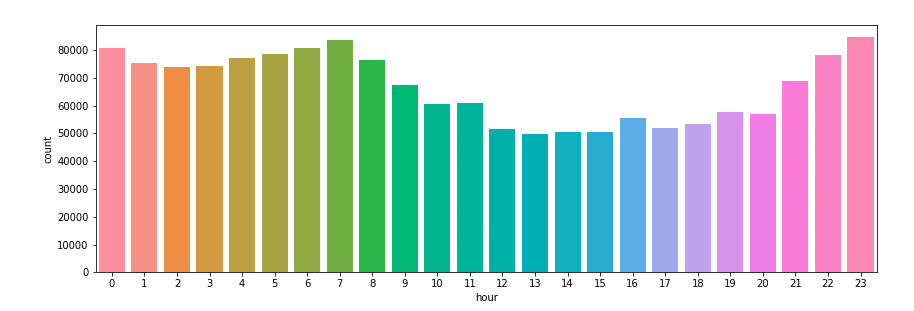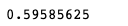NLP Twitter: Heute wird Twitter von Hunderten Millionen Menschen auf der ganzen Welt genutzt. Genauer gesagt, beläuft sich die aktuelle Schätzung auf etwa 330 Millionen monatlich aktive Nutzer und 145 Millionen täglich aktive Twitterer. Eine weitere interessante Zahl: 63 % der weltweiten Twitter-Nutzer sind zwischen 35 und 65 Jahre alt.
Das Ziel dieses Artikels ist es, eine explorative und visuelle Analyse der in unserem Datensatz vorhandenen Tweets durchzuführen. In einem zweiten Schritt soll mithilfe verschiedener Modelle in Python die Stimmung in den Tweets als positiv, neutral oder negativ klassifiziert werden. Mit anderen Worten: Sentiment Analysis und NLP zusammenzubringen.
Zunächst ein erster Blick auf den Datensatz, der uns zur Verfügung steht: Lade den Datensatz herunter, den du mit dem Befehl df.head() erhalten hast.
Wie wir sehen können, enthält dieser Datensatz, der insgesamt 1,6 Millionen Tweets enthält, eine Spalte mit dem Titel Label, die eine 1 für eine positive Stimmung und eine -1 für eine negative Stimmung vergibt.
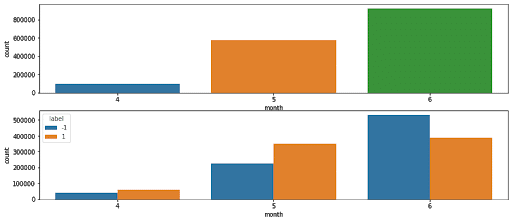
In einem ersten Schritt werden wir versuchen, den Monat zu bestimmen, in dem die Twittersphäre am aktivsten ist.
Hier lässt sich ein erster Trend erkennen:
Die Monate Mai (5) und Juni (6) scheinen die Monate zu sein, in denen am meisten getwittert wird. Dies könnte verschiedene Gründe haben, z. B. die Tatsache, dass Twitter vor allem für junge Leute gedacht ist und dass die Monate Mai und Juni das Ende ihres Schul- oder Studienjahres darstellen, sodass sie sich auf Twitter mehr ausdrücken können. Es fällt auch auf, dass im Juni die Stimmung in den Tweets eher negativ ist (mit -1 gekennzeichnet), was die vorgefasste Meinung bestätigt, dass Twitter manchmal ein Ort ist, an dem sich die Gewalt entlädt.
Wir könnten uns nun fragen, an welchem Wochentag die meisten Tweets geschrieben werden:
Hier stellen wir wenig überraschend fest, dass Twitterer am Wochenende viel häufiger twittern als unter der Woche.
Wir können uns auch ansehen, zu welcher Tageszeit die meisten Tweets abgesetzt werden und stellen ebenfalls wenig überraschend fest, dass die Zahl der Tweets vor allem vor und nach Beginn und Ende des Arbeits-/Schultages explodiert:
Hier ist eine Wortwolke, in der du sehen kannst, welche Wörter in den Tweets der Nutzer am häufigsten verwendet werden (je größer die Schriftgröße eines Wortes ist, desto häufiger kommt es vor).
Von nun an beginnen wir mit unserer Arbeit, die Gefühle von Tweets mithilfe einer logistischen Regression zu klassifizieren.
Dazu teilen wir unseren Datensatz wie üblich in eine Trainingsstichprobe (80 %), in der wir die Parameter des Modells lernen, und eine Teststichprobe (20 %), in der wir sie testen.
Da die erklärenden Variablen jedoch Textdaten (die Tweets) sind, werden wir vorher neue numerische erklärende Variablen in Verbindung mit den Tweets (Metadaten) erstellen, um dann die Labels vorhersagen zu können.
ERSTELLUNG VON METADATEN UND KLASSIFIZIERUNG
Um die Stimmung eines Tweets zu analysieren, können wir dann die Dinge herausfiltern, die uns wichtig erscheinen, wie z. B. :
Die Anzahl der „http(s)“- oder „www.“-Links.
Die Anzahl der E-Mail-Adressen. (Die Anzahl der E-Mail-Adressen, die im Tweet genannt werden, könnte für die Seriosität des Tweets von Bedeutung sein).
Die Anzahl der Hashtags.
Die Anzahl der Zitate von Nutzern.
Die Anzahl der Großbuchstaben
Die Anzahl der Ausrufezeichen.
Die Anzahl der Ausrufezeichen-Strings.
Die Anzahl der Fragezeichen.
Die Anzahl der Fragezeichen-Strings.
Die Anzahl der Punkte usw. (…).
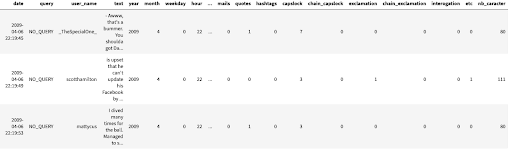
Hier ist eine neue Vorschau unseres Datensatzes nach der Erstellung der Metadaten :
Durch Gruppieren und Summieren jeder Spalte in diesem neuen Datensatz nach dem Label…
… Stellen wir fest, dass ein Tweet, der aus Links oder E-Mail-Adressen besteht, tendenziell viel positiver ist.
Da die erklärenden Variablen nun bereit sind, verwendet zu werden, müssen wir nur noch unser logistisches Regressionsmodell laufen lassen, um die positiven und negativen Gefühle der Tweets zu klassifizieren.
Hier ist der Vorhersagewert, den das Modell erzielt hat:
Das Ergebnis ist ein Vorhersagewert von ca. 60 %, was nicht besonders gut ist. Um diesen Wert zu verbessern, könnte man eine Bag-of-Words-Darstellung jedes Wortes in den Tweets verwenden, die den Text einfach als Vektor darstellt, der von einem Machine-Learning-Algorithmus verarbeitet werden kann.
ALTERNATIVE LÖSUNG: AFINN
Eine andere Möglichkeit, die Stimmung eines Tweets zu klassifizieren, ist die Verwendung von in Python verfügbaren Bibliotheken wie Afinn.
Das AFINN-Lexikon ist eine Liste englischer Begriffe, deren aktuelle Version mehr als 3.300 Wörter enthält. Jedes Wort ist mit einem Sentiment-Score verknüpft, den wir mit der Methode score der Klasse Afinn erhalten können.
Der Afinn-Score ist eine kategoriale Variable, für die folgende Interpretationsregel gilt:
Negatives Gefühl: Afinn-Score < 0
Neutrales Gefühl: Afinn-Score == 0
Positive Stimmung: Afinn-Score > 0
Wenden wir nun die Afinn-Funktion auf unseren Datensatz an:
Wie du sehen kannst, ist Afinn besonders leistungsstark und hat die beiden oben genannten Tweets kategorisch als negativ eingestuft.
Fazit:
Wie du sehen kannst, ist Afinn besonders effizient und hat die beiden oben genannten Tweets kategorisch als negativ eingestuft.
Diese NLP Twitter-Stimmungsanalyse könnte mehrere Anwendungsbereiche haben, von denen wir hier einige spezifische Beispiele nennen:
Überwachung der sozialen Medien: Das Aufspüren von Tweets mit negativen Gefühlen könnte dazu beitragen, die Belästigungen und den Gewaltausbruch, die auf Twitter stattfinden, zu reduzieren.
Politische Kampagnen: Die Analyse von Twitter-Stimmungen könnte es ermöglichen, die Popularität eines politischen Kandidaten zu analysieren und so z. B. den Gewinner einer Präsidentschaftswahl vorherzusagen.
Kundenbindung: Mithilfe der Twitter-Stimmungsanalyse kann man verfolgen, was über ein Produkt oder eine Dienstleistung eines Unternehmens gesagt wird, und kann so helfen, verärgerte Kunden zu erkennen.
Wenn dir dieser Artikel gefallen hat, melde dich für unseren Newsletter an, um unsere Artikel als Erste zu erhalten!
Melde Dich jetzt für unseren Newsletter an, um unsere Guides, Tutorials und die neuesten Entwicklungen im Bereich Data Science direkt per E-Mail zu erhalten.