
Die optische Zeichenerkennung (OCR, Optical Character Recognition), auch Ocerisation genannt, umfasst alle Methoden, mit denen Textdateien aus Bildern mit handgeschriebenem Text erzeugt werden können. Mit dem Aufkommen der Digitaltechnik und der Automatisierung ist das Scannen zu einem unverzichtbaren Werkzeug geworden, da Bilder, die Text enthalten, nicht von einem Computer verarbeitet werden können.
1. Geschichte der Optical Character Recognition
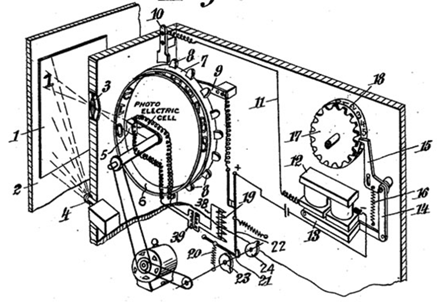
Die erste Version einer Maschine, die Zeichen in einem handgeschriebenen Dokument erkennen konnte, wurde 1929 von Gustav Tauschek, einem deutschen Ingenieur, entwickelt.
Das Prinzip war wie folgt: Ein Dokument, das einen handgeschriebenen Text enthielt, wurde vor dem Fenster der Maschine positioniert.
Um das richtige Zeichen zu erkennen, drehte sich ein Rad mit Löchern in der Form von Buchstaben, bis das Bild des Zeichens und das Loch mithilfe eines Fotodetektors perfekt übereinstimmten. Sobald das Zeichen erkannt war, wurde es auf ein Blatt Papier geschrieben.
2. Nutzung von Deep Learning für die Ocerisierung (Optical Character Recognition)
Man kann leicht feststellen, dass das Scannen mit mechanischen Maschinen, so gut sie auch sein mögen, sehr kostspielig und ziemlich zeitaufwendig sein kann.
Unternehmen, die ihre Digitalisierungspipeline automatisieren wollen, benötigen ein schnelles und effizientes Werkzeug zur Handschrifterkennung. Dank der Entwicklung von Deep Learning, insbesondere im Bereich der Bildverarbeitung, gibt es heute Algorithmen, die OCR-Probleme lösen können. Das Optical Character Recognition-Modell besteht aus zwei Schritten: der Texterkennung und der Texterfassung.
Der erste ist der Prozess, der die Textbereiche in einem Dokument erkennt und kann eine wirklich komplizierte Aufgabe sein, da die Dokumente sehr unterschiedlich strukturiert sein können. Textbereiche befinden sich z. B. in einem Roman und einer Zeitung an unterschiedlichen Stellen.
Die zweite Möglichkeit besteht darin, Text für einen Bereich des Dokuments zu erkennen, der diesen enthält.
3. Texterkennung mithilfe von Deep Learning
Es gibt verschiedene Methoden, um Text innerhalb eines Dokuments zu erkennen. Einige von ihnen basieren auf Modellen zur Objekterkennung (Single Shot Box Detection, Faster-RCNN), die verwendet werden, um Gesichter, Autos usw. in einem Bild zu erkennen.
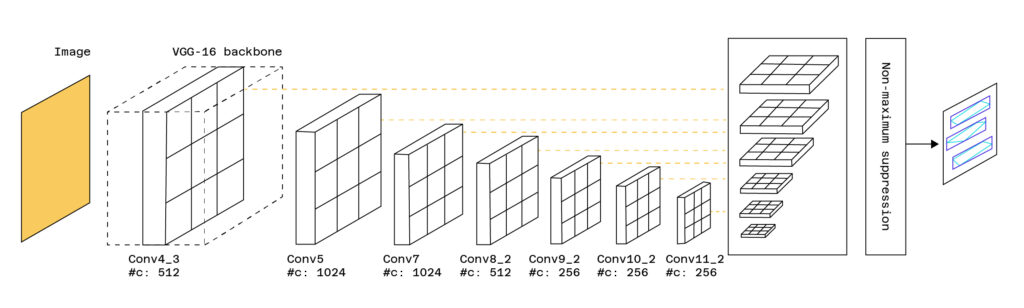
Solche Modelle geben eine Bounding Box zurück, die nichts anderes ist als ein Rahmen, der das zu erkennende Objekt umgibt. Um Text zu erkennen, werden diese Modelle modifiziert und angepasst. Ein Beispiel ist das TextBoxes-Modell, das auf dem SSD-Modell (Single Short Detector) aufbaut, aber Bounding Boxes hinzufügt, die spezifischer für die Erkennung von Text sind.
Die Vorlage gibt die Bereiche des Bildes zurück, die Text enthalten.
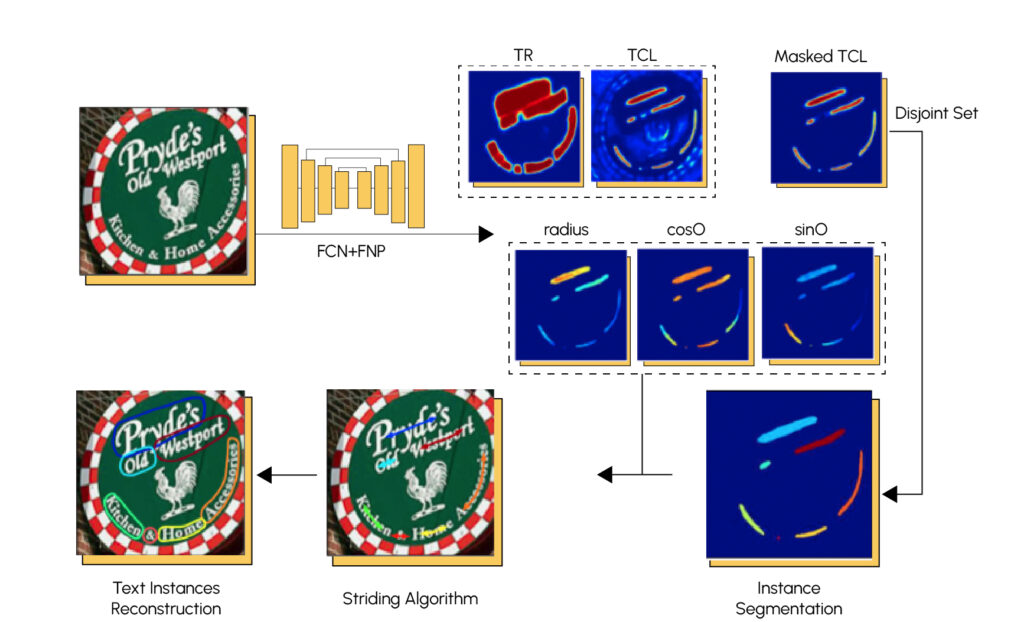
Es gibt auch andere Erkennungsmethoden, die auf Segmentierung basieren. Die Segmentierung ist ein Verfahren, mit dem ein Bild in mehrere Bereiche, sogenannte Klassen, mit ähnlichen Elementen aufgeteilt wird. Hier ein Beispiel:

Für die Segmentierung von Text werden häufig Faltungsneuronennetze (FCN) sowie pyramidenförmige Neuronennetze (FPN) verwendet. Hier ist die Architektur eines sehr leistungsfähigen Modells namens TextSnake.
4. Texterkennung mithilfe von Deep Learning
Wir haben gerade den ersten Schritt eines Scannermodells gesehen, nämlich die Erkennung von Bereichen im Dokument, die Text enthalten. Sobald dies geschehen ist, müssen die Zeichen, die diese Bereiche bilden, erkannt werden, um daraus Wörter abzuleiten und das handgeschriebene Dokument in ein verwertbares Textformat zu übersetzen.
Die am häufigsten verwendeten Machine-Learning-Modelle zur Lösung von Texterkennungsproblemen sind rekurrente neuronale Netze. Ihr Vorteil ist, dass die verborgenen Schichten, aus denen sie bestehen, ein gemeinsames Speicherband teilen, was zur Folge hat, dass die Vorhersage auf der Grundlage früherer Vorhersagen beeinflusst wird.
Wenn du mehr darüber erfahren möchtest, wie sie funktionieren, findest du einen vollständigen Artikel über rekursive neuronale Netze in unserem Blog. Die am häufigsten verwendeten Schichten für Modelle mit rekursiven neuronalen Netzen sind LSTMs und GRUs. Wir fügen diesen rekursiven Schichten Faltungsschichten hinzu.
Mithilfe der Faltung können relevante und lokale Merkmale aus Bildern mit Text extrahiert werden, und die rekursiven Schichten ermöglichen die Zuweisung von Labels, die den im Bild vorhandenen Zeichen entsprechen.
Jedem durch die Faltung erzeugten Merkmal wird ein Wahrscheinlichkeitsvektor der Zugehörigkeit zu jedem Label zugeordnet.
Die Texterkennung kann in folgendem Schema zusammengefasst werden:
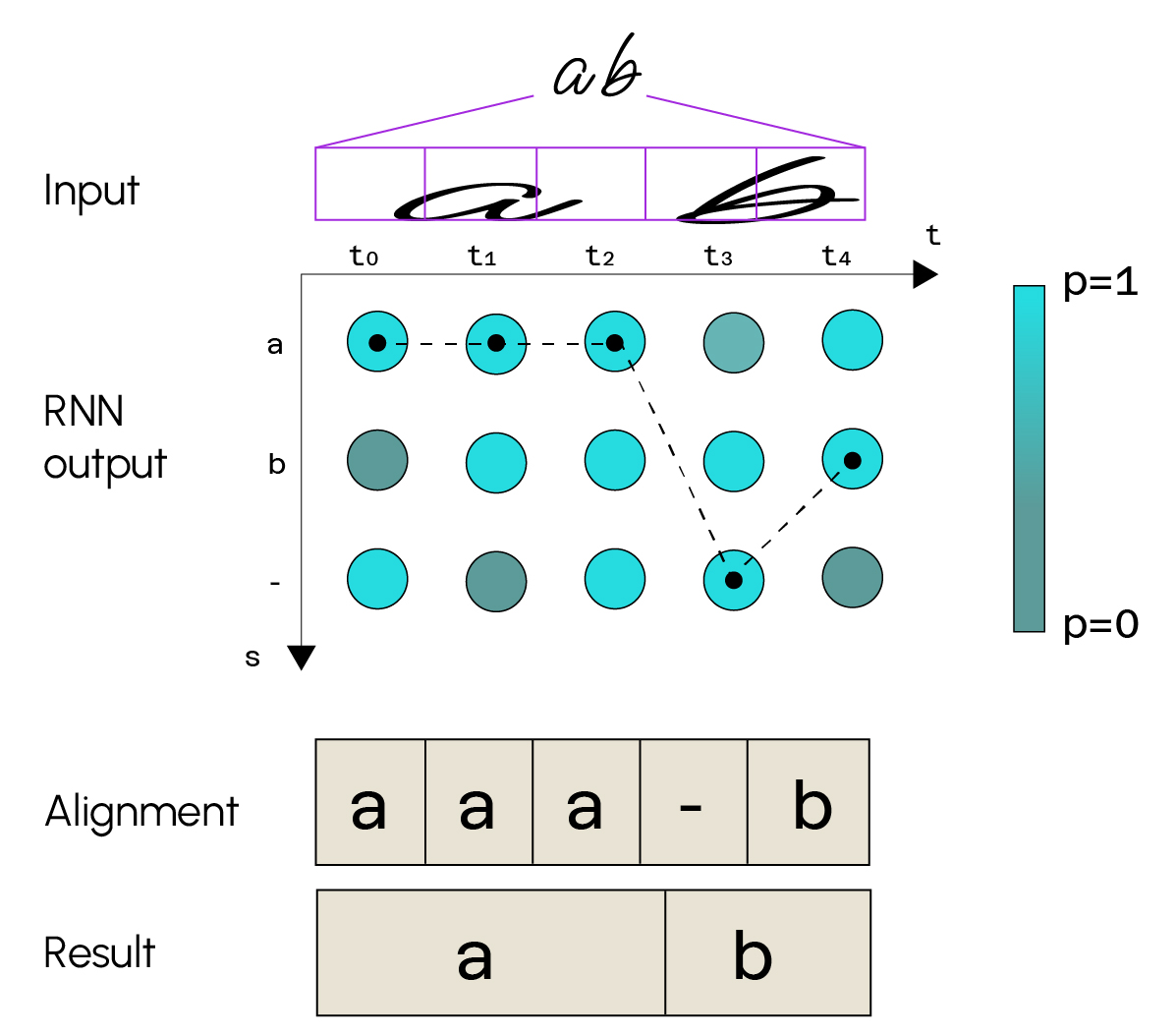
Man darf nicht vergessen, dass es einen vorgeschalteten Texterkennungsteil geben muss, damit der Erkennungsteil richtig funktioniert.
In diesem Beispiel siehst du, dass das als Eingabe gegebene Bild den Text „a b“ darstellt. Der Teil
Faltung wird das Bild in eine Feature Map zerlegen, die auch als Merkmalskarte bezeichnet wird. Man sieht, dass das Bild hier in 5 Sequenzen zerlegt wurde. Die rekursiven Schichten werden dann jeder Sequenz eine Klassenwahrscheinlichkeit zuordnen. Es gibt so viele Klassen, wie es mögliche Zeichen gibt (Buchstaben des Alphabets, Sonderzeichen, …). Für jede Sequenz wählen wir die Klasse, die die Wahrscheinlichkeit maximiert, erhalten eine Folge von Zeichen und können dann unseren endgültigen Text daraus ableiten.
Allerdings kann man mit diesem Modell nicht überprüfen, ob das Wort oder der Satz, der als Ausgabe zurückgegeben wird, frei von Rechtschreibfehlern ist, da man Zeichen für Zeichen vorhersagt, ohne sich darum zu kümmern. Es gibt andere Modelle, die ein System zur Rechtschreibkorrektur implementieren. Dieser Ansatz wird Sprachmodell genannt und kann die Genauigkeit unseres Modells verbessern.
5. Fazit
Wir haben gerade ein Deep-Learning-Modell kennengelernt, mit dem das Problem der Ocerisation durch Optical Character Recognition gelöst werden kann.
Deep Learning hat diesen Bereich geradezu revolutioniert, da es im Gegensatz zu den Modellen, die zuvor entwickelt wurden, sehr genaue Vorhersagen liefert. Es fällt auf, dass das Modell Techniken verwendet, die normalerweise in anderen Bereichen eingesetzt werden, wie z. B. die Erkennung von Objekten in einem Bild oder Natural Language Processing, und dass diese Techniken sehr gut für die Ozonisierung funktionieren.
Wenn dir dieser Artikel gefallen hat und du weitere Methoden des Deep Learning kennenlernen möchtest, lade ich dich ein, an unserem Deep-Learning-Expertenkurs teilzunehmen.
Auch interessant:







