Neuronale Netze sind in der Welt der Daten mittlerweile allgegenwärtig, aber wenn es ein innovatives Konzept gibt, das in den letzten Jahren aufgekommen ist, dann sind es GANs. Diese Netze, die durch Konfrontation lernen, sind besonders effizient, und wenn dieses Konzept mit dem neuesten Stand der Bildverarbeitungstechniken kombiniert wird, erhält man das, was wir in diesem Artikel behandeln werden, die DCGANs oder Deep Convolutional Generative Adversarial Networks (Deep Convolutional Generative Adversarial Networks).
Was ist das GAN-Konzept?
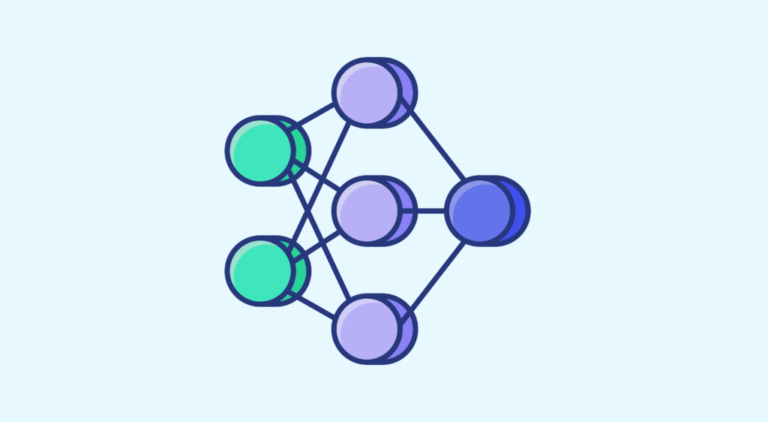
Zur Erinnerung: Das Konzept der GANs besteht darin, dass zwei Netzwerke, der Generator (G) und der Discriminator (D), gegeneinander antreten. Der Generator lernt, ein realistisches Bild (ähnlich wie in einem Datensatz) zu erzeugen, das vom Diskriminator, der bereits Bilder aus dem Datensatz gesehen hat, beurteilt wird. Wenn das D-Netz falsch ist, muss es aus seinem Fehler lernen, wenn das D-Netz richtig liegt, muss das G-Netz sich verbessern.
Das Lernen erfolgt über die Loss Functions der beiden Netzwerke, wie bei traditionellen Netzwerken.
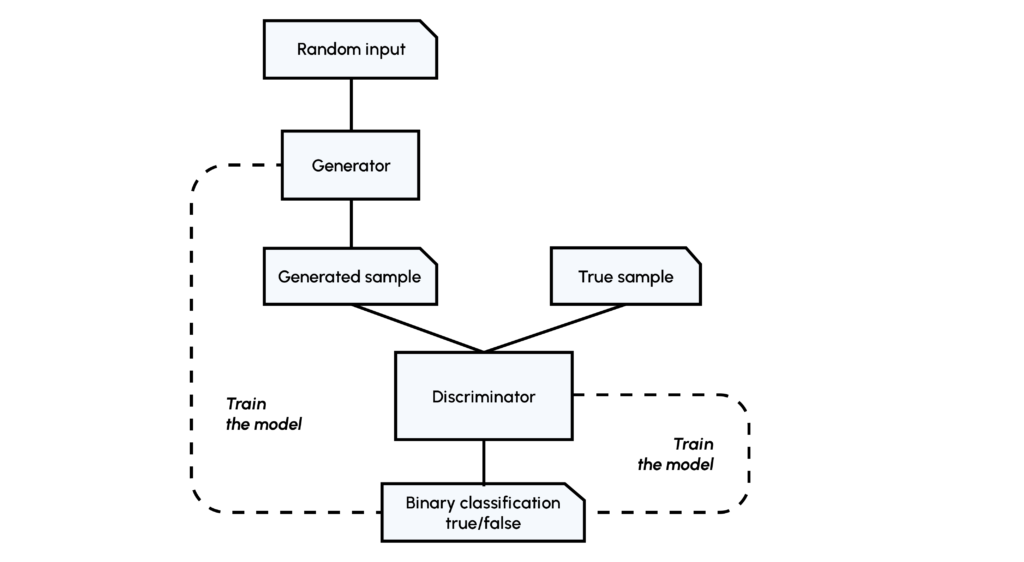
Wenn du mehr darüber erfahren möchtest, haben wir einen Artikel über das Konzept der GANs und ihre Verwendung.
Schon bald wurden die Grenzen dieser Methode deutlich: Die erzeugten Bilder waren nicht realistisch genug, insbesondere wenn man versuchte, die Qualität oder die Feinheit der Bilder zu erhöhen. Diese Grenze liegt in der Struktur der Generator- und Diskriminator-Netzwerke selbst begründet. Einfache, dichte Netzwerke (feed-forward oder fully connected) erlauben es nicht, alle Besonderheiten eines Bildes optimal zu nutzen. Dazu müssen komplexere Netzwerke verwendet werden, die als Convolutional Neural Networks (CNNs oder ConvNets) bezeichnet werden.
Bevor wir auf die Details der DCGAN-Implementierung eingehen, ist es notwendig, die Schlüsselkonzepte zu verstehen, aus denen sich CNNs zusammensetzen. Insbesondere die Convolution Layer. Wenn du mit diesen nicht vertraut bist, kannst du sie in einem unserer Artikel nachlesen.
Wie baut man den Diskriminator?
In unserem DCGAN muss das Diskriminatornetzwerk aus einem echten oder falschen Bild eine Klassifizierung erstellen. Man könnte also auf ein klassisches CNN vom Typ LeNet zurückgreifen, aber die Entwickler der DCGAN-Architektur haben festgestellt, dass einige spezifische Parameter interessanter sind.
Downsampling: Um die Größe unserer Faltungsschichten schrittweise zu reduzieren und Überlernen zu vermeiden, ist es üblich, Pooling-Schichten zu verwenden. Hier haben sich Faltungsschichten mit Stride als effektiver erwiesen, d.h. der Faltungsfilter wird jedes Mal um mehr als ein Feld verschoben:
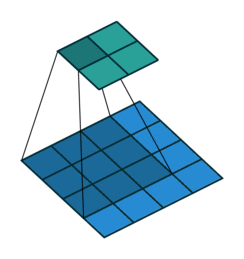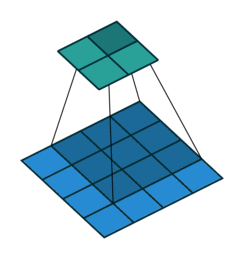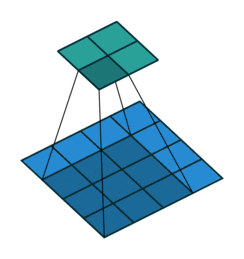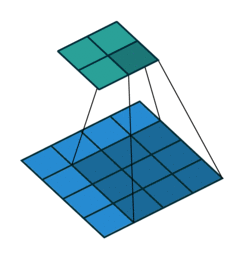
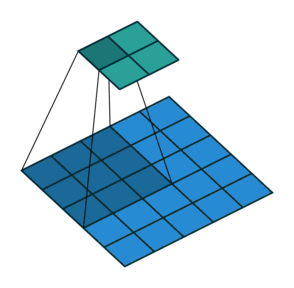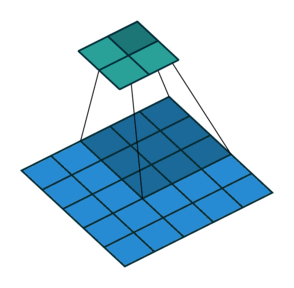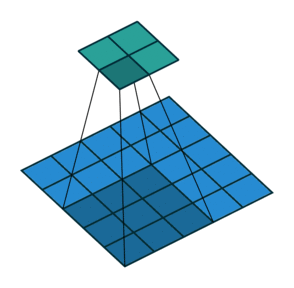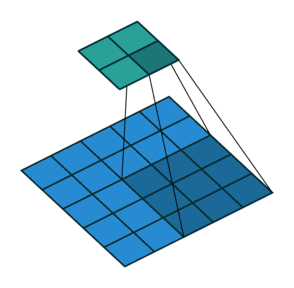
- Batch Normalization: Diese Normalisierung der Gewichte nach jeder Faltungsschicht (also pro Stride) ermöglicht ein stabileres und schnelleres Lernen des Netzes, daher ist es nicht notwendig, Bias in unseren verschiedenen Schichten zu verwenden!
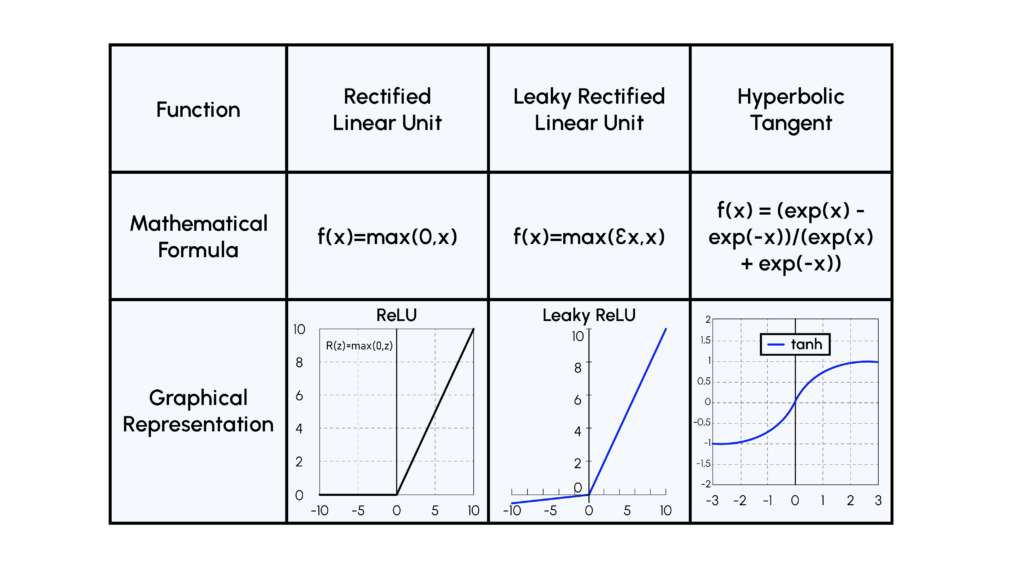
- Activation Function: Die ReLU-Funktion schien im Rahmen des Trainings des Discriminators in einen Zustand zu konvergieren, in dem alle Gewichte des Netzes inaktiv waren. Daher verwenden wir eine Variante dieser Funktion, die LeakyReLU genannt wird.
Aufbau des Generators
Die Rolle des Generatornetzwerks besteht darin, von einem zufälligen Vektor zu einem Bild zu gelangen, das den Diskriminator täuschen kann. Daher müssen wir neue Techniken verwenden, die wir als umgekehrtes Faltungsnetzwerk beschreiben können:
Upsampling: Um die Dimension unseres Vektors zu einem Bild zu vergrößern, müssen wir sogenannte transponierte Faltungen verwenden, wie unten dargestellt:
- Batch Normalization: Hier wird die gleiche Logik wie beim Discriminator angewandt.
- Activation Function: Hier wird in allen Ebenen die ReLU-Funktion verwendet, außer in der letzten, wo eine tanh-Funktion verwendet wird, weil es effizienter ist, normalisierte Bilder als Input für den Discriminator zu verwenden!
Hier sind mehrere Illustrationen von Aktivierungsfunktionen:
Außerdem machen die besonderen Konstruktionen der Discriminators und Generators die dichten Schichten, die man normalerweise in CNNs findet, überflüssig.
Training oder Trainingsloop
Wenn du bis hierher gut aufgepasst hast, wirst du bemerkt haben, dass es einen wichtigen Schritt gibt, den wir noch nicht erwähnt haben, nämlich die Trainingsschleife oder Trainingsphase. Wenn du bereits mit dem Training von neuronalen Netzen vertraut bist, weißt du, dass es eine fast unendliche Anzahl von Hyperparametern gibt, die getestet werden müssen. Diese Problematik ist beim Training von DCGANs logischerweise doppelt so präsent, weshalb es üblich ist, Parameter zu verwenden, die empirisch als wirksam erwiesen sind, insbesondere von den Autoren des Papiers.
Wir werden hier lediglich die Grundzüge vorstellen:
- Initialisierung: Alle Gewichte werden nach einer bestimmten Gaußschen Verteilung initialisiert, um Konvergenzprobleme während des Lernens zu vermeiden.
- Gradientenabstieg: Dieser erfolgt stochastisch über Mini-Batch, aus demselben Grund wie die Initialisierung: Es stabilisiert das Training.
- Optimizer: Es wird der Adam Optimizer verwendet, der eine kontinuierliche Aktualisierung der Lernrate ermöglicht.
- Spezifische Einstellungen für das Momentum β1 und die Initialisierung der Lernrate werden verwendet, um das Training zu stabilisieren.
Es wurden viele technische Details angesprochen, dennoch sind dies Parameter, die immer häufiger im Deep Learning verwendet werden. Zum Beispiel werden transponierte oder Stride-Faltungen in vielen Deep-Learning-Anwendungen wie Image Inpainting, semantischer Segmentierung oder Super Resolution von Bildern verwendet. Ebenso ist der Adam-Optimizer ein sehr robuster Optimizer, der im Deep Learning allgegenwärtig ist.
Die „Einfachheit“ des DCGAN trägt zu seinem Erfolg bei. Allerdings wurde ein gewisser Engpass erreicht: Die Erhöhung der Komplexität des Generators führt nicht unbedingt zu einer besseren Bildqualität. Aus diesem Grund gab es in letzter Zeit viele Verbesserungen: cGANs, styleGANs, cycleGANs usw..
Du kannst die GANs, DCGANs und die Verbesserungen, die seither an diesen Netzwerken vorgenommen wurden, im Modul „Generative Adversarial Network“ unseres Kurses Deep Learning for Computer Vision finden.







