Was die Zukunftsaussichten betrifft, so richten sich viele Hoffnungen auf das unüberwachte Lernen zur Verbesserung der Cybersicherheit oder zur Identifizierung verschiedener Krankheiten.
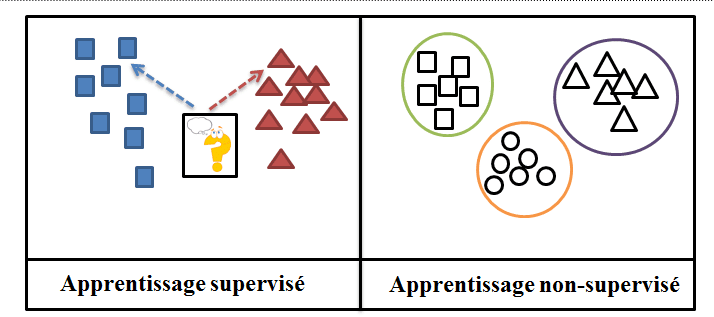
Im Gegensatz zum überwachten Lernen muss der Algorithmus beim unüberwachten Lernen mit nicht annotierten Beispielen arbeiten. In diesem Fall erfolgt das Lernen durch die Maschine völlig unabhängig. Die Maschine wird mit Daten gefüttert, ohne dass ihr Beispiele für Ergebnisse zur Verfügung gestellt werden.
In dieser Lernsituation sind die Antworten, die wir finden wollen, nicht in den bereitgestellten Daten enthalten: Der Algorithmus verwendet nicht gekennzeichnete Daten. Daher wird von der Maschine erwartet, dass sie die Antworten durch verschiedene Analysen und das Ordnen der Daten selbst erstellt.
Unüberwachte Lernmodelle werden insbesondere für :
- Die Klassifizierung der Daten
- Die annähernde Berechnung der Verteilungsdichte
- Die Reduzierung der Dimensionen.
In diesem Rahmen wird die Gesamtheit der gesammelten Daten wie Zufallsvariablen behandelt. Im Gegensatz zum maschinellen Lernen, das ein Modell aus gelabelten Daten finden muss: f(X) Y, werden hier nur ungelabelte Daten verwendet: Es gibt keine Variable Y, die vorhergesagt werden muss.
Die Verwendung des nicht überwachten Lernens kann in Cluster- und Assoziationsproblemen zusammengefasst werden.
Clustering
Ein Clustering-Problem ist ein Problem, bei dem von einer Maschine erwartet wird, dass sie Objekte, die in Datengruppen vorhanden sind, in Gruppen zusammenfasst (Clustering), und zwar auf möglichst faire und effiziente Weise. Diese Technik ist zwar für den Menschen manchmal schwer zu verstehen, wird aber im Marketingbereich sehr häufig eingesetzt, um z. B. verschiedene Kunden in Gruppen einzuordnen. Ein Beispiel für einen Algorithmus, der sehr häufig beim Clustering verwendet wird, ist K-means.
Assoziation
Das Assoziationssystem sortiert und gruppiert Daten, die durch bestimmte Merkmale miteinander verbunden werden können. Das Ziel ist es also, Objekte zu finden, die miteinander verbunden sind, ohne dass es sich dabei um identische Objekte handelt. Wenn man dem Algorithmus beispielsweise viele Bilder von Katzen und Katzenzubehör zur Verfügung stellt, würde der unüberwachte Lernalgorithmus nicht alle Katzen zusammen gruppieren, sondern beispielsweise ein Wollknäuel mit einer Katze. Ein Beispiel für einen Algorithmus, der sehr häufig in der Assoziation verwendet wird, ist der A-priori-Algorithmus.
Unüberwachtes Lernen wird sehr oft im Bereich der Spracherkennung eingesetzt, z. B. bei der Verwendung von Siri oder Alexa.
So werden bei letzterem die stimmlichen Eigenheiten des Telefonbesitzers (Sprache, Stimmklang…) erlernt.
In ähnlicher Weise nutzen manche Handys sie, um Fotos automatisiert anzuordnen. Das Telefon ist in der Lage, die gleiche Person auf Fotos zu identifizieren oder ähnliche Orte zu finden, um sie nach diesen Kriterien zu ordnen.
Welche Unterschiede gibt es zum überwachten Lernen?
Obwohl beide Arten des Lernens in den Bereich der künstlichen Intelligenz fallen, wird beim überwachten Lernen eine Vorhersagefunktion anhand von gelabelten Beispielen erlernt.
Beim überwachten Lernen wird das Lernen der Maschine überwacht, indem ihr Beispiele für das, was sie tun soll, vorgelegt werden. Das Ziel des überwachten Lernens ist es also, Algorithmen zu schaffen, die Datensätze empfangen und eine statistische Analyse durchführen können, um ein Ergebnis vorherzusagen.
| Aspekt | Überwachtes Lernen | Unüberwachtes Lernen |
|---|---|---|
| Definition | Lernen mit gelabelten Daten | Lernen ohne gelabelte Daten |
| Ziel | Klassifizierung, Regression, Vorhersage | Entdeckung von Mustern, Strukturen, Gruppierung |
| Verfügbarkeit der Daten | Erfordert gelabelte Daten | Kann mit unlabeled Daten durchgeführt werden |
| Trainingsprozess | Modell lernt aus Eingabe-Ausgabe-Paaren | Modell sucht nach Mustern in den Daten |
| Anwendungsgebiete | Bilderkennung, Spracherkennung, Textklassifikation | Clustering, Dimensionsreduktion, Anomalieerkennung |
| Erforderliches Wissen | Kenntnis der Zielvariablen | Keine Kenntnis der Zielvariablen erforderlich |
| Herausforderungen | Begrenzte Verfügbarkeit von gelabelten Daten | Komplexität des Findens von Mustern |
| Beispiel-Algorithmen | Support Vector Machines (SVM), Entscheidungsbäume | K-means Clustering, Hauptkomponentenanalyse (PCA) |
Schließlich ist es wichtig zu betonen, dass es auch andere Arten des Lernens gibt, wie z. B. das halbüberwachte Lernen, das eine Mischung aus überwachtem und unüberwachtem Lernen darstellt.
Möchtest du alle Anwendungsbereiche des überwachten und nicht überwachten Lernens kennen lernen? Möchtest du lernen, sie zu nutzen? Entdecke unsere Schulungen!







