


GAN Machine Learning: Was haben diese drei Personen gemeinsam? Keine von ihnen existiert im wirklichen Leben und jedes dieser Fotos wurde von dieser Website generiert. Aber wie kann diese Seite es schaffen, so fotorealistische und unterschiedliche Personen zu generieren?
Dank des StyleGAN2-Algorithmus, der von einem Forscherteam von NVIDIA entwickelt wurde! Dieser noch sehr neue Algorithmus (Februar 2019) baut auf einer ersten Version auf, die das Team 2018 veröffentlicht hat, und basiert selbst auf der GAN-Architektur.
GAN Machine Learning - Was ist ein GAN?
Ein GAN (Generative Adversarial Network) ist ein sehr effektiver, nicht überwachter Lernalgorithmus, der bei bestimmten Problemen der Computervision weit verbreitet ist.
Es ist insbesondere diese Art von maschinellem Lernalgorithmus, der verwendet wird, um die Deepfakes zu erstellen, die wir in einem unserer vorherigen Artikel besprochen haben.
Konkret besteht ein GAN aus zwei neuronalen Netzen, die gleichzeitig gegeneinander trainieren, um falsche Bilder zu erzeugen.
Das erste ist der Generator (G), der aus einem zufälligen Rauschvektor (z) falsche Bilder von Gesichtern erzeugt. Dies ermöglicht es dem Algorithmus, bei jeder neuen Iteration ein anderes Gesicht zu erzeugen.
Der Diskriminator (D) hingegen lernt, zwischen den vom Generator erzeugten falschen Bildern und dem echten Leben zu unterscheiden. In der Praxis ist er also ein Klassifizierer.
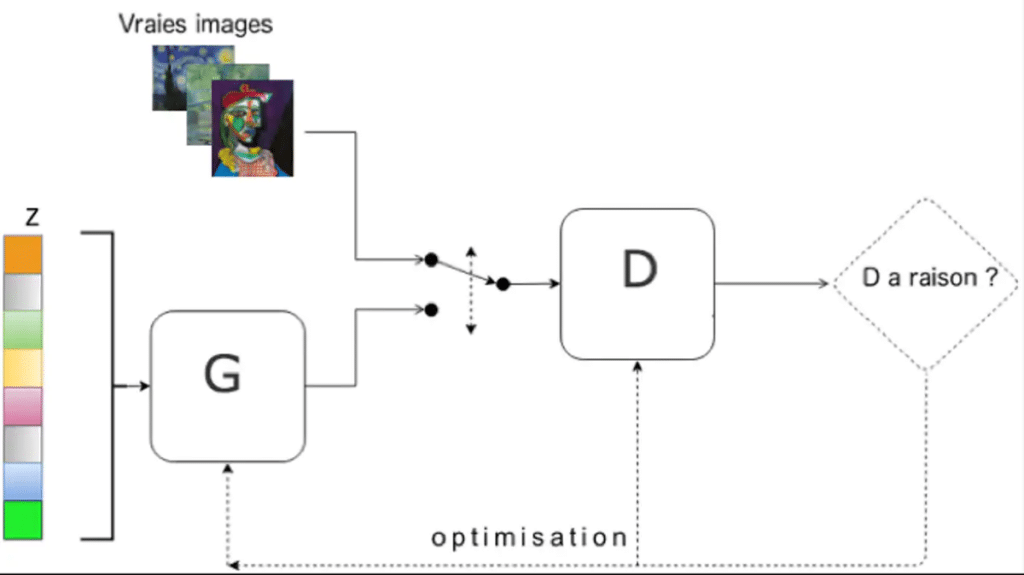
Zu Beginn wird keines der beiden Netzwerke trainiert. Während des Trainings wird der Diskriminator sowohl mit realen Bildern als auch mit Bildern aus dem Generator konfrontiert. Sein Ziel ist es dann, die Herkunft jedes Bildes zu unterscheiden. Parallel dazu lernt der Generator, ein Bild zu erzeugen, das den Diskriminator täuschen kann. Mit der Zeit wird der Generator immer besser darin, realistische Bilder zu erzeugen, während es dem Diskriminator gelingt, Fehler in den immer leichteren gefälschten Bildern zu finden.
Durch diesen adversen Lernprozess kann das neuronale Netz lernen, so realistisch Fotografien von Menschen zu erstellen.
GAN Machine Learning: Woher kommt GAN?
Künstliche Intelligenz hat riesige Fortschritte gemacht, wenn es darum geht, Objekte in einem Bild zu identifizieren.
Die KI ist z. B. auch in der Lage, die Regeln eines Spiels zu entwirren, indem sie tausende Male gegen sich selbst spielt. Problematisch wird es jedoch, wenn man von einer KI verlangt, etwas Neues zu schaffen, etwas, das es vorher nicht gab. Denn die KI kann zwar unsere Intelligenz simulieren, aber nicht unsere Vorstellungskraft.
Während einer Diskussion in einer Bar mit anderen Doktoranden im Jahr 2014 hatte ein Student der Universität Montreal namens Ian Goodfellow eine Idee, wie man diese Hürde überwinden könnte.
Wie fast alles in der Wissenschaft ließ sich der junge Mann von früheren Forschungen inspirieren, wie den von Jürgen Schmidhuber in den 1990er Jahren veröffentlichten Arbeiten über „Predictability Minimization“ (Verringerung der Vorhersagbarkeit) und „Artificial Curiosity“ (künstliche Neugier) sowie dem Konzept des „Turing-Learning“.
GAN Machine Learning: Wozu dient GAN?
Eine der neuesten und überraschendsten Anwendungen dieser Technologie, die es ermöglicht, „ein Gesicht auf ein anderes zu setzen„, ist die Generierung von falschen menschlichen Gesichtern wie das von Nvidia entwickelte DCGAN. Dieser ermöglicht es nun, hyperrealistische (oder fast hyperrealistische) Gesichter zu erzeugen, die keiner echten Person entsprechen.
Auf der Grundlage dieser Technologie wurden auch mehrere Webgeneratoren entwickelt. Sie beschränken sich nicht auf Gesichter, sondern verwenden Manga-Figuren oder Katzen.
Aber der Nutzen eines GAN beschränkt sich nicht nur auf Bilder. Es kann auch in Videos verwendet werden, wie im Fall der umstrittenen Deepfakes.
Goodfellow ist jedoch davon überzeugt, dass seine Kreation der Menschheit noch viel mehr bieten kann.
GAN hat das Potenzial, Gegenstände zu erzeugen, die wir in der realen Welt verwenden können. In einer nicht allzu fernen Zukunft könnte GAN in verschiedenen Disziplinen eingesetzt werden, z. B. bei der Entwicklung von Medikamenten, schnelleren Chips, erdbebensicheren Gebäuden, effizienteren Fahrzeugen oder kostengünstigen Gebäuden.
Dabei ist zu berücksichtigen, dass diese Technologie noch in den Kinderschuhen steckt.
Die Verbesserungen des StyleGAN
Die GAN-Architektur weist jedoch noch einige Einschränkungen auf:
- Es ist schwierig, hochauflösende Bilder für GAN zu erzeugen. Dies liegt daran, dass die Anzahl der Parameter, die von Anfang an gelernt werden müssen, besonders hoch ist.
- Den erzeugten Bildern fehlte es an Vielfalt. GANs sind ziemlich anfällig für den so genannten ‚collapse mode‘.
- Das heißt, dass der Generator immer die gleichen Bilder erzeugt, die es schaffen, den Diskriminator zu täuschen.
- Schließlich kann man die Ausgabeeigenschaften der erzeugten Bilder nicht kontrollieren.
Durch Progressive Growing oder allmähliches Wachstum können die Auflösungsbeschränkungen gelöst werden. Konkret bedeutet adaptives Growing, dass das Modell auf Bildern mit steigender Auflösung trainiert wird. Während des Lernens werden dem Generator und Diskriminator weitere Schichten hinzugefügt, um mit Bildern mit höherer Auflösung zu arbeiten und gleichzeitig die Vorteile des bereits erfolgten Lernens zu nutzen.
Darüber hinaus verbessert das Progressive Growing auch die Stabilität des Algorithmus und die Vielfalt der erzeugten Bilder.
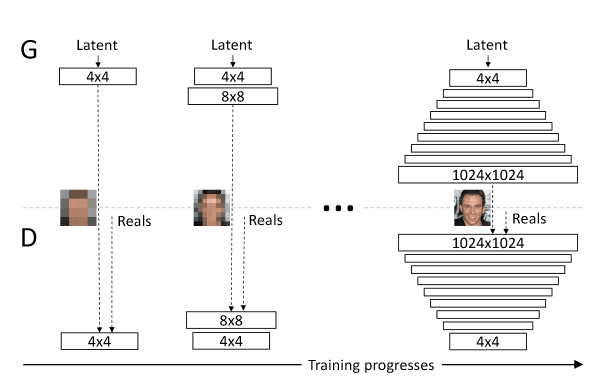
Um die Eigenschaften der erzeugten Bilder zu kontrollieren, versucht man, den Rauschvektor (z) mit den gewünschten Eigenschaften zu dekorrelieren (disentangle).
Stell dir vor, du möchtest eine Person mit Brille erzeugen: Wenn du nur einen Wert des Rauschvektors änderst, kann das viele verschiedene Veränderungen hervorrufen. Das liegt daran, dass ein Rauschwert nicht direkt mit einem einzigen Merkmal des Bildes korreliert ist. Man versucht also, die Dimensionen des Rauschvektors mit den Bildfeatures zu entflechten.
Die Entflechtung wird insbesondere dadurch ermöglicht, dass ein Zwischen-Rauschvektor in einem Unterraum erzeugt wird, in dem die Dimensionen entkorreliert sind.
Schließlich verwendet StyleGan weitere, komplexere Verbesserungen wie Adaptive Instance Normalization und Style Mixing.
Fazit - GAN Machine Learning
Durch die Behebung einiger Mängel des klassischen GAN haben StyleGAN und sein Nachfolger StyleGAN2 den Stand der Technik für die Erzeugung realistischer Bilder durch maschinelles Lernen definiert.
Es gibt jedoch noch einige Punkte, die verbessert werden müssen, wie z. B. die Behandlung von Hintergründen.
Auf dieser Website kannst du üben, Bilder zu erkennen, indem du den Diskriminator spielst.
Wenn du mehr über Computer Vision und künstliche Intelligenz, die auf Bilder angewandt wird, lernen möchtest: Entdecke einen unserer Kurse.







