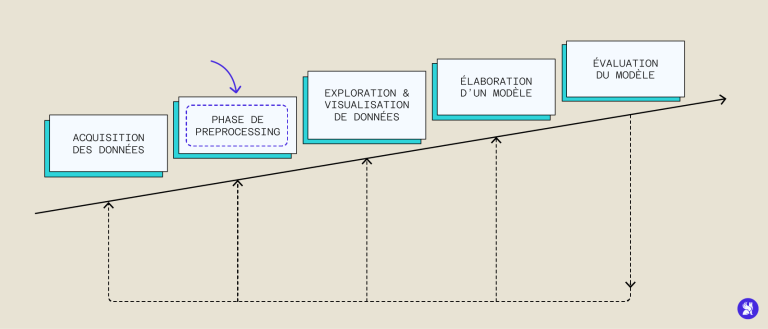
Da immer mehr Daten erfasst und systematisch verarbeitet werden, haben sich Machine-Learning-Methoden durchgesetzt, die viele Daten benötigen, um zu laufen und zu trainieren. Obwohl man naiv annehmen könnte, dass eine große Anzahl von Daten ausreicht, um einen leistungsfähigen Algorithmus zu haben, sind die uns zur Verfügung stehenden Daten meistens ungeeignet und müssen meist vorab bearbeitet werden, um sie anschließend nutzen zu können: das ist der Schritt des Preprocessing.
Fehler bei der Datenerfassung, die auf menschliche oder technische Fehler zurückzuführen sind, können unser Dataset verderben und das Training verzerren. Zu diesen Fehlern gehören unvollständige Informationen, fehlende oder falsche Werte oder Störgeräusche, die mit der Datenerfassung zusammenhängen. Daher ist es oft notwendig, eine Strategie der Datenvorverarbeitung – auch Data Preprocessing genannt – aus unseren Rohdaten zu erstellen, um zu verwertbaren Daten zu gelangen, die uns ein besseres Modell liefern. Wir werden die wichtigsten Schritte des Data Preprocessing, ihre Bedeutung und ihre Implementierung in Python untersuchen.
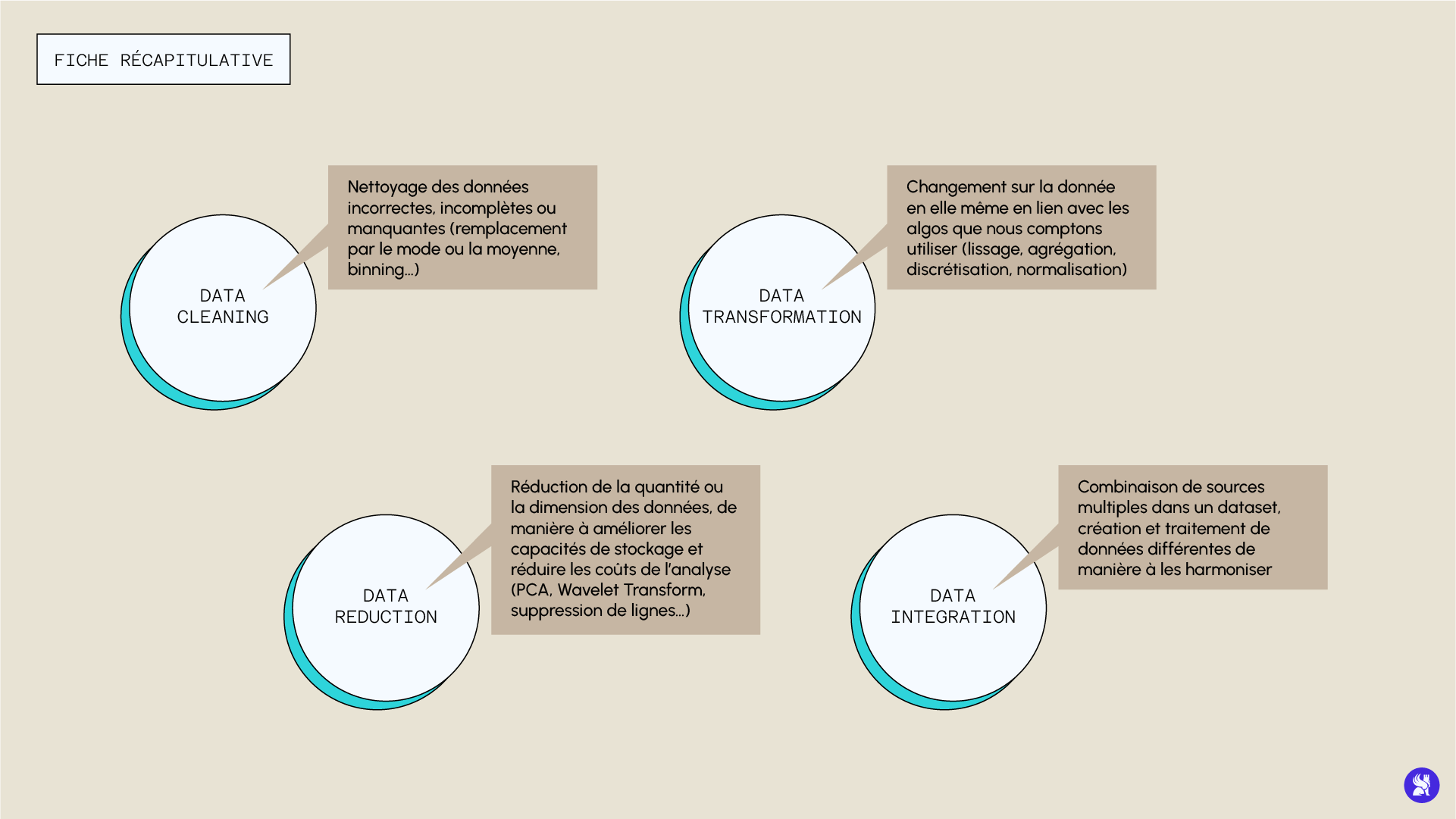
Data Cleaning
Der erste Schritt ist die Bereinigung von falschen, unvollständigen oder fehlenden Daten. Es gibt verschiedene Möglichkeiten, mit diesen Problemen umzugehen, die wir im Folgenden besprechen.
Wenn Daten im Dataset fehlen, kannst du sie überspringen, wenn die Datenbank gut gefüllt ist und viele Daten in einer Zeile fehlen. Du kannst auch entscheiden, die fehlenden Daten auf verschiedene Arten zu füllen: Du kannst sie durch den Mittelwert, den Median oder z. B. bei kategorialen Variablen durch die häufigste Modalität (auch Modus genannt) ersetzen. Pandas stellt uns Methoden zur Verfügung, mit denen wir diese Bearbeitungen wie folgt durchführen können:
Es kann vorkommen, dass Daten unter störendem Rauschen bei der Erfassung leiden, in diesem Fall können sie von einem Computer nicht richtig verarbeitet werden. Eine Möglichkeit, dieses Problem zu lösen, ist das Binning der (vorsortierten) Daten. Die Daten werden in Gruppen gleicher Größe aufgeteilt und jede Gruppe wird unabhängig verarbeitet. Innerhalb einer Gruppierung können alle Daten durch ihren Mittelwert, Median oder die Extremwerte ersetzt werden.
Eine andere Möglichkeit, mit verrauschten Daten umzugehen, ist die Verwendung von Regression oder Clustering, die automatisch Gruppen von Daten bilden, mit deren Hilfe wir Ausreißer erkennen und aus der Datenbank entfernen können.

Data Transformation
Diese Vorverarbeitungsstufe umfasst die Veränderungen, die an der eigentlichen Struktur der Daten vorgenommen werden. Diese Veränderungen stehen im Zusammenhang mit den mathematischen Definitionen der Algorithmen und der Art und Weise, wie diese die Daten verarbeiten, um die Leistung zu optimieren. Zu diesen Techniken gehören z. B. :
- Glättung der Daten, wenn sie verrauscht sind.
- Die Aggregation von Daten aus vielen verschiedenen Quellen.
- Die Diskretisierung kontinuierlicher Variablen (mithilfe der Intervallisierung), die es ermöglicht, die Anzahl der Modalitäten eines Deskriptors zu verringern, und schließlich.
- Normalisierung und Standardisierung von Daten, die numerische Daten auf eine kleinere Skala bringen (z. B. zwischen -1 und 1), die auch den Mittelwert zentrieren und die Varianz verringern kann.
Hier ist ein Beispiel für die Normalisierung, die in diesem Teil der Datenumwandlung am häufigsten benötigt wird:
Data Reduction
Obwohl es intuitiv erscheint, sich vorzustellen, dass eine sehr große Datenmenge die Leistung eines Modells verbessert, kann es sein, dass eine zu große Datenmenge die Analyse komplizierter machen kann. Daher kann es manchmal sinnvoll sein, die Menge oder Größe der Daten zu reduzieren, um die Speicherkapazität zu verbessern und die Kosten der Analyse zu senken, ohne dabei an Leistung zu verlieren (oder in manchen Fällen sogar zu gewinnen). Es gibt verschiedene Techniken zur Datenreduktion. Wir können z. B. eine Reihe von Variablen auswählen, die wir lieber behalten möchten, und andere weglassen. Die Auswahl der relevanten Variablen kann durch die Analyse des p-Wertes der Variablen oder durch Entscheidungsbaumtechniken erfolgen, die uns eine Schätzung der Wichtigkeit der verschiedenen Deskriptoren geben.
Eine weitere Technik, die bei der Idee der Datenreduktion häufig verwendet wird, ist die Dimensionsreduktion. Diese Methode reduziert die Dimension der Daten durch genau definierte Kodierungsmechanismen. Es gibt zwei Arten, verlustbehaftete und verlustfreie. Wenn man die genauen Daten aus den reduzierten rekonstruieren kann, spricht man von verlustfreier Reduktion. Andernfalls wird die Reduktion verlustbehaftet durchgeführt. Es gibt zwei bevorzugte Methoden, um auf diese Weise auf die Daten einzuwirken, eine Wavelet-Transformation oder eine PCA (Principal Component Analysis).
Data Integration
Dieser Schritt der Vorverarbeitungsstrategie besteht darin, mehrere Quellen in einem einzigen Datenbestand zu kombinieren. Er wird im Rahmen eines Datenmanagements durchgeführt, um nutzbare Datenbanken zu erstellen (wie z. B. die Erstellung von Bilddatenbanken, Querschnitten des Abdomens, MRTs oder Röntgenaufnahmen für diagnostische Hilfsprobleme). Dennoch könnten einige Probleme auftreten, wie z. B. die Inkompatibilität bestimmter Formate oder die Redundanz bestimmter Daten.
Der Schritt der Datenvorverarbeitung ist daher einer der wichtigsten Schritte in der Datenverarbeitung und -analyse. Es gibt keine perfekte Methode, die bei jeder Modellerstellung angewendet werden muss, aber wir haben uns gemeinsam die bewährten Verfahren angesehen, die in einer Strategie zur Vorverarbeitung von Daten eingesetzt werden sollten. Die hier vorgestellten Methoden werden in unseren verschiedenen Kursen weiter erforscht: Die grundlegenden mathematischen Konzepte sowie gute Praktiken der Datenvorverarbeitung je nach Kontext und Situation werden erläutert.
Um unsere Studiengänge im Detail zu entdecken und alle Best Practices des Data Preprocessing zu erlernen, besuche die dafür vorgesehene Seite.







