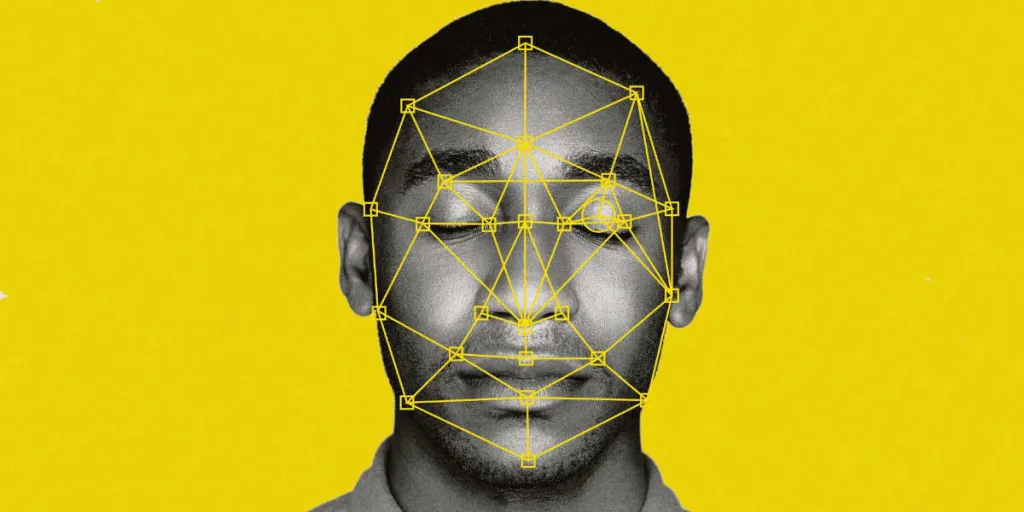
In den letzten Jahren hat sich die Technologie der Gesichtserkennung stark verbreitet und wird in verschiedenen Bereichen wie Medien, soziale Netzwerke, Überwachung und Sicherheit immer häufiger eingesetzt. Deep Learning, oder Deep Learning, ermöglicht es dem Netzwerk, automatisch aus den Daten zu lernen.
Deep Learning hat sich bei der Erkennung von Gesichtern als sehr effektiv erwiesen, da es mit riesigen Datenmengen umgehen kann und hohe Genauigkeitsraten erreicht. Die Fähigkeit von Deep Learning, automatisch Informationen aus Bildern zu extrahieren, wie z. B. Gesichtszüge, Farben und Kontraste, ist einer der Hauptvorteile von Deep Learning für die Gesichtserkennung.
Datenverarbeitung, der wichtigste Schritt im Prozess
Die Vorverarbeitung ist ein entscheidender Schritt, bevor die Bilddaten in das Gesichtserkennungsmodell eingegeben werden. Je nach den Eigenschaften des zur Verfügung stehenden Datensatzes und den speziellen Anforderungen der Anwendung können die erforderlichen Vorverarbeitungsschritte variieren. Unter ihnen finden sich jedoch gängige Vorgänge.
Beispielsweise wird durch die Skalierung des Bildes die Bildgröße für den gesamten Probensatz festgelegt. Durch das Festlegen einer Auflösung von 256 x 256 Pixeln wird sichergestellt, dass das Modell Bilder der gleichen Größe verarbeitet, was die Leistung des Modells erhöhen kann.
Wir können auch den Normalisierungsprozess erwähnen, der deinem Modell höchstwahrscheinlich bei seiner Arbeit helfen wird. Dazu können die Daten eines Bildes in einen bestimmten Farbraum transformiert werden, oder die Pixelwerte so verändert werden, dass sie einen Mittelwert von Null und eine Einheitsvarianz haben (Gaußsche Verteilung).
Die Ausrichtung des Gesichts auf den Fotos spielt ebenfalls eine große Rolle, da die Leistung des Modells durch die Position des Gesichts beeinflusst werden kann. Für die Ausrichtung können Gesichtsmarkierungen verwendet werden, und das Gesicht kann mithilfe eines Begrenzungsrahmens, der gemeinhin als bounding box bezeichnet wird, an einer bestimmten Position zugeschnitten werden.

Datenvergrößerung: Durch die Verwendung verschiedener Bildveränderungen, wie z. B. Spiegeln, Drehen oder Beschneiden, ist die Datenvergrößerung eine Technik, die verwendet wird, um die Menge des Datensatzes fiktiv zu verbessern. Dies könnte dazu beitragen, die Belastbarkeit und Verallgemeinerbarkeit des Modells zu verbessern. Im Folgenden ist das menschliche Auge vollständig in der Lage zu erkennen, dass es sich um das gleiche Bild handelt, das einigen Veränderungen unterzogen wurde. Für die Maschine wird das Bild jedoch wie ein neues Muster behandelt, da die Pixel ihre Position verändert haben.

Wir können auch die Hintergrundentfernung erwähnen: Die Leistung des Modells kann verbessert werden, indem das Hintergrundrauschen aus dem Bild entfernt wird. Dies kann erreicht werden, indem der Hintergrund vom Vordergrund mithilfe von Bildsegmentierungstechniken wie Schwellwertbildung oder Konturerkennung getrennt wird.
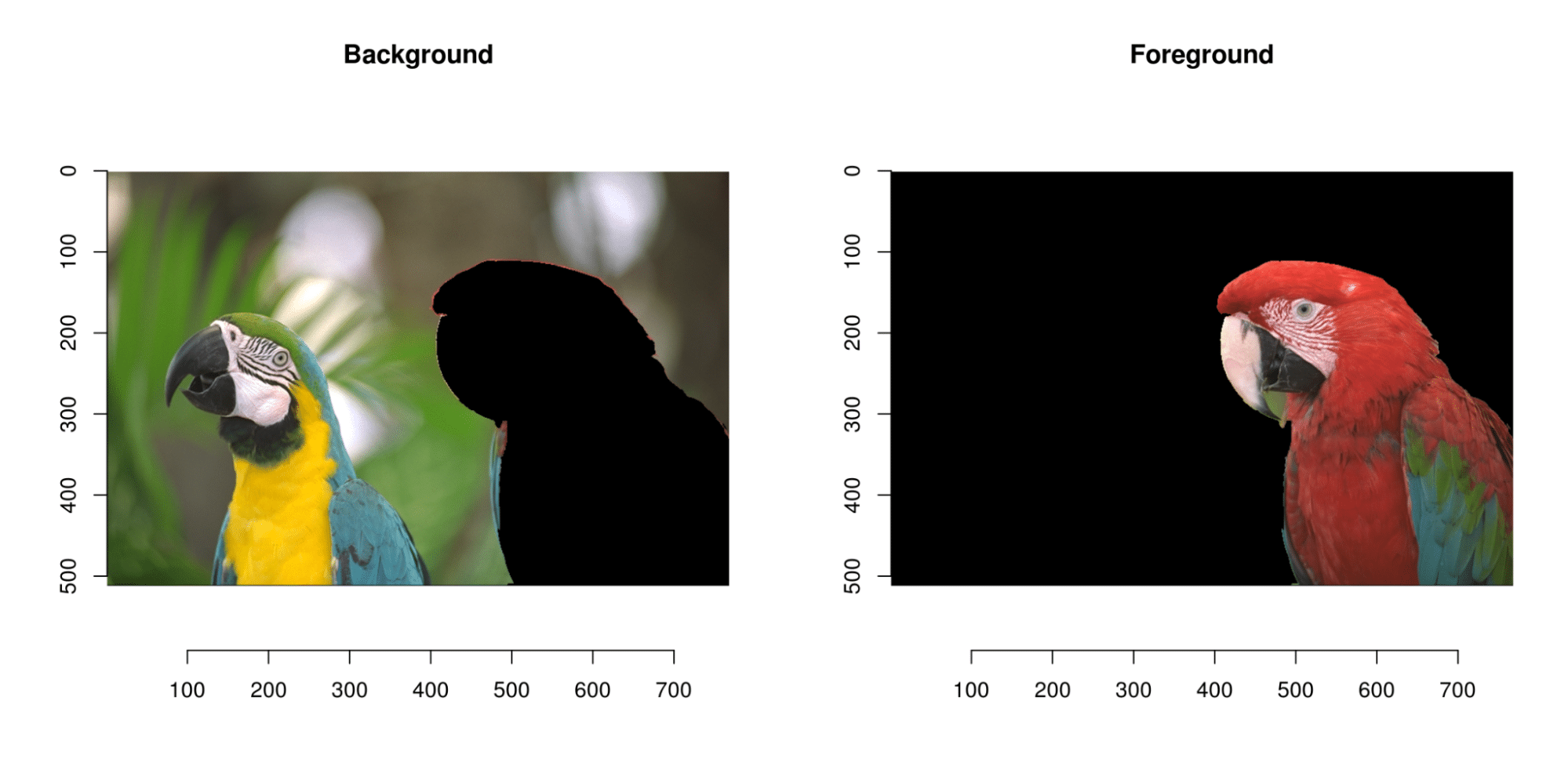
Es ist wichtig, daran zu denken, dass die verwendeten Vorverarbeitungsverfahren von den Eigenschaften des Datensatzes und den besonderen Anforderungen der Anwendung abhängen.
Die Vorverarbeitung ist also ein entscheidender Schritt bei der Gesichtserkennung, da sie die Bilddaten für das Modell aufbereitet und die Effektivität, Geschwindigkeit und Effizienz des Systems verbessert. Zu den häufigen Vorverarbeitungstechniken gehören das Skalieren von Bildern, Normalisieren, Ausrichten, Erhöhen der Datenmenge, Entfernen des Hintergrunds und Erkennen von Gesichtern.
Convolutional Neural Network (CNN) : Definition, Eigenschaften und Funktionsweise
Faltungsneuronale Netze sind ein Typ von Deep-Learning-Architekturen, die sich besonders gut für Bilderkennungsaufgaben wie die Gesichtserkennung eignen.
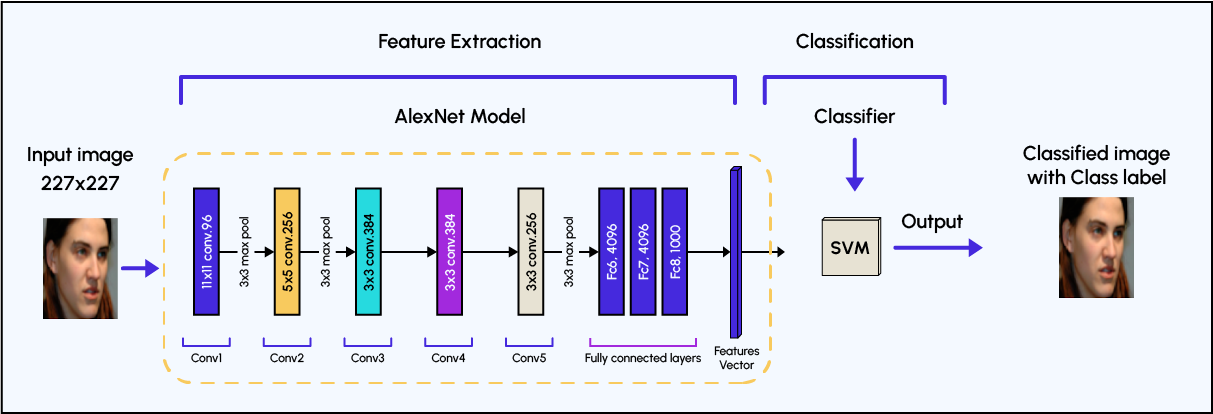
In einem CNN für die Gesichtserkennung wird das Netzwerk auf einem Datensatz aus Bildern von Gesichtern und Bildern ohne Gesichter trainiert. Das CNN lernt, wichtige Merkmale eines Gesichts zu erkennen, z. B. die Form der Augen, der Nase und des Mundes sowie die allgemeine Geometrie und Textur des Gesichts. Diese Merkmale werden dann verwendet, um ein Gesicht in einem neuen Bild zu identifizieren.
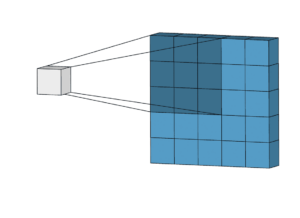
Die Architektur eines CNN besteht in der Regel aus mehreren Schichten, von denen jede eine bestimmte Funktion hat. Die erste Schicht, die sogenannte Eingabeschicht, empfängt die rohen Bilddaten. Die nachfolgenden Schichten, die als Faltungsschichten oder verborgene Schichten bezeichnet werden, verwenden eine Reihe von Filtern, um Merkmale aus dem Bild zu extrahieren. Diese Filter gleiten über das Bild (Faltungsschritt) und suchen nach bestimmten Mustern und Merkmalen.
Die resultierenden Merkmale werden dann durch eine nichtlineare Aktivierungsfunktion, wie z. B. eine rektifizierte lineare Einheit (Rectified Linear Unit, ReLU), geleitet, die Nichtlinearität in das Netzwerk einbringt und es ihm ermöglicht, komplexere Muster zu lernen.
Nach den Faltungsschichten enthält das Netz Gruppierungs- oder Poolingschichten, die die räumliche Auflösung der vom Netz gelernten Merkmale verringern, während wichtige Informationen erhalten bleiben. Dies geschieht, indem das Maximum oder der Durchschnitt eines kleinen Bereichs der Merkmalskarte genommen wird. Die Pooling-Schichten machen das Netzwerk robuster gegenüber kleinen Änderungen der Position des Gesichts im Bild.

Schließlich werden die Merkmale durch vollständig verbundene Schichten (fully connected layer) weitergegeben, die die Aufgabe der Klassifizierung durchführen. Diese Schichten geben eine Wahrscheinlichkeit für jede mögliche Klasse aus, im Fall der Gesichtserkennung ein Gesicht oder kein Gesicht. Diese Ausgabe wird dann mit einem Schwellenwert verglichen, um die endgültige Entscheidung zu treffen. Mit diesem Schwellenwert wird entschieden, wie genau die Entscheidung sein soll. Wenn der Schwellenwert beispielsweise bei 0,9 liegt, führt das Modell die Aufgabe der Gesichtserkennung nur dann aus, wenn seine Leistung bei der Zuordnung des Bildes zu einer bestimmten Person größer als dieser Wert ist.
Es ist wichtig zu beachten, dass CNNs für die Gesichtserkennung mit einem großen Datensatz von Bildern verschiedener Personen trainiert werden, wodurch sie ein breites Spektrum an Personen mit hoher Genauigkeit identifizieren können. Allerdings ist ein diversifizierter Datensatz notwendig, um Verzerrungen zu vermeiden, da die Leistung dieser Modelle von der Demografie der Personen im Datensatz beeinflusst werden kann.
Welche Architekturen konkurrieren mit Faltungsneuronennetzen?
In den letzten Jahren wurden mehrere neue Deep-Learning-Architekturen (oder Deep Learning Architectures) für die Gesichtserkennung entwickelt. Hier sind einige Beispiele:
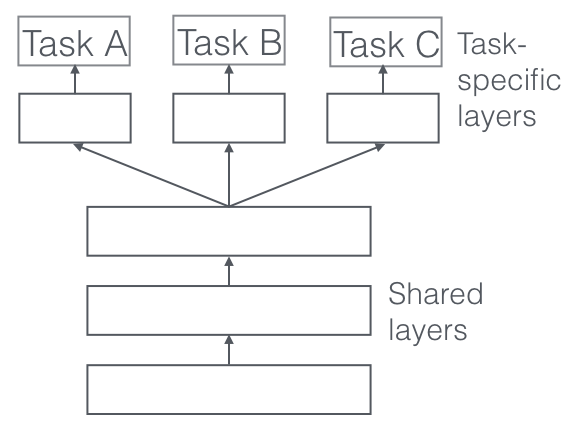
Multi-Tasking-Lernarchitekturen (MTL): Multi-Tasking-Lernen ist eine Art von Deep-Learning-Architektur, die mehrere Aufgaben gleichzeitig lernen kann, wie z. B. Gesichtserkennung und das Erkennen von Gesichtsmarkierungen. Dies kann die Gesamtleistung des Modells verbessern und die Menge an Daten, die für das Training benötigt werden, reduzieren.
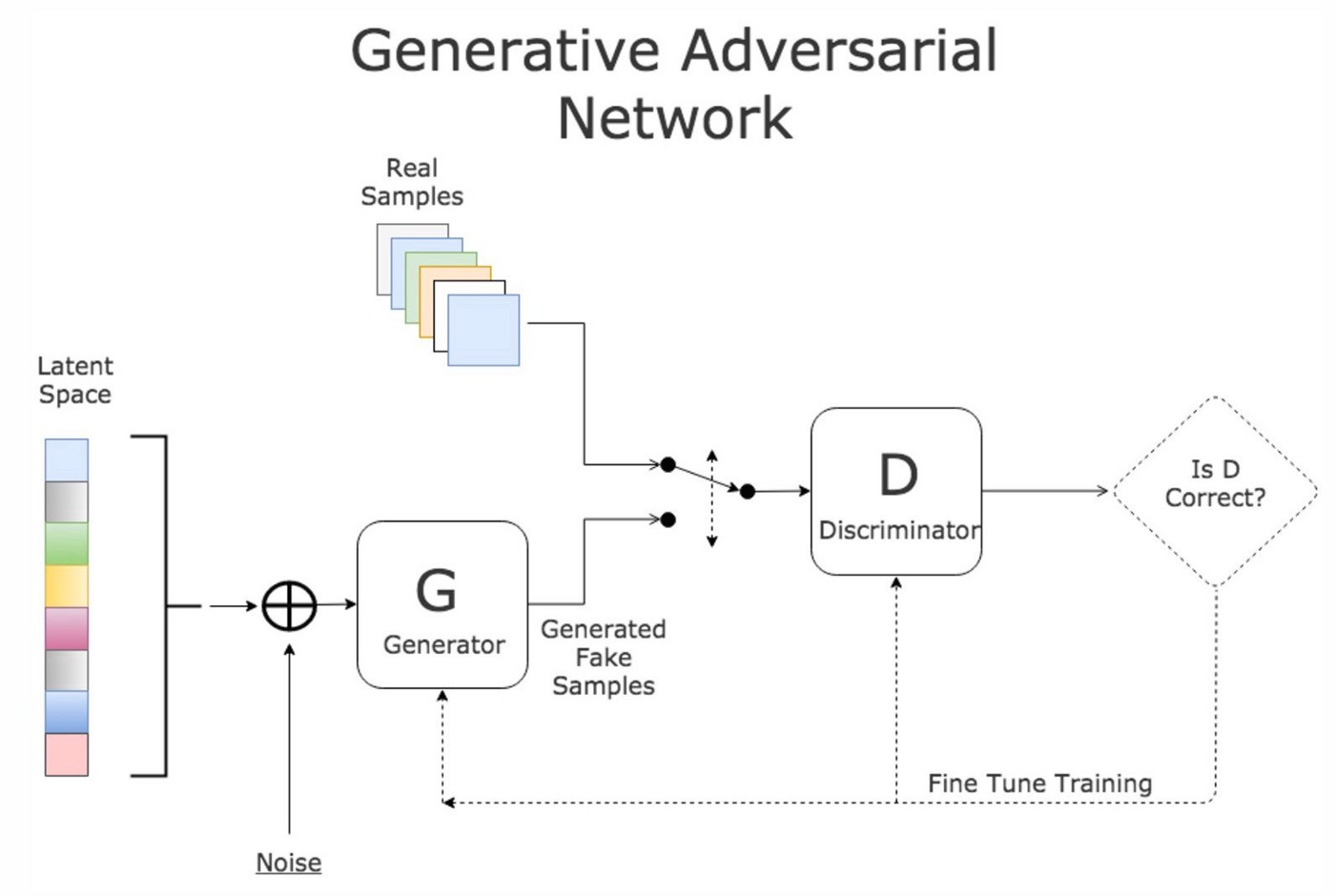
Generative antagonistische Netze (GAN): GANs sind eine Art Architektur für tiefes Lernen, die aus zwei Netzen besteht: einem Generator und einem Diskriminator. Der Generator erzeugt neue Bilder, die den Lerndaten ähnlich sind, während der Diskriminator versucht, zwischen den erzeugten und den tatsächlichen Bildern zu unterscheiden. GANs wurden für die Gesichtserkennung verwendet, indem der Generator trainiert wurde, Bilder von Gesichtern zu erzeugen, die den Diskriminator täuschen können.
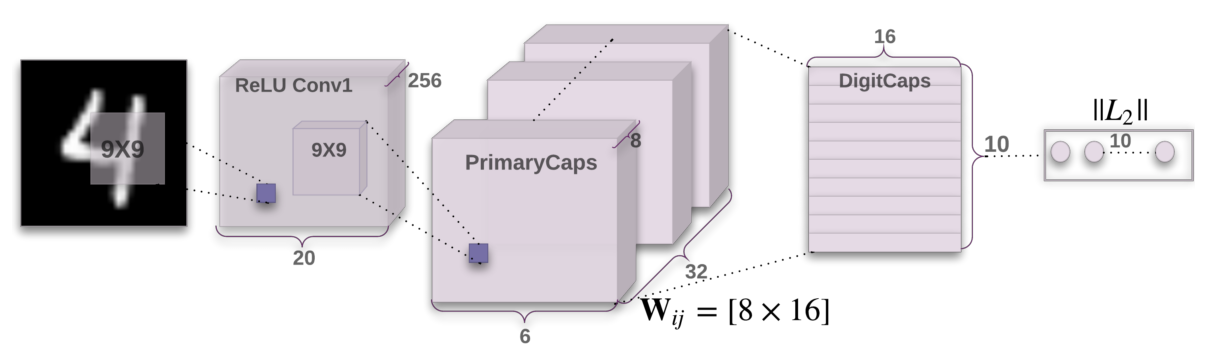
Kapselnetzwerke: Kapselnetzwerke sind eine Art von Deep-Learning-Architektur, die entwickelt wurde, um die räumlichen Beziehungen zwischen Teilen eines Bildes besser zu erfassen, z. B. die Position von Augen, Nase und Mund in einem Gesicht. Dies kann die Genauigkeit der Gesichtserkennung verbessern, vor allem bei Gesichtern, die teilweise verdeckt sind oder aus verschiedenen Winkeln betrachtet werden.
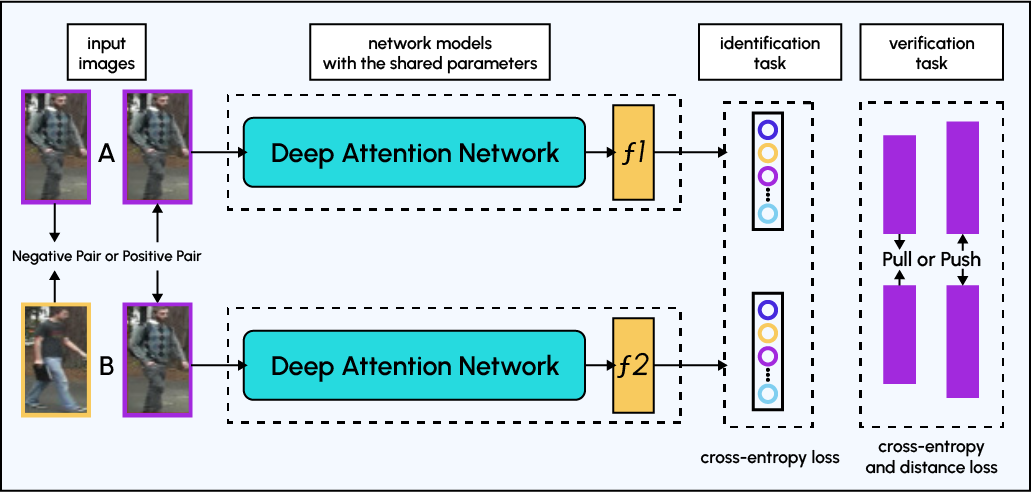
Aufmerksamkeitsbasierte Modelle: Aufmerksamkeitsbasierte Modelle sind Architekturen für tiefes Lernen, die Aufmerksamkeitsmechanismen nutzen, um sich auf die informativsten Bereiche eines Bildes zu konzentrieren, wie z. B. Augen, Nase und Mund eines Gesichts. Dies kann die Leistung der Gesichtserkennung verbessern, vor allem bei Gesichtern, die teilweise verdeckt sind oder aus verschiedenen Winkeln betrachtet werden.
Leichtgewichtige Architekturen: Leichtgewichtige Architekturen wie MobileNet, ShuffleNet und EfficientNet sind so konzipiert, dass sie weniger rechenintensiv sind als herkömmliche CNNs. Das kann sie für die Gesichtserkennung auf mobilen Geräten und eingebetteten Systemen mit begrenzten Rechenressourcen besser geeignet machen.
Es ist wichtig zu beachten, dass diese Architekturen immer Gegenstand von Forschung und Verbesserungen sind und dass die beste Architektur für einen bestimmten Anwendungsfall von den Eigenschaften des Datensatzes, den verfügbaren Rechenressourcen und den spezifischen Anforderungen der Anwendung abhängt.
Gesichtserkennung und DSGVO: Ist das vereinbar?
Die Technologie der Gesichtserkennung schafft erhebliche ethische und Datenschutzprobleme, insbesondere bei der Anwendung von Deep Learning oder Tiefenlernen. Tatsächlich wirft der Einsatz von Gesichtserkennung Fragen zum Datenschutz und zur Möglichkeit des Datenmissbrauchs auf. Darüber hinaus gibt es Probleme mit Verzerrungen in den Trainingsdaten, die zu Fehlern und Vorurteilen gegenüber bestimmten Gruppen führen können.

Aus diesem Grund ist es unerlässlich, geeignete Gesetze und Richtlinien einzuführen, um den verantwortungsvollen Umgang mit dieser Technologie zu gewährleisten.
Die Datenschutz-Grundverordnung (DSGVO) ist eine Verordnung der Europäischen Union (EU), die am 25. Mai 2018 in Kraft getreten ist. Sie ersetzt die EU-Datenschutzrichtlinie von 1995 und stärkt die europäischen Datenschutzgesetze. Die DSGVO regelt die Erhebung, Speicherung und Nutzung personenbezogener Daten, einschließlich biometrischer Daten wie z. B. der Gesichtserkennung.
Die Gesichtserkennungstechnologie, die Algorithmen verwendet, um das Gesicht einer Person zu identifizieren und abzugleichen, kann biometrische Daten wie Gesichtszüge, geometrische Muster und sogar Verhaltensmerkmale verarbeiten. Das bedeutet, dass die Gesichtserkennungstechnologie in den Anwendungsbereich der DSGVO fällt, da sie personenbezogene Daten verarbeitet.
Gemäß der DSGVO müssen Organisationen die ausdrückliche Zustimmung von Einzelpersonen zur Erhebung und Verarbeitung ihrer personenbezogenen Daten einholen. Organisationen müssen Einzelpersonen auch über die spezifischen Zwecke, für die ihre Daten verwendet werden, und die Dauer ihrer Speicherung informieren. Sie müssen den Einzelpersonen auch das Recht auf Zugang, Berichtigung oder Löschung ihrer persönlichen Daten anbieten.
Darüber hinaus müssen Organisationen, die Gesichtserkennungstechnologie einsetzen, eine Datenschutz-Folgenabschätzung (DPIA) durchführen, bevor sie die Technologie einsetzen. Eine DPIA (engl. Data Protection Impact Assessment) ist ein Prozess, der Organisationen dabei hilft, die Risiken, die mit der Verarbeitung personenbezogener Daten verbunden sind, zu identifizieren und zu mindern. Dazu gehört auch die Bewertung der Auswirkungen der Technologie auf die Rechte und Freiheiten von Einzelpersonen sowie die Bewertung der Wirksamkeit der Maßnahmen, die zum Schutz der personenbezogenen Daten ergriffen wurden.







