine Python-Bibliothek für natürliche Sprachverarbeitung […]
Computer Vision: Alles über diese Machine Learning App!

Von Snapchat-Filtern über selbstfahrende Autos bis hin zur Krebserkennung – Computer Vision ist heute überall um uns herum. Sie ist so effektiv wie vielfältig. Ziel dieses Artikels ist es, dir einen umfassenden Überblick über diese Technik des maschinellen Lernens zu geben, indem er Computer Vision genau definiert und seine Anwendungsbereiche aufzeigt. Was ist Computer Vision? […]
DataOps: Erklärung, Vorteile, Fortbildung

DataOps ist eine Methodik, die Data Science und DevOps für die Datenanalyse kombiniert. Erfahrehier alles Wichtige über DataOps! An der Schnittstelle zwischen DevOps und Data Science ist DataOps (Data Operations) eine aufstrebende Disziplin, die in den Unternehmen an Boden gewinnt. Sie besteht darin, Data-Ops-Teams mit den Rollen des Data Engineers und Data Scientists zu kombinieren. […]
Data Cleaning: Definition, Techniken, Bedeutung in der Data Science
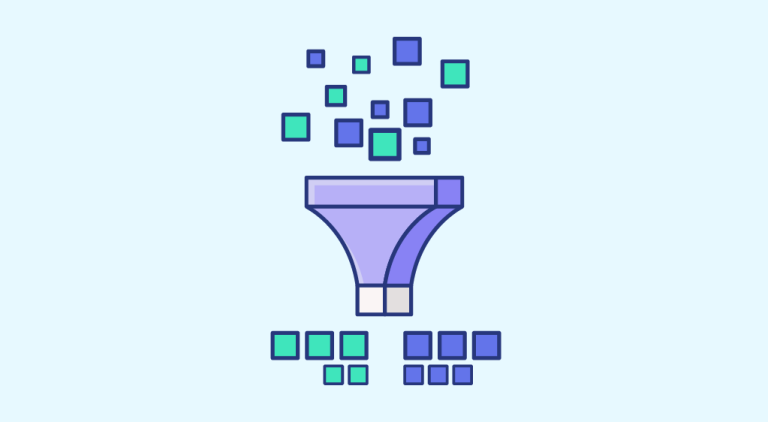
Data Cleaning oder Datenbereinigung ist ein unverzichtbarer Schritt in der Data Science und im Machine Learning. Es geht darum, Probleme in den Datensätzen zu lösen, damit sie später genutzt werden können. Definitionen, Techniken, Anwendungsbeispiele, Schulungen… Daten sind für Data Science, künstliche Intelligenz und Machine Learning unverzichtbar. Sie sind sozusagen der Treibstoff für diese Technologien. Daher […]
Word2vec : NLP & Word Embedding
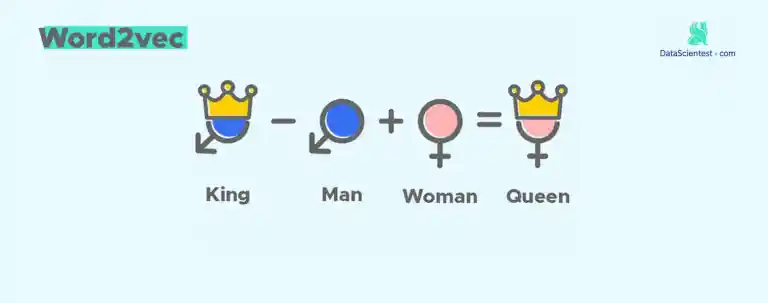
Word Embedding bezeichnet eine Reihe von Lernmethoden, die darauf abzielen, Wörter in einem Text durch Vektoren reeller Zahlen darzustellen. Heute präsentieren wir dir den dritten Teil unseres NLP-Dossiers. Hast du die ersten Episoden verpasst? Keine Sorge, hier sind sie: Einführung in NLP Word embedding – Word2vec Definition von word embedding Embedding […]
