
In diesem Artikel werden wir die grundlegenden Konzepte von ggplot erkunden und herausfinden, wie du mit dieser Bibliothek ein Diagramm erstellen kannst, um deine Daten effektiv zu präsentieren.
Was ist ggplot?
ggplot ist eine Bibliothek zur Datenvisualisierung in R, die 2005 von Hadley Wickham entwickelt wurde. Die Bibliothek basiert auf der Graphgrammatik, die es ermöglicht, Grafiken durch grundlegende Komponenten wie Achsen, Legenden oder Beschriftungen zu beschreiben.
So kann man mit ggplot einen Graphen als eine Reihe von Schichten betrachten, die übereinander gelegt werden, um den endgültigen Graphen zu erzeugen. Jede Grafikschicht kann mit der Funktion + hinzugefügt werden und kann Elemente wie Punkte, Linien, Balken, Punktwolken, Histogramme, Boxplots, Texte und vieles mehr enthalten.
Um ein Diagramm mithilfe des Ebenensystems auf ggplot zu erstellen, legst du zunächst die Daten und Variablen fest, die für die x- und y-Achse verwendet werden sollen, und fügst dann nach und nach weitere Diagrammschichten hinzu.
Eine der am häufigsten verwendeten Grafikschichten sind die Schichten für geometrische Funktionen mithilfe der entsprechenden geom_-Funktionen.
Hier sind einige Beispiele für Grafikschichten aus geometrischen Funktionen:
- geom_point(): fügt dem Graphen Punkte hinzu.
- geom_line(): fügt dem Graphen eine Linie hinzu.
- geom_bar(): fügt dem Graphen ein Balkendiagramm hinzu.
- geom_histogram(): fügt dem Diagramm ein Histogramm hinzu.
- geom_boxplot(): fügt dem Diagramm einen Boxplot hinzu.
- geom_text(): fügt dem Diagramm Text hinzu
💡Auch interessant:
| Data Engineer Skills |
| Data Loss Prevention |
| Data Warehouse |
| Data Science Bootcamp |
| Wie wird man Data Analyst |
Beachte, dass jede Diagrammebene mit Hilfe von funktionsspezifischen Optionen angepasst werden kann.
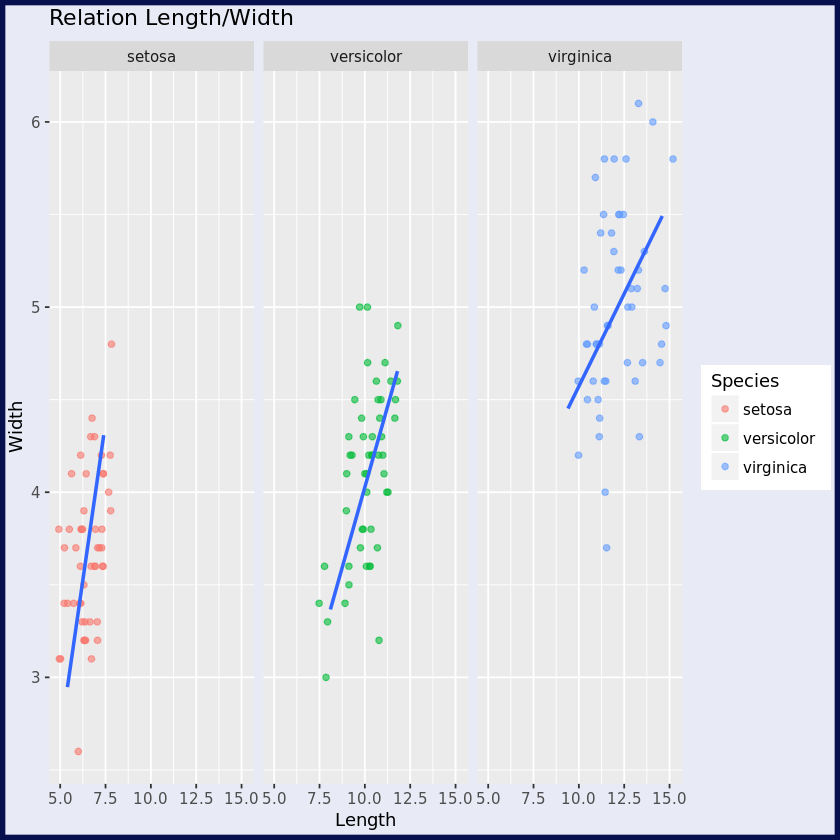
Um dieses Prinzip zu verstehen, sehen wir uns an, wie wir Schritt für Schritt das folgende Diagramm mit dem Iris-Datensatz erstellen.
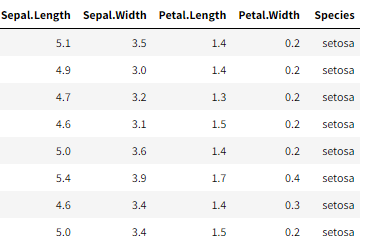
Hier ist ein Überblick über unsere Daten:
Schritt 1: Die ggplot-Bibliothek laden und die csv-Datei einlesen
library(ggplot2)
iris <- read.csv(„species.csv“)
Schritt 2: Erstelle das ggplot-Objekt
p = ggplot(iris, aes(x=Sepal.Length + Petal.Length, y = Sepal.Width + Petal.Width)) 
Diese Zeile erstellt ein ggplot-Grafikobjekt mit dem Namen p, das den Datensatz iris mit den Variablen Sepal.Length, Petal.Length, Sepal.Width und Petal.Width darstellt.
Die Werte von Sepal.Length und Petal.Length werden hinzugefügt, um die x-Achse zu erstellen, während die Werte von Sepal.Width und Petal.Width hinzugefügt werden, um die y-Achse zu erstellen.
Schritt 3: Erstellen einer Punktwolke
p = ggplot(iris, aes(x=Sepal.Length + Petal.Length, y = Sepal.Width + Petal.Width))
+ geom_jitter(aes(color = Species), alpha =0.6, width = 1)
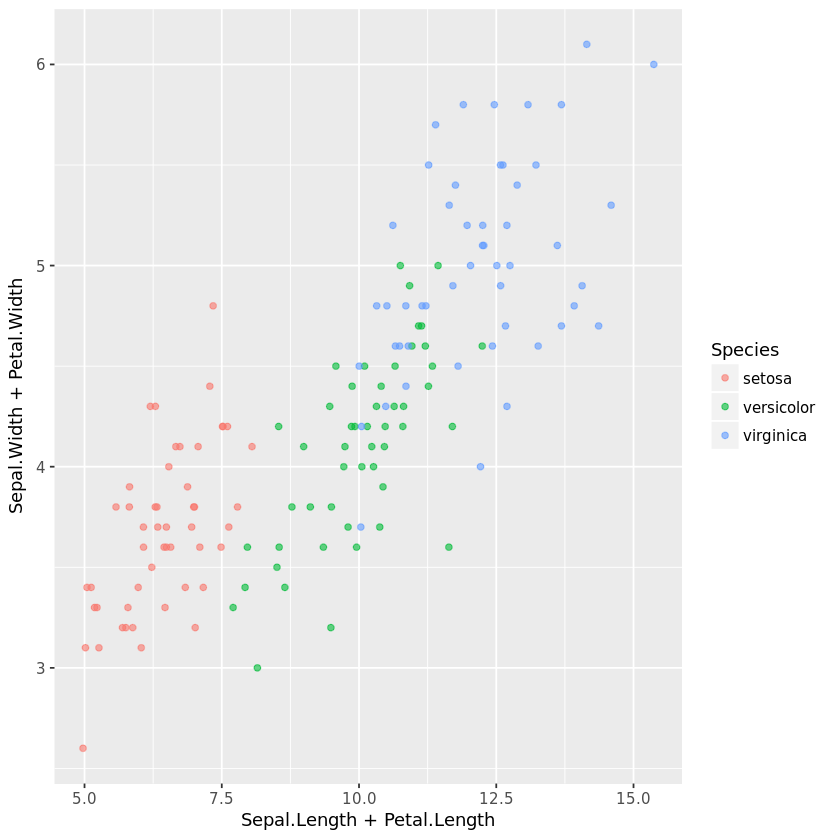
Diese Zeile fügt der Grafik eine Punktwolke (geom_jitter) hinzu. Die Punkte werden entsprechend der Variable Species eingefärbt und haben eine Transparenz von 0,6 und eine Breite von 1.
Schritt 4: Erstellen einer linearen Regression
p = ggplot(iris, aes(x=Sepal.Length + Petal.Length, y = Sepal.Width + Petal.Width)) + geom_jitter(aes(color = Species), alpha =0.6, width = 1)
+ geom_smooth(method=’lm‘, se = FALSE)
Auch interessant: Logistische Regression
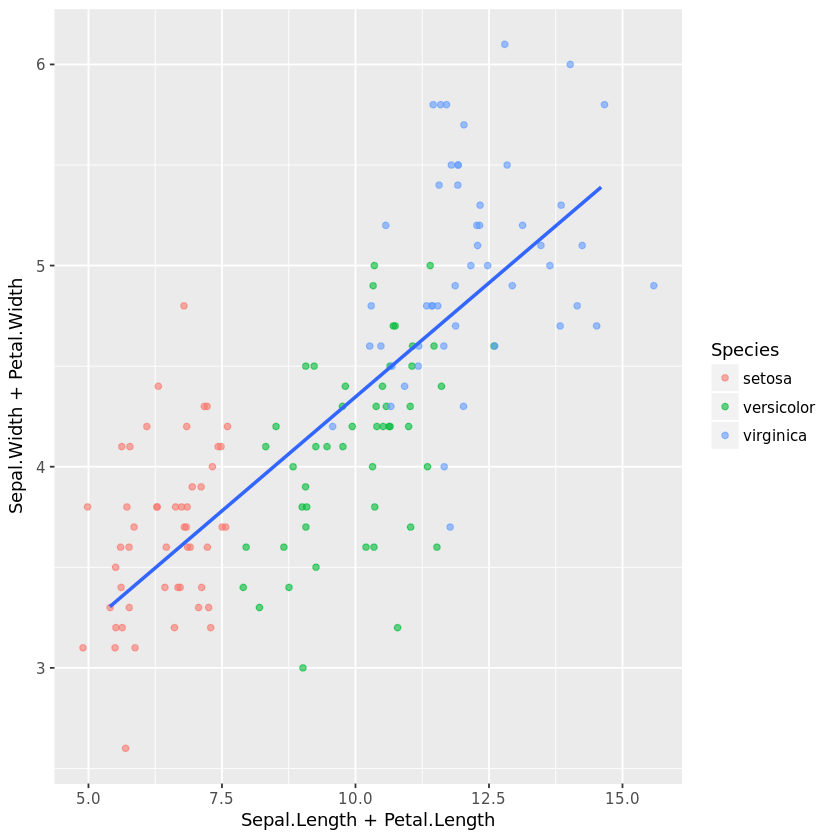
Diese Zeile fügt der Grafik eine Ebene mit einer Regressionsgeraden (geom_smooth) hinzu. Die verwendete Modellierungsmethode ist die lineare Regression (method=’lm‘). Die Option se = FALSE wird verwendet, um die Konfidenzintervalle nicht anzuzeigen.
5. Schritt: Trenne die Grafik in Unterteile
p = ggplot(iris, aes(x=Sepal.Length + Petal.Length, y = Sepal.Width + Petal.Width))
+ geom_jitter(aes(color = Species), alpha =0.6, width = 1)
+ geom_smooth(method='lm', se = FALSE)
+ facet_wrap(~Species)
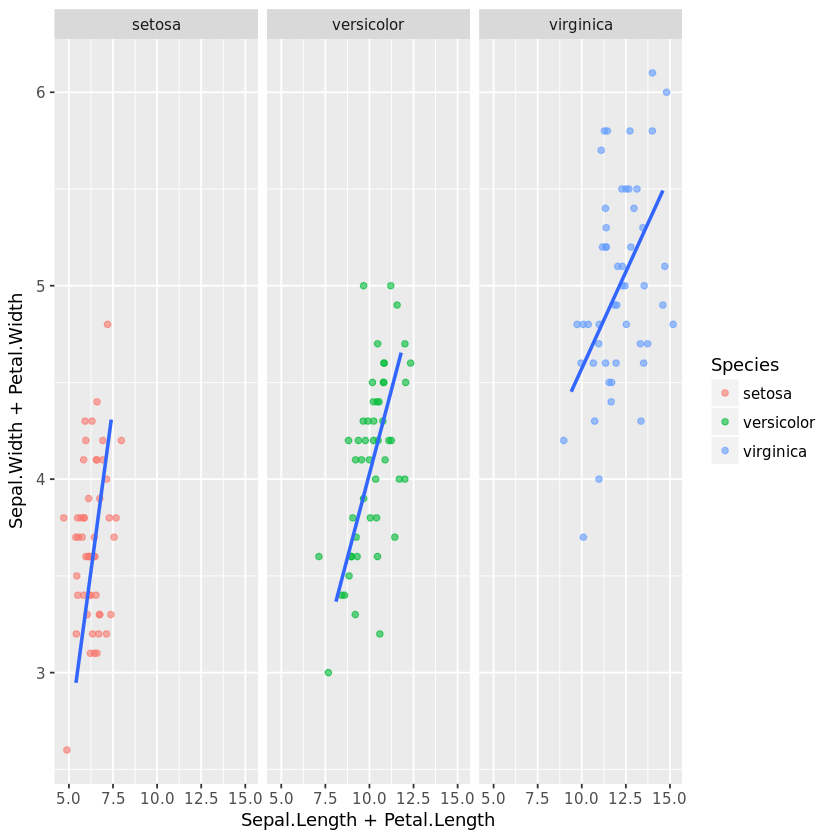
Diese Linie unterteilt das Diagramm in Panels (facet_wrap) entsprechend der Variablen Species. Dies ermöglicht es, die Beziehung zwischen den Variablen für jede Art separat zu sehen.
Schritt 6: Hinzufügen von Etiketten
p = ggplot(iris, aes(x=Sepal.Length + Petal.Length, y = Sepal.Width + Petal.Width)) + geom_jitter(aes(color = Species), alpha =0.6, width = 1)
+ geom_smooth(method='lm', se = FALSE)
+ facet_wrap(~Species)
+ labs(title = "Relation Length/Width", x= "Length", y= "Width")
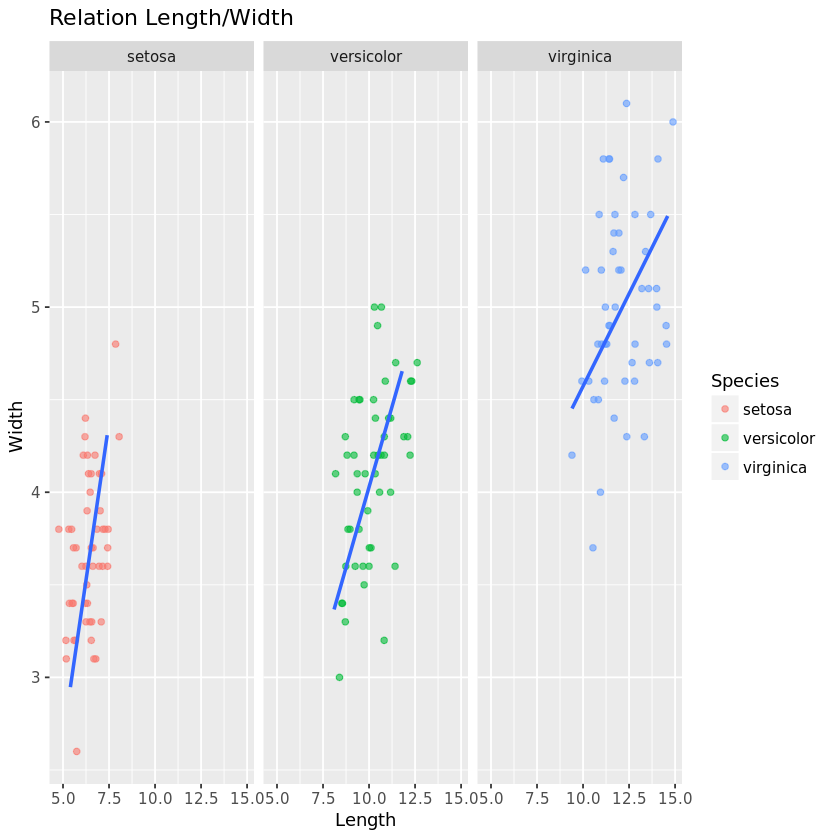
Diese Zeile fügt dem Diagramm Titel- und Achsenbeschriftungen hinzu. Der Titel lautet „Relation Length/Width“, die x-Achse wird mit „Length“ und die y-Achse mit „Width“ beschriftet.
Schritt 7: Hinzufügen des Themas
p = ggplot(iris, aes(x=Sepal.Length + Petal.Length, y = Sepal.Width + Petal.Width))
+ geom_jitter(aes(color = Species), alpha =0.6, width = 1)
+ geom_smooth(method='lm', se = FALSE)
+ facet_wrap(~Species)
+ labs(title = "Relation Length/Width", x= "Length", y= "Width")
+ theme(plot.background = element_rect(fill = '#E8EAF6', color = "#08104E", size = 3))
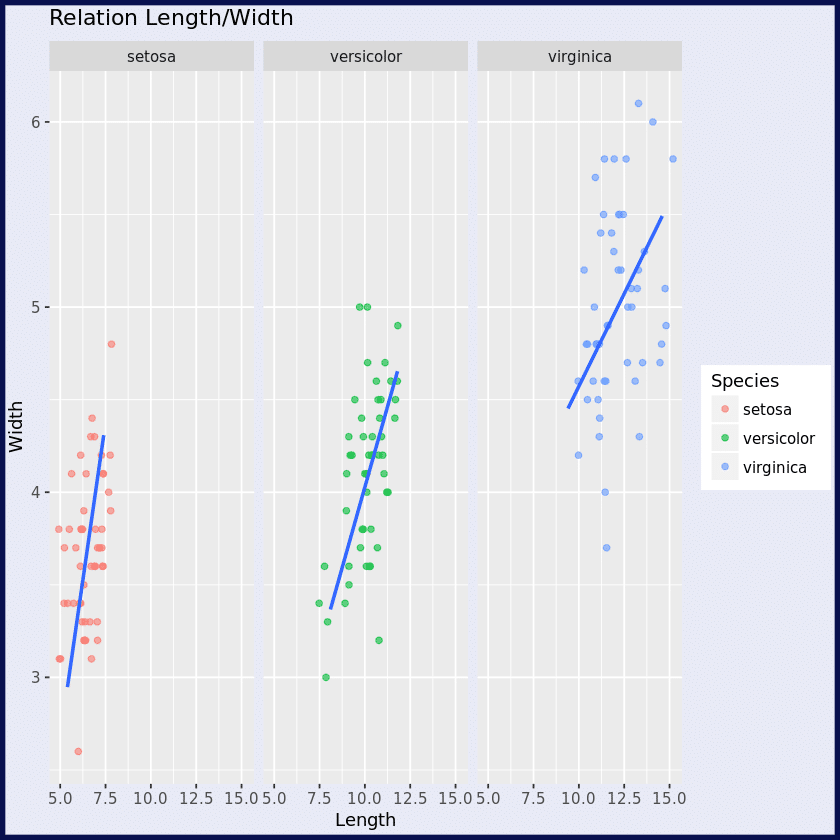
Diese Zeile legt mithilfe der Funktion theme() ein benutzerdefiniertes Thema für die Grafik fest. Das Argument plot.background wird verwendet, um den Hintergrund der Grafik festzulegen. Die Funktion element_rect() wird verwendet, um ein Rechteck mit einer Füllfarbe von ‚#E8EAF6‘, einem Rand in der Farbe „#08104E“ und einer Dicke von 3 Pixel zu erstellen.
Dieser Code erstellt eine 7-stufige ggplot-Grafik, die das Verhältnis zwischen der Länge und Breite der Kelch- und Blütenblätter für die verschiedenen Arten von Irisblumen zeigt. Die Punkte werden entsprechend der Art eingefärbt und eine lineare Regression wird für jede Art angepasst.
💡Auch interessant:
| Imageio Python Bibliothek |
| PySpark Python Bibliothek |
| Folium Open Source Bibliothek von Python |
| Top 10 Python Bibliotheken |
Was ist von ggplot zu halten?
ggplot ist eine Bibliothek für die Datenvisualisierung in R. Dank des flexiblen Layersystems können wir individuelle und komplexe Grafiken erstellen, indem wir nach und nach zusätzliche Grafikkomponenten hinzufügen.
Wenn du dich für die Datenvisualisierung interessierst, kannst du dich gerne unserem Data Analyst-Kurs anschließen!







