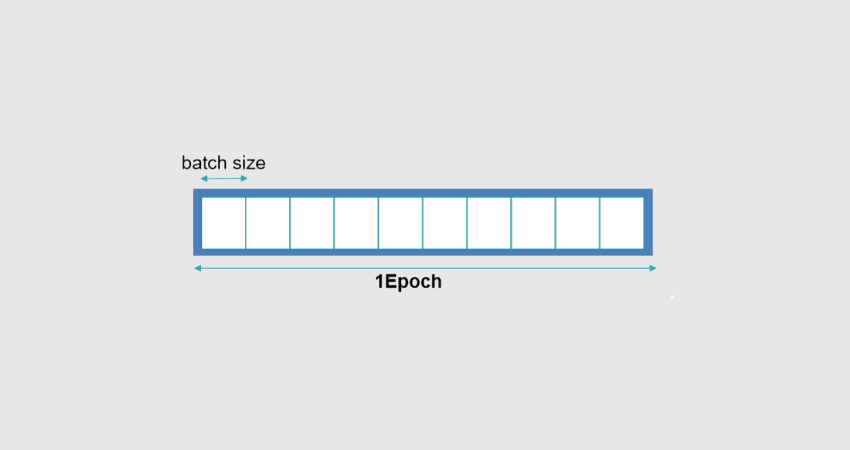
Eine "Epoch" oder "Epoche" beim Machine Learning bezeichnet einen vollständigen Durchlauf des Trainingsdatensatzes durch den Algorithmus. Hier erfährst du alles, was du über diesen wichtigen Begriff des maschinellen Lernens wissen musst.
Im Bereich der künstlichen Intelligenz besteht Machine Learning darin, ein Modell mithilfe eines Algorithmus aus Daten lernen und trainieren zu lassen. Diese Methode ist der Art und Weise nachempfunden, wie das menschliche Gehirn lernt, und basiert daher auf künstlichen neuronalen Netzen.
Während ein Mensch jedoch mehrere Jahre braucht, um zu lernen, kann ein Modell dank Techniken wie dem parallelen Training in nur wenigen Stunden so lange trainieren, wie es Jahrzehnte dauert.
Jedes Mal, wenn der Trainingsdatensatz den Algorithmus durchläuft, sagt man, dass er eine „Epoche“ oder „epoch“ auf Englisch abgeschlossen hat. Dies ist ein Hyperparameter, der den Trainingsprozess des Machine-Learning-Modells bestimmt.
Was ist ein Epoch ?
Ein vollständiger Zyklus des Trainingsdatensatzes wird im Bereich des Machine Learning als „Epoche“ bezeichnet. Sie spiegelt die Anzahl der Durchläufe des Algorithmus während der Trainingsphase wider.
Eine Epoche kann als die Anzahl der Durchläufe eines Trainingsdatensatzes durch einen Algorithmus definiert werden. Ein Durchlauf entspricht einem Hin- und Rücklauf.
Die Anzahl der Epochs kann mehrere Tausend betragen, da der Vorgang unendlich oft wiederholt wird, bis die Fehlerrate des Modells ausreichend reduziert ist.
Eine Epoche besteht aus einer Aggregation von „Batches“ oder „Batches“ von Daten und Iterationen. Datensätze werden in der Regel in Batches unterteilt, vor allem wenn die Datenmenge sehr groß ist.

Was ist eine Iteration ?
Im Bereich des Machine Learning gibt eine Iteration an, wie oft die Parameter eines Algorithmus geändert werden. Die spezifischen Implikationen hängen vom Kontext ab.
Im Allgemeinen umfasst eine Iteration beim Trainieren eines neuronalen Netzes das „Batch Processing“ oder die Stapelverarbeitung des Datasets, die Berechnung der Kostenfunktion, die Änderung und die Rückverbreitung aller Gewichtsfaktoren.
Iteration und Epoche werden oft fälschlicherweise miteinander verwechselt. In Wirklichkeit beinhaltet eine Iteration die Verarbeitung eines Batches, während eine Epoche die Verarbeitung aller Daten des Datasets bezeichnet.
Wenn eine Iteration beispielsweise 10 Bilder eines Satzes von 1000 Bildern mit einer Batchgröße von 10 verarbeitet, werden 100 Iterationen benötigt, um eine Epoche abzuschließen.
Was ist ein Batch ?
Die Trainingsdaten werden in mehrere kleine „Stapel“ oder „Batches“ auf Englisch zerlegt. Dadurch sollen Probleme vermieden werden, die durch mangelnden Speicherplatz entstehen.
Die Batches können leicht dazu verwendet werden, das Machine-Learning-Modell zu füttern, um es zu trainieren. Dieser Prozess der Zerlegung des Datasets wird als „Batch“ bezeichnet.
Eine Epoch kann aus einem oder mehreren Batches bestehen. Die Anzahl der Trainingsproben, die in einer Iteration verwendet werden, ist die „Batchgröße“ oder „batch size“. Es werden drei Möglichkeiten unterschieden.
Im „Batch Mode“ sind die Werte für Iteration und Epoche gleich, da die Batchgröße dem kompletten Dataset entspricht. Eine Iteration entspricht also einer Epoche.
Im „Mini-Batch-Modus“ ist die Größe des gesamten Datensatzes kleiner als die Größe des Batches. Folglich ist ein einzelner Batch größer als der Trainingsdatensatz.
Im „stochastischen Modus“ schließlich ist die Größe des Batches einmalig. Folglich werden der Gradient und die Parameter des neuronalen Netzes bei jeder Probe geändert.
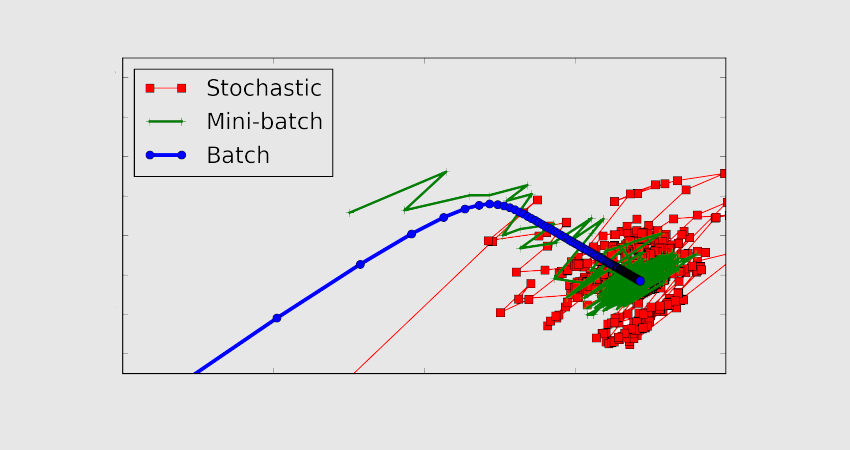
Was ist der stochastische Gradientenalgorithmus?
Der Stochastic Gradient Descent Algorithmus (SGD) ist ein Optimierungsalgorithmus. Er wird von neuronalen Netzen im Bereich des Deep Learning verwendet, um Machine-Learning-Algorithmen zu trainieren.
Die Aufgabe dieses Algorithmus ist es, einen Satz interner Modellparameter zu identifizieren, der andere Leistungsmaße wie den quadratischen Fehler oder den Logarithmusverlust übersteigt.
Die Optimierung kann als ein Suchprozess beschrieben werden, der das Lernen mit einbezieht. Der Optimierungsalgorithmus wird als gradueller Abstieg bezeichnet und basiert auf der Berechnung eines Fehlergradienten oder einer Fehlersteigung, die in Richtung des minimalen Fehlerniveaus abgesenkt werden muss.
Dieser Algorithmus ermöglicht es, den Suchprozess mehrmals durchzuführen. Ziel ist es, die Parameter des Modells in jedem Schritt zu verbessern. Es handelt sich also um einen iterativen Algorithmus.
In jedem Schritt werden Vorhersagen anhand bestimmter Stichproben unter Verwendung des internen Parametersatzes gemacht. Die Vorhersagen werden dann mit den erwarteten Ergebnissen verglichen, um die Fehlerrate zu berechnen. Anschließend werden die internen Parameter aktualisiert.
Die verschiedenen Algorithmen verwenden unterschiedliche Aktualisierungsverfahren. Bei künstlichen neuronalen Netzen verwendet der Algorithmus die Methode der Rückwärtspropagation.
Batchgröße vs. Epoch: Was ist der Unterschied?
Die Batchgröße ist die Anzahl der verarbeiteten Proben, bevor sich das Modell ändert. Die Anzahl der Epochs ist die Menge der vollständigen Iterationen des Trainingsdatensatzes.
Ein Batch muss eine Mindestgröße von eins haben und eine Maximalgröße, die kleiner oder gleich der Anzahl der Stichproben des Trainingsdatensatzes ist.
Für die Anzahl der Epochen kann ein ganzzahliger Wert zwischen eins und unendlich gewählt werden. Die Verarbeitung kann unbegrenzt ausgeführt werden und sogar durch andere Kriterien als eine vorbestimmte Anzahl von Epochen gestoppt werden. Das Kriterium kann zum Beispiel die Fehlerrate des Modells sein.
Die Batchgröße und die Anzahl der Epochen sind Hyperparameter des Lernalgorithmus und müssen dem Algorithmus mitgeteilt werden. Diese Parameter müssen konfiguriert werden, indem viele Werte getestet werden, um herauszufinden, welcher Wert optimal ist.
Wie wählt man die Anzahl der Epochs?
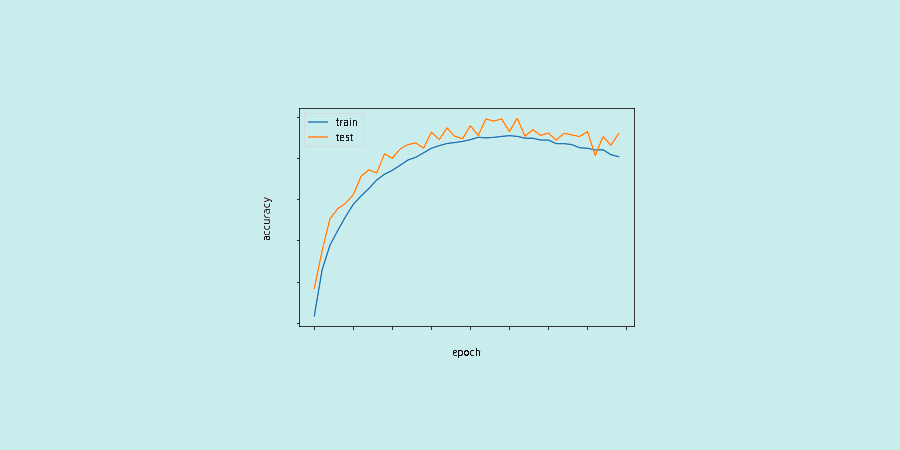
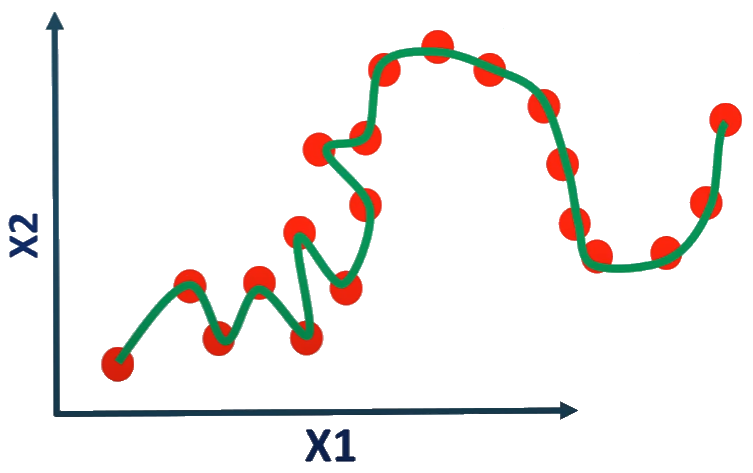
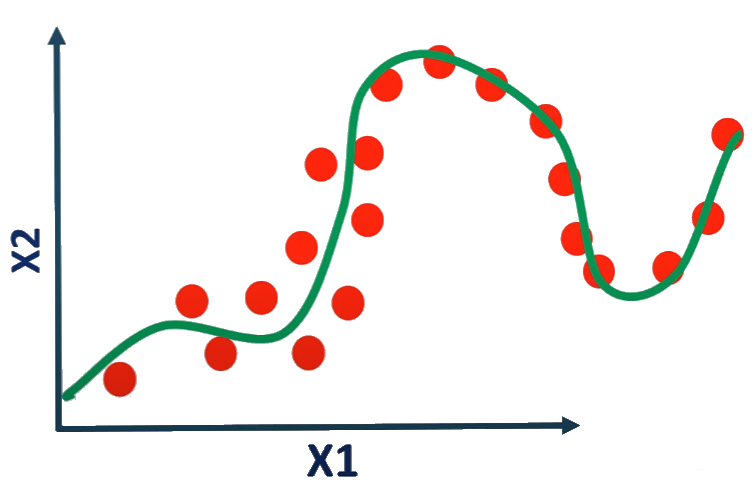
Nach jeder Iteration des neuronalen Netzes werden die Gewichte geändert. Die Kurve entwickelt sich von Underfitting über Overfitting bis hin zur idealen Anpassung. Die Anzahl der Epochen ist ein Hyperparameter, der vor Beginn des Trainings entschieden werden muss.
Eine höhere Anzahl an Epochen führt nicht unbedingt zu besseren Ergebnissen. Im Allgemeinen ist eine Anzahl von 11 Epochen ideal für das Training auf den meisten Datasets.
Die Optimierung des Lernens basiert auf dem iterativen Prozess des allmählichen Abstiegs. Aus diesem Grund reicht eine einzige Epoche nicht aus, um die Gewichte optimal zu verändern. Im Gegenteil, eine Epoche zu viel kann dazu führen, dass das Modell overfitting…
Warum ist das bei Machine Learning so wichtig?
Epoch ist einer der entscheidenden Begriffe im Machine Learning. Sie hilft dabei, das Modell zu identifizieren, das die Daten so genau wie möglich repräsentiert.
Das neuronale Netz muss auf der Grundlage der dem Algorithmus angegebenen Anzahl von Epochen und der Batchgröße trainiert werden.
Dieser Hyperparameter bestimmt also den gesamten Ablauf des Prozesses.
Wie auch immer, es gibt kein Geheimrezept oder eine Zauberformel, um den idealen Wert für jeden Parameter zu definieren. Data Analysts haben keine andere Wahl, als eine Vielzahl von Werten zu testen, bevor sie denjenigen auswählen, der für die Lösung des spezifischen Problems am besten geeignet ist.
Eine Methode zur Bestimmung der geeigneten Anzahl von Epochen besteht darin, die Lernleistung zu überwachen, indem man diese Anzahl mit der Fehlerrate des Modells vergleicht. Die Lernkurve ist sehr nützlich, um zu überprüfen, ob ein Modell overfitting, underfitting oder angemessen trainiert ist.
Wie kann ich eine Machine Learning-Schulung absolvieren?
Zusammengefasst ist Epoch ein Begriff, der verwendet wird, um die Häufigkeit zu beschreiben, mit der Trainingsdaten den Algorithmus durchlaufen. Es ist eines der wichtigsten Konzepte des Machine Learning.
Um Fachwissen in diesem Bereich zu erwerben, kannst du dich für DataScientest entscheiden.
Unsere Kurse Data Scientist, Data Analyst und Machine Learning Engineer enthalten alle ein Modul, das dem Machine Learning gewidmet ist.
Hier lernst du überwachtes und nicht überwachtes Lernen, Klassifizierung, Regression, Clustering mit Scikit-Learn, Text Mining, Zeitreihen und Dimensionsreduktion kennen.
In den anderen Modulen dieser Studiengänge kannst du dir alle Fähigkeiten aneignen, die du brauchst, um ein Profi im Bereich Data Science zu werden. Je nachdem, welchen Kurs du wählst, kannst du als Data Analyst, Data Scientist oder Machine Learning Engineer arbeiten.
Alle unsere Kurse werden vollständig im Fernunterricht über das Internet absolviert und können durch Weiterbildung oder BootCamps ergänzt werden. Unser innovativer Blended-Learning-Ansatz kombiniert Fernunterricht auf einer gecoachten Plattform und Masterclasses.
Am Ende des Kurses erhalten die Lernenden ein Zertifikat von Mines ParisTech PSL Executive Education und
Du kannst auch Zusatzprüfungen ablegen, um die Zertifizierungen Microsoft Certified Power Platform Fundamentals oder AWS Cloud Practitioner zu erhalten.
Was die Finanzierung angeht, so ist unsere staatlich anerkannte Organisation im Rahmen des Bildungsgutscheins förderfähig. Warte nicht länger und entdecke DataScientest!







