
Der K-nearest neighbors (KNN) Algorithmus, wörtlich der K-nächste-Nachbarn-Algorithmus, ist ein Machine-Learning-Algorithmus. Er gehört zur Klasse der einfachen und leicht zu implementierenden überwachten Lernalgorithmen und kann zur Lösung von Klassifikations- und Regressionsproblemen verwendet werden. In diesem Artikel werden wir die Definition dieses Algorithmus, seine Funktionsweise sowie eine direkte Anwendung in der Programmierung erläutern.
KNN Definition
Bevor wir uns auf den KNN-Algorithmus konzentrieren, wiederholen wir zunächst die Grundlagen. Was ist nochmal ein überwachter Lernalgorithmus?
Beim überwachten Lernen erhält ein Algorithmus einen Datensatz, der mit entsprechenden Ausgangswerten beschriftet ist, mit dem er trainieren und ein Vorhersagemodell definieren kann. Dieser Algorithmus kann dann auf neue Daten angewendet werden, um die entsprechenden Ausgangswerte vorherzusagen.
Hier eine vereinfachte Illustration:
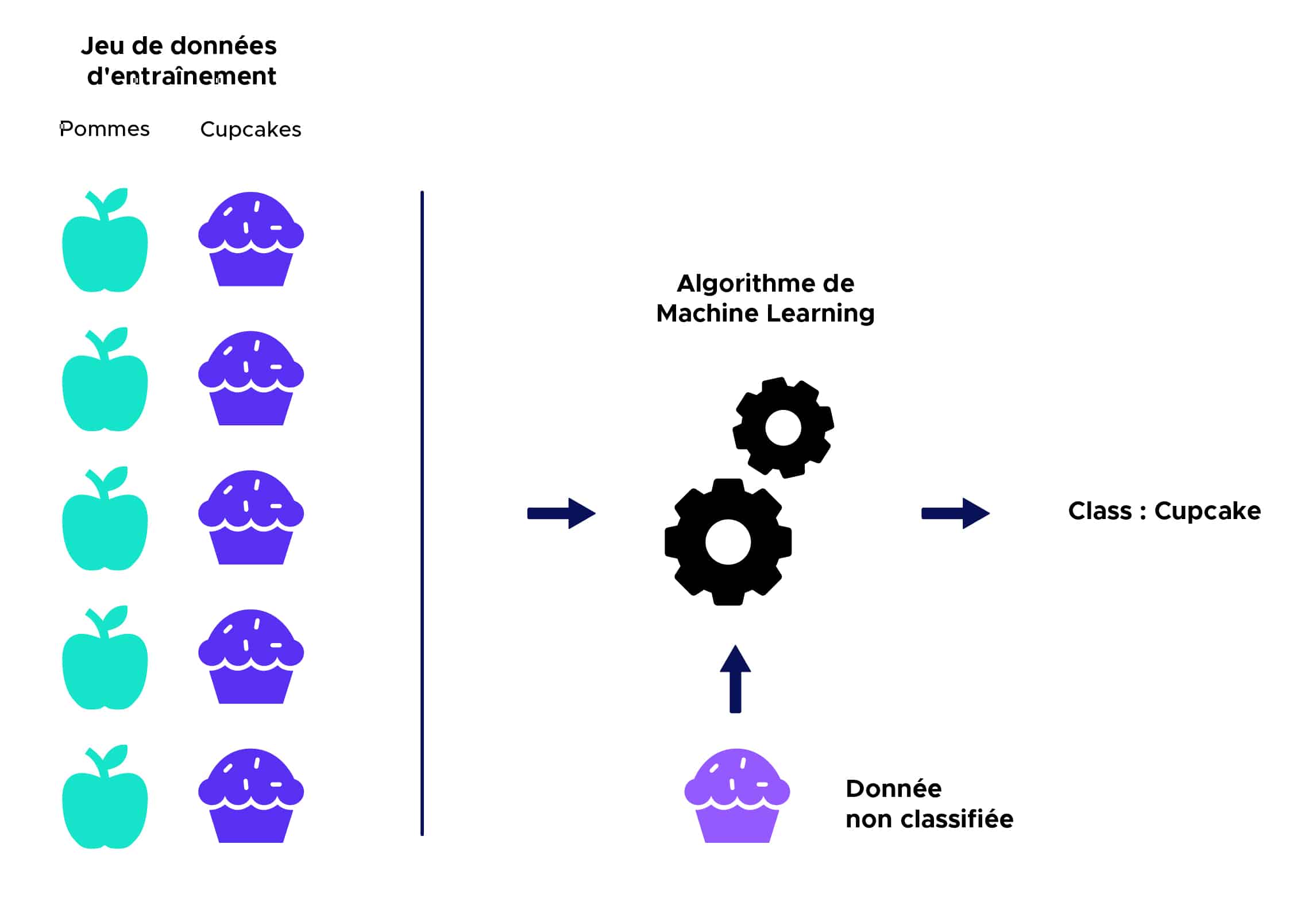
Die Intuition hinter dem KNN-Algorithmus ist eine der einfachsten aller Algorithmen des Supervised Machine Learning:
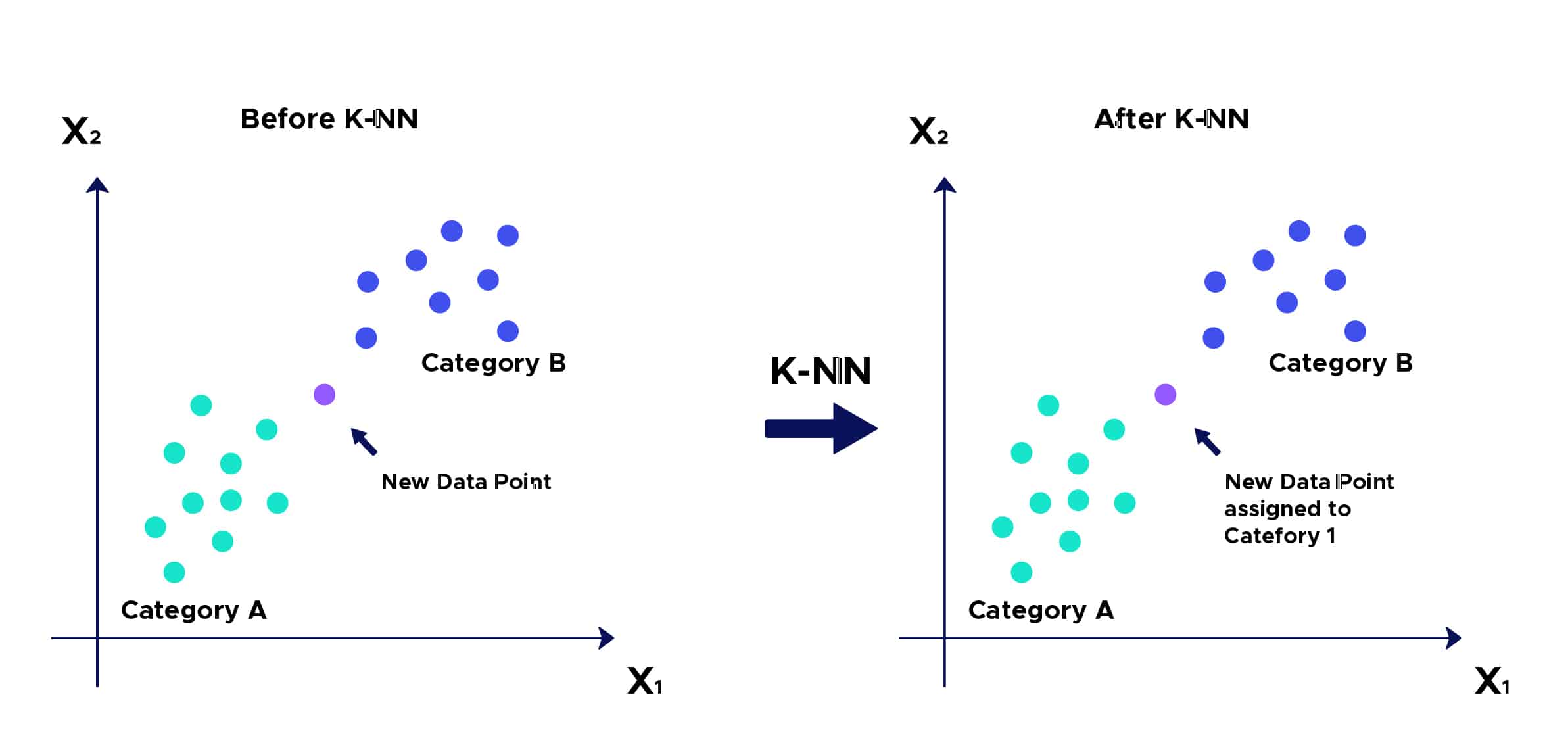
- 1. Schritt: Wähle die Anzahl K der Nachbarn aus.
- 2. Schritt: Berechne die Distanz
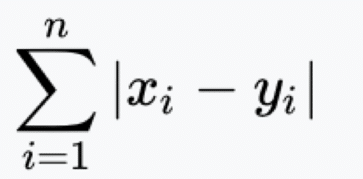
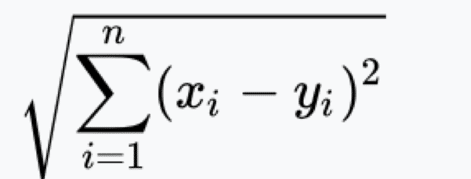
Vom nicht klassifizierten Punkt zu den anderen Punkten.
- 3. Schritt: Nimm die K nächsten Nachbarn gemäß der berechneten Distanz.
- 4. Schritt: Zähle unter diesen K Nachbarn die Anzahl der Punkte, die zu jeder Kategorie gehören.
- 5. Schritt: Ordne den neuen Punkt der Kategorie zu, die unter diesen K Nachbarn am häufigsten vertreten ist.
- 6. Schritt: Unser Modell ist fertig:
KNN: Ein Anwendungsbeispiel
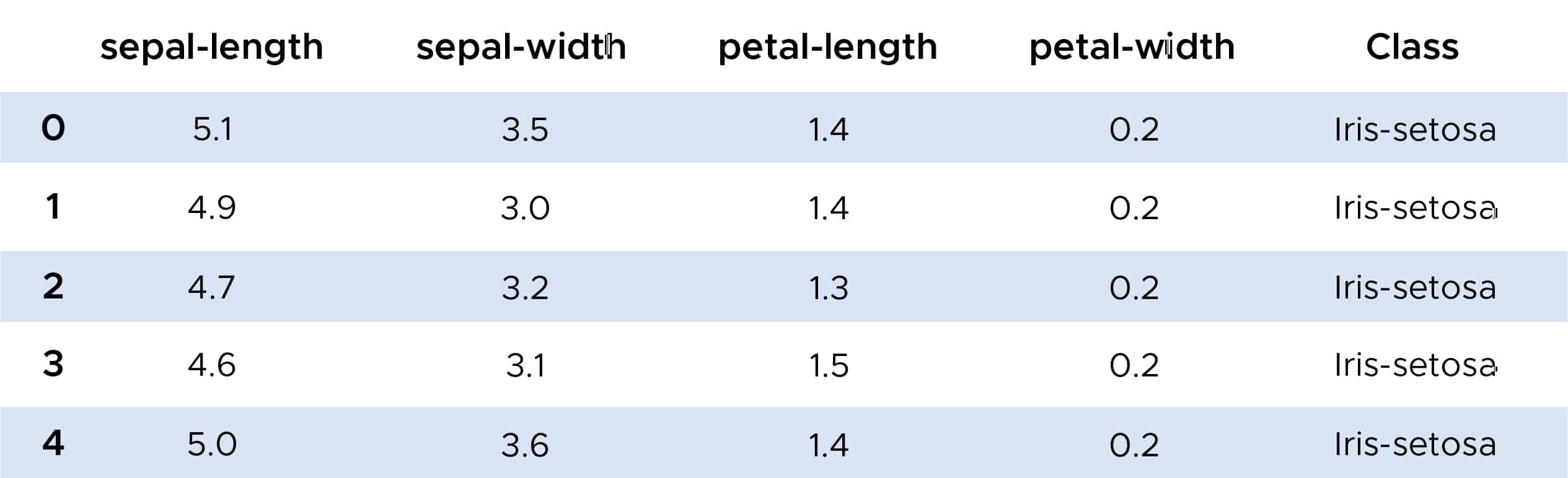
Nun ein Beispiel für die Verwendung des Algorithmus der K nächsten Nachbarn. Mit der Bibliothek Scikit-Learn können wir die Funktion KKNeighborsClassifier importieren, die wir auf den IRIS-Datensatz anwenden werden.
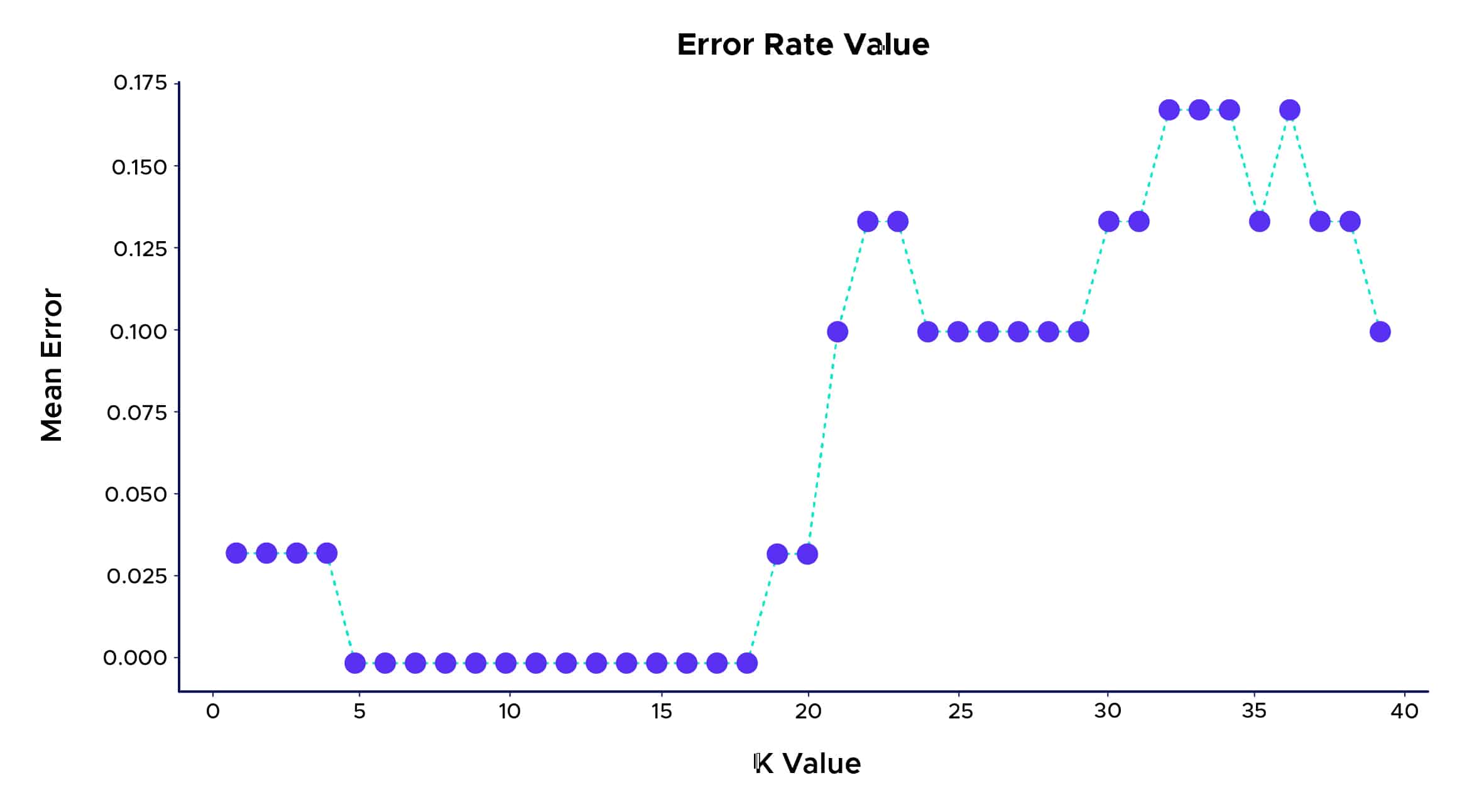
So können wir sehen, dass die beste Vorhersagequote bei K zwischen 5 und 18 liegt. Oberhalb dieses Wertes können wir ein Phänomen namens „Overfitting“ beobachten, das auftritt, wenn die zur Erstellung eines Modells verwendeten Lerndaten die Daten sehr gut oder sogar „zu gut“ erklären, aber keine nützlichen Vorhersagen für neue Daten machen können.
Einige Anwendungen :
- Es kann in Technologien wie OCR (Optical Character Recognizer, dt. optische Zeichenerkennung) eingesetzt werden, die versucht, Handschriften, Bilder und sogar Videos zu erkennen.
- Es kann im Bereich der Kreditratings eingesetzt werden. Er versucht, die Merkmale einer Person mit der vorhandenen Gruppe von Personen abzugleichen, um ihr die Kreditwürdigkeit zuzuordnen. Er erhält die gleiche Bewertung wie die Personen, die seinen Merkmalen entsprechen.
- Es wird verwendet, um vorherzusagen, ob die Bank einer Einzelperson einen Kredit gewähren sollte. Sie wird versuchen zu beurteilen, ob die gegebene Person den Kriterien der Personen entspricht, die zuvor ausgefallen waren, oder ob sie ihren Kredit nicht ausfallen lassen wird.
Vorteile:
- Der Algorithmus ist einfach und leicht zu implementieren.
- Es ist nicht notwendig, ein Modell zu erstellen, mehrere Parameter einzustellen oder zusätzliche Annahmen zu treffen.
- Der Algorithmus ist vielseitig einsetzbar. Er kann sowohl für Klassifizierung als auch für Regression verwendet werden.
Nachteile:
- Der Algorithmus wird mit zunehmender Anzahl von Beobachtungen und unabhängigen Variablen wesentlich langsamer.
Da er einer der einfachsten Machine-Learning-Algorithmen ist, ist er darauf ausgelegt lernbasierte, intuitive und intelligente Systeme zu entwickeln, die kleine Entscheidungen ganz allein durchführen und treffen könnten.
Lernen und Entwickeln werden somit noch einfacher und der Algorithmus hilft fast allen Arten von Branchen, die intelligente Systeme, Lösungen oder Dienstleistungen nutzen könnten.
Es gibt viele andere überwachte und nicht überwachte Clustering-Algorithmen, die je nach Situation mehr oder weniger geeignet sind, wie z.B. K-Means, Bottom-up-Verfahren , DBSCAN (density-based spatial clustering of applications with noise)… die Du in unserem Blog finden kannst.







