Der Neural Style Transfer (NST) ist eine Sammlung von Modellen und Methoden, die es ermöglichen, den visuellen Stil von Bildern oder Videos auf ein anderes Bild zu übertragen. In diesem Artikel beschäftigen wir uns mit einem bestimmten Modell, das CycleGAN heißt.
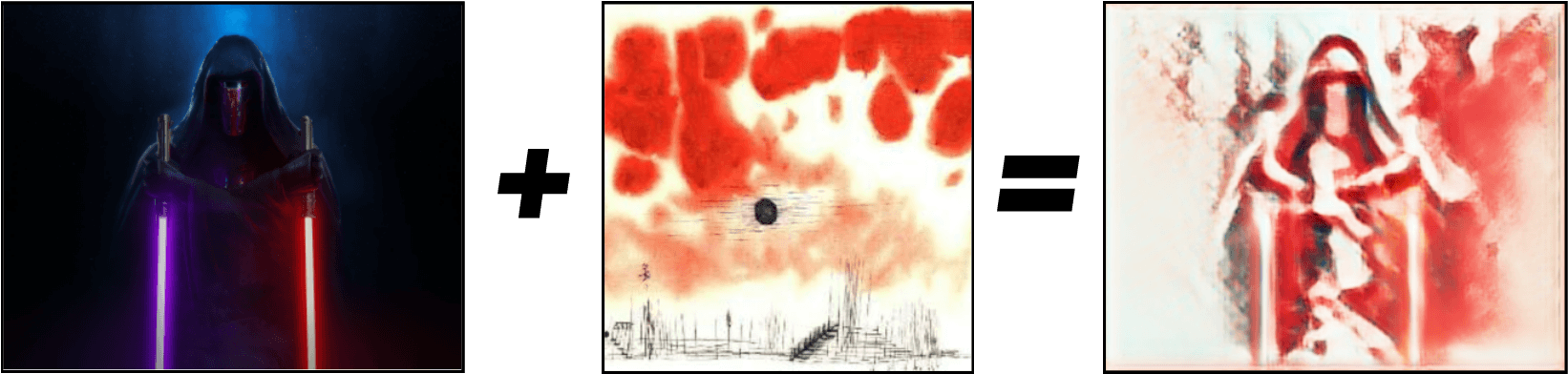
Heutzutage sind die erfolgreichsten Algorithmen im Bereich NST angepasste Deep-Learning-Algorithmen, die Faltungsschichten verwenden. In der Kunst wird NST am häufigsten verwendet, um aus einer Fotografie und dem Stil eines Malers künstliche Kunstwerke zu schaffen. Es gibt derzeit mehrere (mobile und webbasierte) Anwendungen, die Stilübertragung ermöglichen, z. B. DeepArt und Reiinakanos Blog. So kann man eine Star Wars-Figur (Darth Revan) in ein Gemälde verwandeln, das von Paul Klees Werk Clouds over Bor inspiriert ist :
Das CycleGAN-Modell, was ist das?
Wie der Name schon sagt, ist CycleGAN eine Art generatives Modell (erstellt von Jun-Yan Zhu et al. für das BAIR-Forschungslabor der UC Berkeley), ein GAN (Generative Adversarial Network), das dazu dient, die Stilübertragung auf ein Bild durchzuführen. In der Praxis wird die große Mehrheit der GANs, die zur Übertragung eines Bildes des Stils einer Domäne X in ein Bild des Stils einer Zieldomäne Y verwendet werden, mithilfe eines Zwillingsdatensatzes trainiert, in dem jedes Beispielbild von X ein direkt zugeordnetes Beispielbild in einem anderen Stil Y hat.
CycleGAN zeichnet sich gerade dadurch aus, dass es beim Training keine Bildpaare benötigt. Wenn man ein solches Modell trainiert, kann man sehr gute Leistungen erzielen, ohne jemals Bildpaare zu verwenden, was das Training für bestimmte Datensätze, bei denen es keine Übereinstimmungen gibt, erheblich vereinfacht. Man kann dann den Stil eines Malers für verschiedene Bilder nachahmen, indem man z. B. eine Datenbank mit seinen Bildern verwendet! Zunächst wollen wir die Architektur eines GAN vorstellen. Wenn du schon einmal einen unserer Artikel über GANs gelesen hast, weißt du, dass ein GAN ein Modell ist, das aus zwei großen Untermodellen besteht, einem Generator und einem Diskriminator:
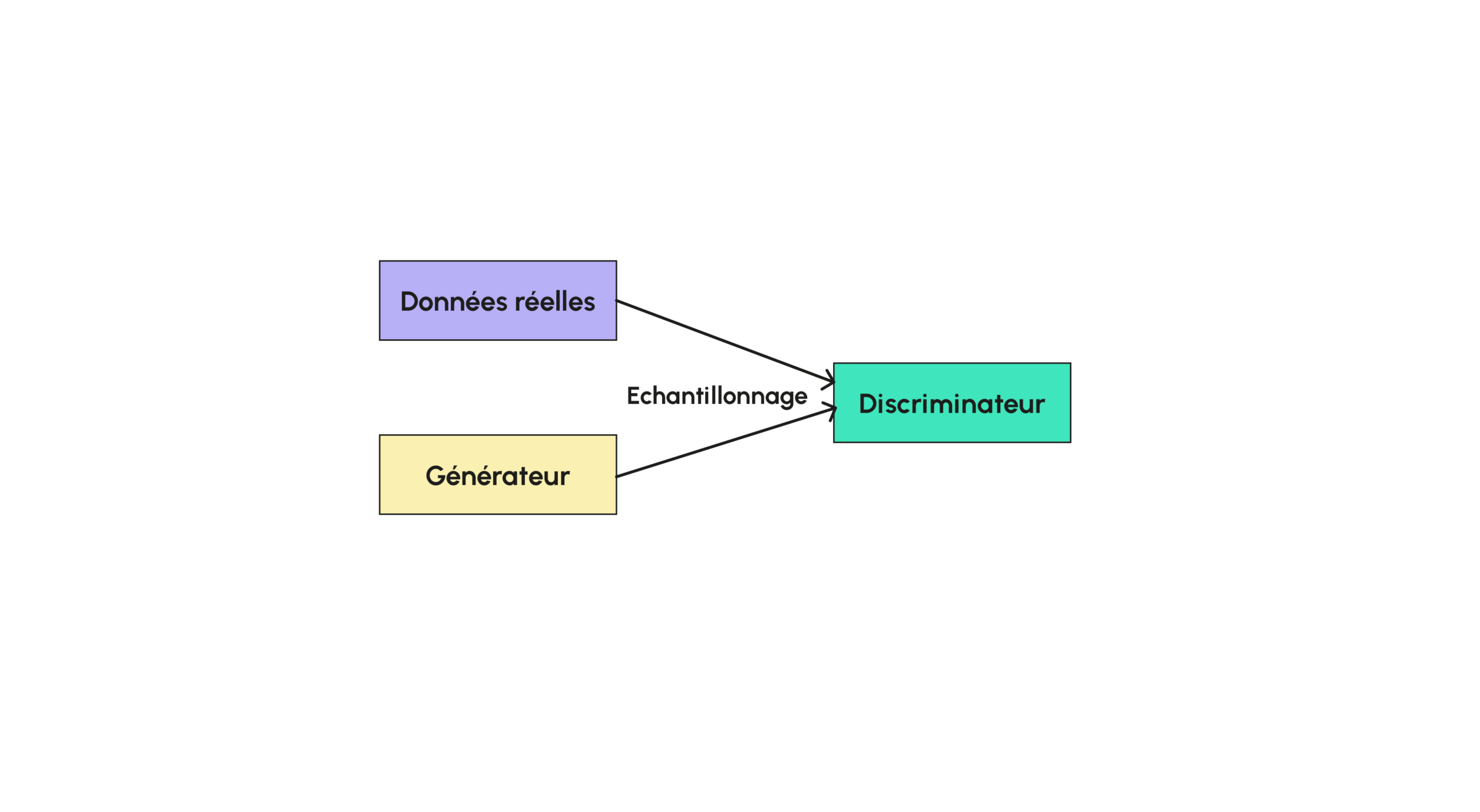
Der Generator ist das Modell, das es ermöglicht, Bilder aus einem zufälligen Rauschen zu erzeugen, während der Diskriminator (der einen Wert zwischen 0 und 1 annimmt) dazu dient, ein bestimmtes Bild zu klassifizieren, um festzustellen, ob es künstlich ist oder nicht.
Beim Training werden sowohl der Generator als auch der Diskriminator trainiert, damit der Diskriminator immer stärker wird, um ein echtes Bild von einem generierten Bild zu unterscheiden, und damit der Generator immer stärker wird, um den Diskriminator zu täuschen.
Während des Trainings hat der Generator keinen direkten Zugriff auf die realen Daten, nur der Generator nutzt sie, um sie mit den simulierten Daten zu vergleichen. Die Verlustfunktion für den Diskriminator sind die Fehler, die er bei der Klassifizierung der Daten macht, und die Verlustfunktion für den Generator ist der Erfolg des Diskriminators bei der Unterscheidung von echten Bildern. Einige Modelle verwenden die gleiche Verlustfunktion, die vom Diskriminator minimiert und vom Generator maximiert wird.
Die Struktur von CycleGAN ist so ausgelegt, dass der Generator G die Verteilung eines Stils X in einen anderen Stil Y übersetzt, so dass der Diskriminator den transformierten Stil Y=G(X) nicht vom ursprünglichen Stil Y unterscheiden kann.
Es gibt ein Problem, das bei der Anwendung dieser Strategie häufig auftritt: Der Generator übersetzt alle Bilder auf die gleiche Weise und kann nur ein einziges Beispiel b erzeugen, was nicht die gewünschte Aufgabe ist.
Um dieses Problem zu lösen, fügt die CycleGAN-Struktur eine Einschränkung hinzu, indem sie einen weiteren Generator F definiert, dessen Aufgabe es ist, die Rücktransformation von G in dem Sinne zu sein, dass FGX≈X. Dadurch wird sichergestellt, dass die Transformation von X nicht auf ein einziges Beispiel reduziert wird. Beim Training wird daher eine neue Verlustfunktion hinzugefügt, die den zyklischen Konsistenzverlust (cycle consistency loss) charakterisiert und Transformationen dazu ermutigt, die Eigenschaften FGX≈X und G(FY)≈Y zu überprüfen. Zusätzlich zum Diskriminator für G (den wir DY nennen, weil wir Y von Y diskriminieren wollen) fügen wir einen Diskriminator für F (den wir DX nennen) hinzu.
Unten ist ein ein Schema, das die verschiedenen oben beschriebenen Beziehungen zusammenfasst:
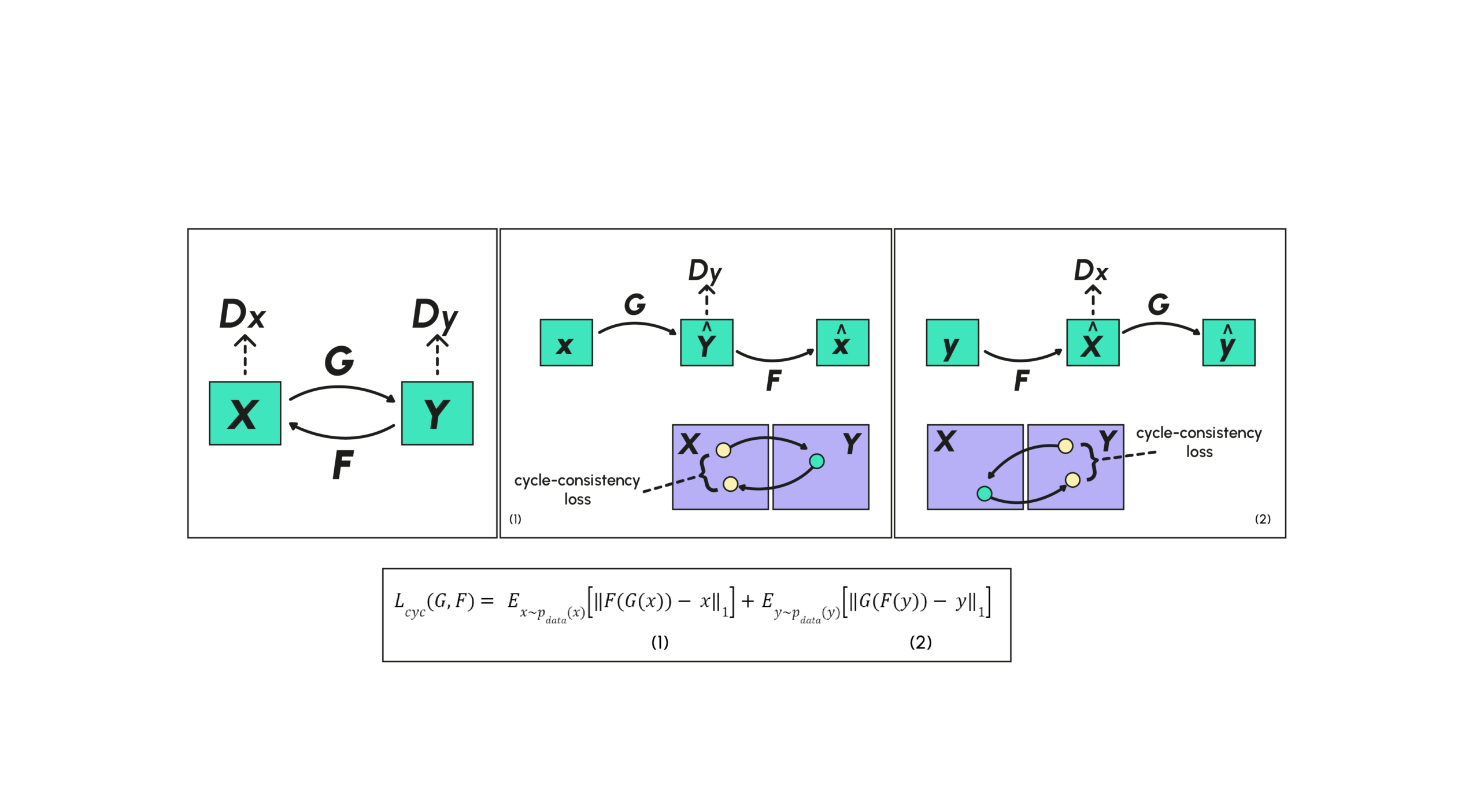
Der Cycle-Consistency-Loss wird dann in zwei verschiedene Stücke aufgeteilt, wobei das erste (1) dem Verlust zwischen den Elementen von X und ihren Rekonstruktionen entspricht und das zweite (2) dem Verlust zwischen den Elementen von Y und ihren Rekonstruktionen entspricht.
In diesem Modell optimieren die Generatoren und Diskriminatoren dieselbe allgemeine Verlustfunktion, die aus zwei Unterverlustfunktionen besteht, die den Generatoren zugeordnet sind (adversial loss):


und der zyklischen Konsistenzverlustfunktion:

die die Gesamtverlustfunktion angibt:

die von Diskriminatoren maximiert wird (damit diese gut zwischen Generation und realen Daten unterscheiden können) und von Generatoren minimiert wird, damit diese Beispiele erzeugen, die immer weniger von realen Daten unterschieden werden können.
Die Architektur von CycleGAN im Detail
Die beiden Generatoren und die beiden Diskriminatoren sind in der Architektur vollkommen identisch, d. h. sie bestehen aus den gleichen Schichten und haben die gleichen Abmessungen. Die Generatoren verwenden hauptsächlich Faltungsschichten und Restblöcke (residual blocks).
Die Faltungsschichten wurden bereits in einem anderen Artikel unseres Blogs ausführlich behandelt und erklärt, den du hier finden kannst. Residualblöcke sind sehr einfache Schichten im Deep Learning, die oft für die Stilübertragung verwendet werden.
(Auch interessant: Was sind Hugging Face Transformers?)
Sie sorgen dafür, dass sich das Bild nicht zu weit vom Originalbild entfernt, indem sie das Netzwerk nach und nach an das Original erinnern. Formal hat eine solche Schicht die Form :
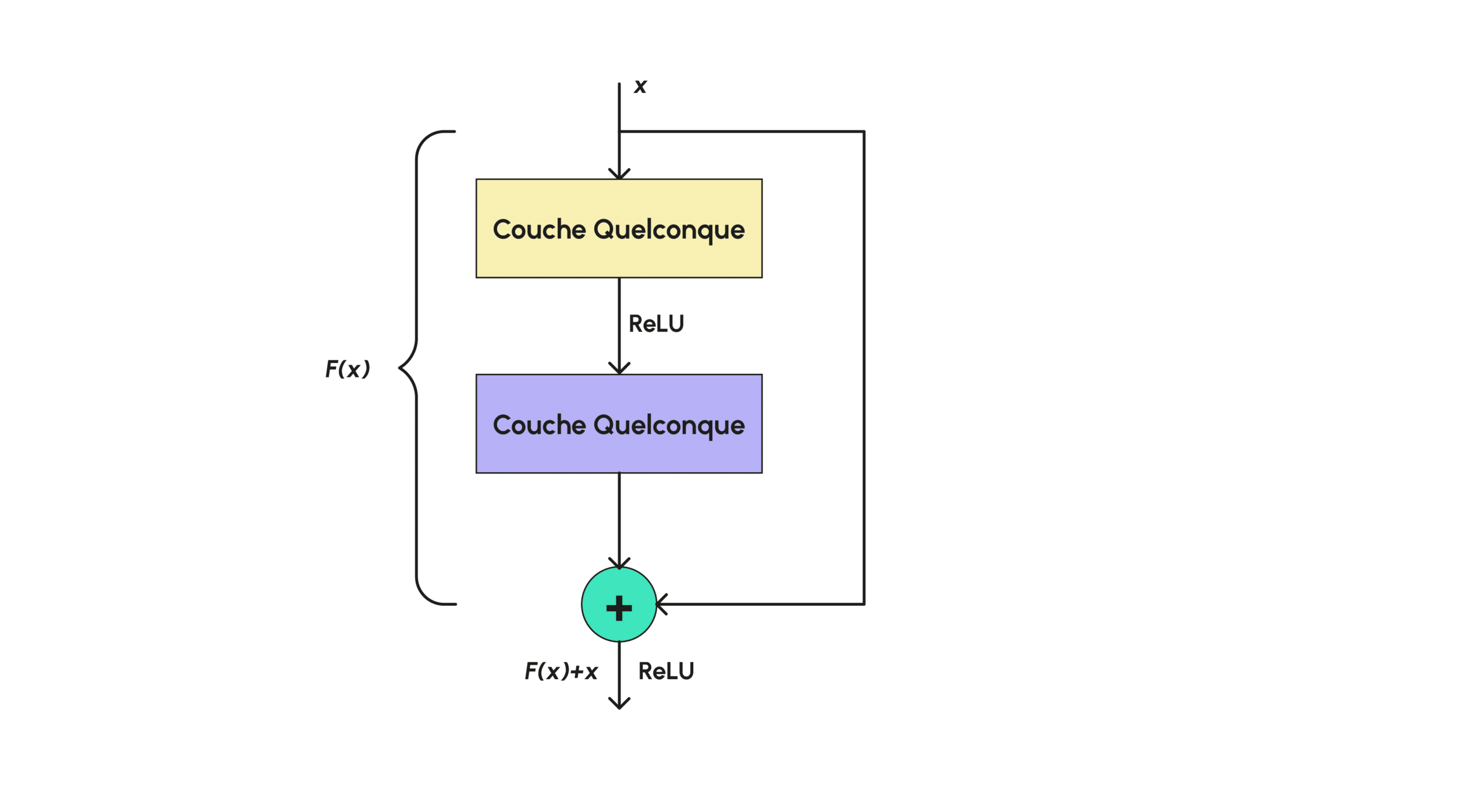
Wie in Grafik (d) dargestellt, besteht der Restblock nur aus einer normalen Ebene, die am Ende mit dem ursprünglichen Eingabewert versehen wird, so dass das Ausgangsbild buchstäblich nicht zu sehr verändert wird.
In einigen Fällen wird auch ein ReLU angewendet, um die Ausgabe des Layers zu annullieren, falls F(x) negativ zu hoch ist (wo ein Farbbild positive Werte hat). Für die Diskriminatoren verwendet das Modell 70 x 70 PatchGANs, d. h. der Diskriminator besteht aus mehreren kleinen GANs, PatchGANs mit einer Anfangsgröße von 70 x 70, die überall auf dem Bild angewendet werden und sich in dem betreffenden Teil des Bildes überlappen können, wodurch bestimmt wird, ob ein Teil des Bildes echt ist oder nicht. Die endgültige Antwort wird dann als der Durchschnitt der Antworten berechnet, die für jeden Patch zurückgegeben werden. Jeder PatchGAN wird eine ähnliche Architektur haben, die nur aus klassischen Faltungsschichten besteht. Schließlich wird das Training mit einer Batchgröße von 1 und einem klassischen Optimierer durchgeführt: Adam.

Hier werden einige Ergebnisse vorgestellt, die mit Testbildern durch das zuvor definierte Modell erzielt wurden. Links sind die als Input gelieferten Originalbilder und rechts die verklärten Bilder zu sehen. Man sieht z. B., dass das Modell, das mit Bildern von Pferden und Zebras trainiert wurde, frei zwischen den verschiedenen Tierstilen wechseln kann.
Ebenso kann es, wenn es mit Künstlerbildern trainiert wird, von einer Fotografie zu einem Gemälde im Stil von Van Gogh wechseln. Auch bei der Rekonstruktion von Bildern werden sehr gute Ergebnisse erzielt. Denn neben der fast identischen Rekonstruktion des Bildes kann man auch feststellen, dass die Qualität des rekonstruierten Bildes (mit einer besseren Tiefenschärfe) im Vergleich zum Basisbild verbessert ist:

In diesem Artikel haben wir gesehen, was Stilübertragung ist, und insbesondere die Architektur des CycleGAN-Modells, das von GANs inspiriert ist und eine effiziente Stilübertragung ermöglicht.
CycleGAN ist einer der besten Algorithmen für die Stilübertragung. Wir haben außerdem gesehen, dass dieser Algorithmus im Gegensatz zu fast allen anderen Algorithmen, die Stilübertragung ermöglichen, keine gepaarten Daten benötigt, die in der Praxis schwer zu erhalten sind, und es daher ermöglicht, verschiedene Datenbanken zu trainieren, die zuvor unbrauchbar waren, wie z. B. die Datenbanken der Gemälde berühmter Maler wie Van Gogh. Schließlich haben wir gesehen, dass dieses Modell nicht nur eine effiziente Stilübertragung, sondern auch eine getreue Bildrekonstruktion bietet, die zu einem Bild mit einer besseren Tiefenschärfe führt, was die Stabilität des Algorithmus beweist.
Dieser Algorithmus ist jedoch nicht allmächtig, denn er hat Schwächen, wenn es darum geht, die geometrischen Eigenschaften von Bildern zu verändern, wie z. B. wenn man eine Katze in einen Hund verwandeln möchte, und eignet sich daher nur für die Veränderung von Texturen.
Wenn du mehr über die Transformation von Objekten, Deep Learning und künstliche Intelligenz in Bezug auf Bilder erfahren möchtest, dann schau dir unsere Ausbildung zum Data Scientist an.







