PowerApps: Alles über die Plattform zur Entwicklung von mobilen Apps

Seit dem Beginn des Smartphone-Zeitalters haben mobile Apps eine große Bedeutung im Alltag erlangt. Um die Kreativität von Entwicklern zu entfesseln, bietet Microsoft seit 2017 PowerApps an. Was ist PowerApps? Diese Plattform zur Entwicklung von Mobil- und Webanwendungen ermöglicht es Bürgerentwicklern“, von Fähigkeiten zu profitieren, die früher nur High-End-Entwicklungswerkzeugen vorbehalten waren. Die mit PowerApps erstellten […]
Power BI Drillthrough: Wie nutzt man diese Funktion?

Die Drillthrough-Funktion von Power BI ermöglicht es, eine Seite für eine bestimmte Einheit in einen Bericht einzufügen, um ihr die tieferen Datenvisualisierungen zu präsentieren. Hier erfährst du alles, was du über dieses nützliche Tool wissen musst und wie du einen Kurs belegen kannst, um Power BI vollständig zu beherrschen. Power BI ist eine Software von […]
Big Data Weiterbildung: Alles, was du wissen musst
Eine Big Data Weiterbildung vermittelt dir die Fähigkeiten, um die Berufe im Bereich Big Data auszuüben: Data Analyst, Data Scientist oder auch Data Engineer. Finde heraus, warum und wie du ein Profi in Sachen Data Science werden kannst. Dank Smartphones, sozialen Netzwerken, vernetzten Objekten und E-Commerce-Shops stehen den Unternehmen riesige Datenmengen zur Verfügung. Das ist […]
Data Architecture: Definition und Bedeutung in der Datenwissenschaft

Data Architecture umfasst alle Vorgehensweisen und Regeln eines Unternehmens rund um die Nutzung von Daten. Hier erfährst du alles, was du darüber wissen musst: Definition, Prinzipien, Frameworks, Schulungen. Wenn in der Vergangenheit ein Entscheidungsträger in einem Unternehmen auf Daten zugreifen wollte, musste er die IT-Abteilung um Hilfe bitten. Die IT-Abteilung musste dann ein maßgeschneidertes System […]
Tools im Alltag eines Data Engineers

Im Zeitalter von Big Data haben sich mehrere Berufe herausgebildet, darunter auch der des Data Engineers. Wenn du diesen Beruf noch nicht kennst, empfehle ich dir, diesen Artikel zuerst zu lesen. Für diejenigen, die wissen, was ein Data Engineer macht, werden wir uns mit den Werkzeugen beschäftigen, die er benutzt. Lass uns von diesem Schema […]
NLP Schulung: Wie werde ich Experte in der Verarbeitung natürlicher Sprache?

Eine NLP-Ausbildung ermöglicht es dir, in den Bereichen KI und Data Science zu arbeiten. Hier erfährst du alles, was du über Natürliche Sprachverarbeitung wissen musst, und wie du dich zu einem Profi ausbilden lassen kannst. In den letzten Jahren hat sich die künstliche Intelligenz stark weiterentwickelt. Einige Bereiche der KI sind besonders stark gewachsen, z. […]
Data Mining: Wie werde ich Experte ?

Eine Weiterbildung in Data Mining vermittelt Fähigkeiten, die in Unternehmen sehr gefragt sind, um den vollen Wert von Daten zu erschließen. Finde heraus, warum und wie du dieses Fachwissen entwickeln kannst. Dank der neuen digitalen Technologien verfügen die Unternehmen über große Datenmengen. 5G, das Internet der Dinge und soziale Netzwerke generieren riesige Mengen an Informationen. […]
Hadoop vs. Spark Training: Wie lerne ich den Umgang mit Big Data Tools?

Hadoop vs. Spark: Eine Hadoop- und Spark-Schulung wird dich zu einem Profi in Sachen Data Science machen. Erfahre, warum und wie du diese Werkzeuge zur Verarbeitung von Big Data beherrschen kannst. Die Verarbeitung von Big Data erfordert neue Werkzeuge, die große Datenmengen verarbeiten können. Zu den wichtigsten Programmen, die von Data Scientists oder Data Engineers […]
Data Governance: Bilde dich weiter und bleibe am Puls der Zeit

Es werden immer mehr Schulungen im Bereich Data Governance angeboten. Aber kannst du dich darauf verlassen, dass diese Kurse dir dabei helfen, das Datenmanagement in deinem Unternehmen zu revolutionieren? Lass uns einen Blick auf die Auswahl dieser neuen Art von Ausbildung werfen. Eine wachsende Zahl von Unternehmen überdenkt ihre Datennutzung durch die Einführung einer Data […]
Spark Python API: So verwendest du sie

Spark Python API: PySpark ist eine API in der Programmiersprache Python für die Datenverarbeitungsmaschine Apache Spark. Hier erfährst du, warum du lernen solltest, dieses Tool zu verwenden, und wie du eine PySpark-Schulung absolvieren kannst. Datenwissenschaft und Machine Learning eröffnen neue Möglichkeiten. Diese Disziplinen erfordern jedoch Werkzeuge, die in der Lage sind, große Mengen an Big […]
Expected Goals: Die Mathematik dahinter verstehen
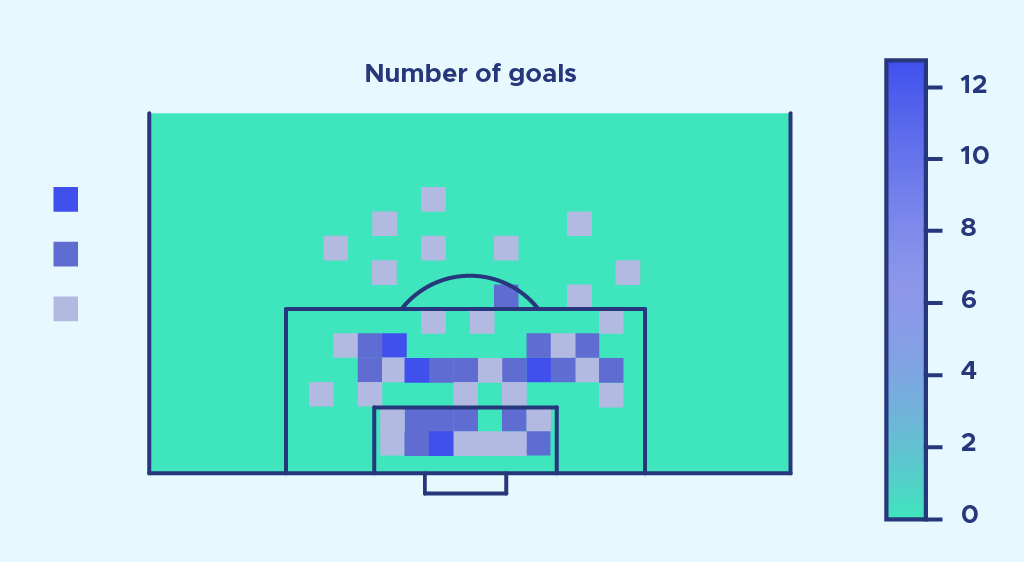
Die Anzahl der „expected goals“ ist ein neuer Leistungsindikator, der erst vor kurzem in der Fußballanalyse aufgetaucht ist. Diese Statistik wird immer häufiger verwendet, um die Physiognomie eines Spiels zu interpretieren, aber wissen wir wirklich, wie sie zu interpretieren ist? Dieser Artikel soll dir so einfach wie möglich die mathematischen Konzepte hinter den expected goals […]
Machine Learning Engineer Bootcamp: Dein Karrieresprung
In einem früheren Artikel haben wir gezeigt, wie unentbehrlich der Machine Learning Engineer für Unternehmen ist, so sehr, dass die Zahl der Stellenangebote zwischen 2012 und 2019 um das Zehnfache gestiegen ist. In diesem Artikel werden wir darüber sprechen, warum es sich lohnt, sich für ein Bootcamp zu entscheiden, um Machine Learning Engineer zu werden. […]
