In seinem im März 2021 veröffentlichten Forschungsartikel beschreibt Yann LeCun, Vizepräsident und leitender Wissenschaftler für künstliche Intelligenz bei Facebook, selbstgesteuertes Lernen als "eine der vielversprechendsten Möglichkeiten, Maschinen mit Grundwissen oder 'gesundem Menschenverstand' zu bauen, um Aufgaben anzugehen, die weit über die Fähigkeiten der heutigen KI hinausgehen".
Diese Methode, die als „dunkle Materie der Intelligenz“ bezeichnet wird, etikettiert Daten automatisch. Daher scheint sie in einer Zeit, in der es teuer ist, gekennzeichnete Daten zu haben, sehr vielversprechend zu sein.
Wie funktioniert Self Supervised Learning?
Selbstüberwachtes Lernen basiert auf einem künstlichen neuronalen Netz und kann als Mittelweg zwischen überwachtem und unüberwachtem Lernen angesehen werden. Es hat den großen Vorteil, dass es ungelabelte Daten verarbeitet und die zugehörigen Labels automatisch und ohne menschliches Zutun generiert. Diese Methode funktioniert, indem ein Teil der Lerndaten verborgen wird und das Modell trainiert wird, diese verborgenen Daten zu identifizieren.
Diese Identifizierung erfolgt durch die Analyse der Struktur und der Merkmale der Daten, die nicht ausgeblendet wurden. Diese gelabelten Daten werden dann für den Schritt des überwachten Lernens verwendet.
Was sind ihre Unterschiede zum beaufsichtigten und unbeaufsichtigten Lernen und ihre Vorteile?
Überwachte Lernmethoden haben vordefinierte Labels. Häufig wurden diese Labels durch menschliches Eingreifen vergeben.
Diese Arbeit ist jedoch oft sehr zeitaufwendig und kostspielig, weshalb gelabelte Daten selten sind. Außerdem benötigen maschinelle Lernalgorithmen oft eine große Menge an Daten, um genaue Ergebnisse zu liefern.
In manchen Bereichen, wie z. B. der Medizin, erfordert diese Etikettierungsarbeit spezielle Kenntnisse, was die Aufgabe noch komplexer macht. Das Self Supervised Learning bietet eine Alternative zu dieser überflüssigen Arbeit und steht damit an der Spitze des Feldes.
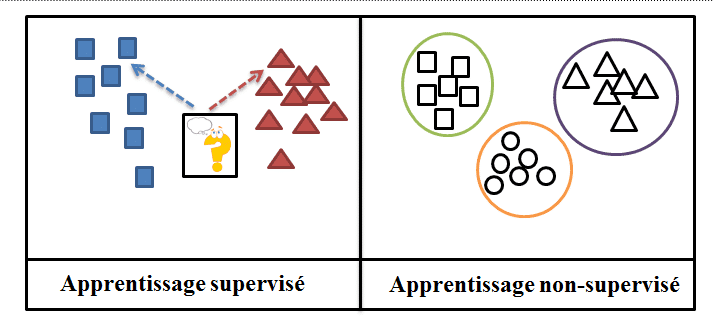
Es gibt auch andere Methoden, um das Problem der Datenbeschriftung zu umgehen, insbesondere das halbüberwachte Lernen, das hauptsächlich mit nicht beschrifteten Daten arbeitet, zu denen ein kleiner Teil beschrifteter Daten hinzukommt.
Self Supervised Learning kann als eine Unterkategorie des unüberwachten Lernens angesehen werden, da beide Ansätze mit nicht gekennzeichneten Datensätzen arbeiten.
Allerdings unterscheidet sich das unüberwachte Lernen in seinem Ziel, es konzentriert sich ausschließlich auf die Gruppierung der Daten und die Reduzierung der Dimensionen. Im Gegensatz dazu ist das Endziel des selbstüberwachten Lernens die Vorhersage einer klassifizierten Ausgabe.
Ein weiterer Vorteil des Self Supervised Learning liegt in einem tieferen Verständnis der Daten und der Muster und Strukturen, aus denen sie bestehen. Die gelernten Darstellungen lassen sich dadurch leicht verallgemeinern.
Selbstüberwachtes Lernen in der natürlichen Sprachverarbeitung
Beim Natural Language Processing (NLP) wird selbstgesteuertes Lernen verwendet, indem das Modell mit Sätzen trainiert wird, aus denen zufällig Wörter entfernt wurden. Das Modell muss dann die entfernten Wörter vorhersagen. Diese Methode hat sich bei der Anwendung auf NLP als effektiv und sehr relevant erwiesen.
Die Modelle wav2vec und BERT, die von Facebook bzw. Google AI entwickelt wurden, gehören beispielsweise zu den revolutionärsten NLP-Modellen. Wav2vec hat sich im Bereich der Spracherkennung oder Automatic Speech Recognition (ASR) bewährt.
Dabei werden bestimmte Teile des Audios ausgeblendet und das Modell wird darauf trainiert, diese Teile vorherzusagen. BERT, ein Akronym für Bidirectional Encoder Representations from Transformers, ist ein Deep-Learning-Modell, das derzeit die besten Ergebnisse für die meisten NLP-Aufgaben liefert.
Im Gegensatz zu den vor ihm etablierten Modellen, die den Text eindimensional durchlaufen, um das nächste Wort vorherzusagen, versteckt der BERT-Algorithmus zufällig Wörter im Satz und versucht, sie vorherzusagen. Dazu nutzt er den kompletten Kontext des Satzes, links und rechts.
Von NLP zu Computer Vision
Nachdem es sich in der natürlichen Sprachverarbeitung bewährt hat, hat sich das selbstüberwachte Lernen auch in der Computer Vision durchgesetzt. Facebook AI hat ein neues Modell vorgestellt, das auf selbstüberwachtem Lernen basiert und auf Computer Vision angewendet wird, das SEER (für SElf-supERvised) genannt wird. Es wurde mit einer Milliarde nicht gekennzeichneter Bilder aus Instagram trainiert. Das Modell erreichte eine Rekordgenauigkeit von 84,2 % in der ImageNet-Bilddatenbank.
In der Computer Vision war das selbstüberwachende Lernen auch weitgehend nützlich für das Einfärben von Bildern, die 3D-Rotation und das Ausfüllen von Kontexten.
Wo liegen die Grenzen des selbstgesteuerten Lernens/ Self Supervised Learning?
Die Modellbildung kann rechenintensiver sein. Da das selbstüberwachende Lernen die den Daten zugeordneten Labels selbstständig generiert, wird im Vergleich zu einem Lernmodell mit Labels zusätzliche Rechenzeit benötigt.
Das selbstgesteuerte Lernen ist nützlich, wenn wir einen Satz nicht gekennzeichneter Daten haben und diese manuell zuordnen müssen. Diese Methode kann jedoch Fehler bei der Beschriftung verursachen, die zu ungenauen Ergebnissen führen.
Fazit zum Self Supervised Learning
Self Supervised Learning ist ein weiterer Schritt auf dem Weg zu einer künstlichen Intelligenz mit „gesundem Menschenverstand“. Durch die Arbeit mit ungetaggten Daten löst diese Methode die langwierige und mühsame Aufgabe, Daten zu taggen. Sie eröffnet revolutionäre neue Ansätze in vielen Bereichen der künstlichen Intelligenz, wie NLP oder Computer Vision.
Wenn du mehr über Machine Learning und Deep Learning Algorithmen erfahren möchtest, kannst du dir unser Angebot an Schulungen für Datenberufe ansehen.