
The Kernel is a Machine Learning classification method. Find out everything you need to know about it, and how to train to become a Data Scientist or Data Analyst.
What is Kernel?
In Machine Learning, the Kernel method consists of using a linear classifier to solve a non-linear problem. This is achieved by transforming a linearly inseparable set of data into a linearly separable set, as in the example below, by passing it into a higher-dimensional space.
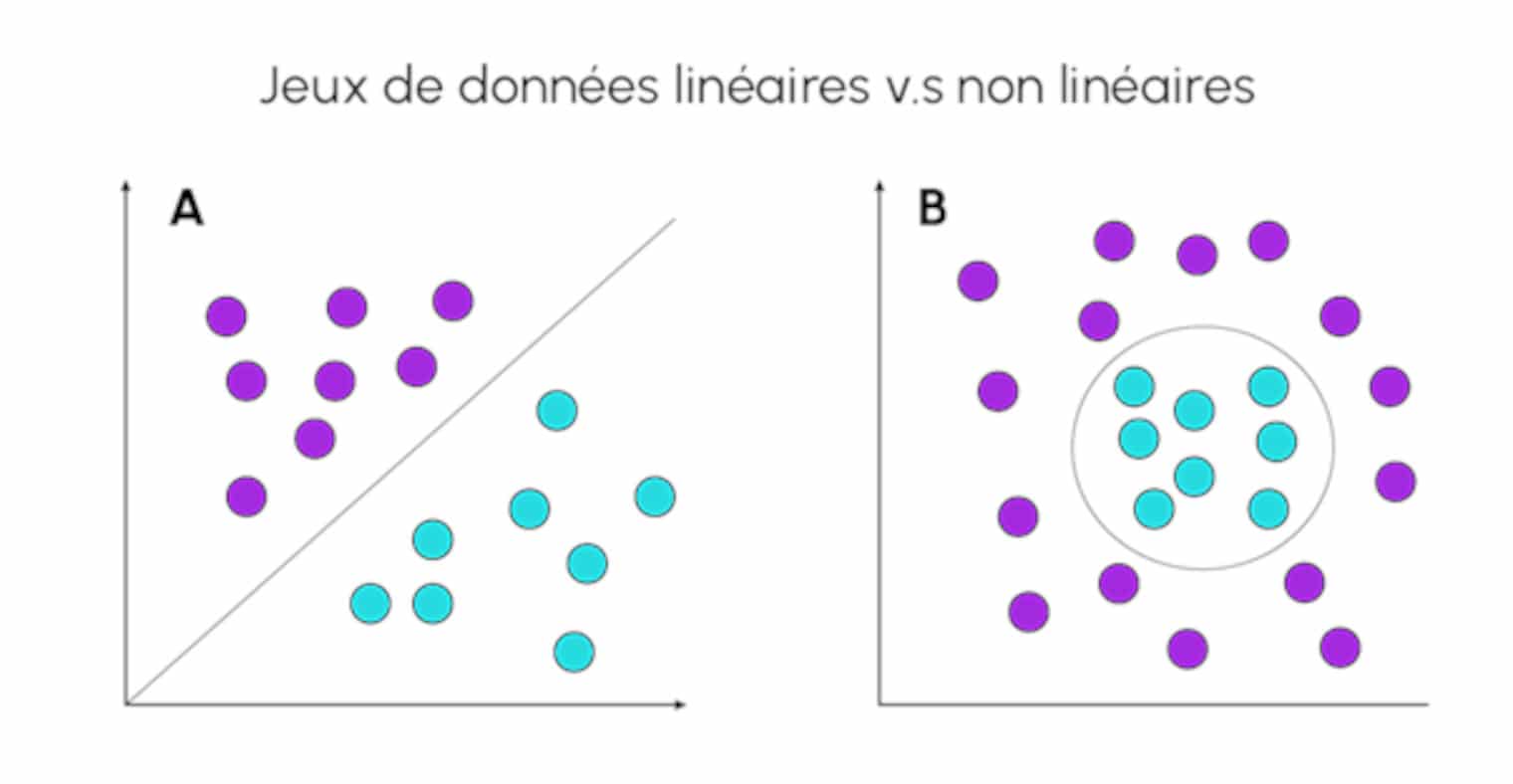
What is Kernel used for?
For example, kernel is very useful for separating two classes within a two-dimensional data set, where the data is not linearly separable.
Using a polynomial function would complicate the classification problem. It is therefore preferable to transform the data into a 3D space where the data becomes separable by a linear classifier.
It then becomes possible to transform the data from 2D to 3D, find a linear decision boundary by adapting the linear classifier in 3D space, and map the linear decision boundary back into 2D space to create a non-linear decision boundary in 2D.
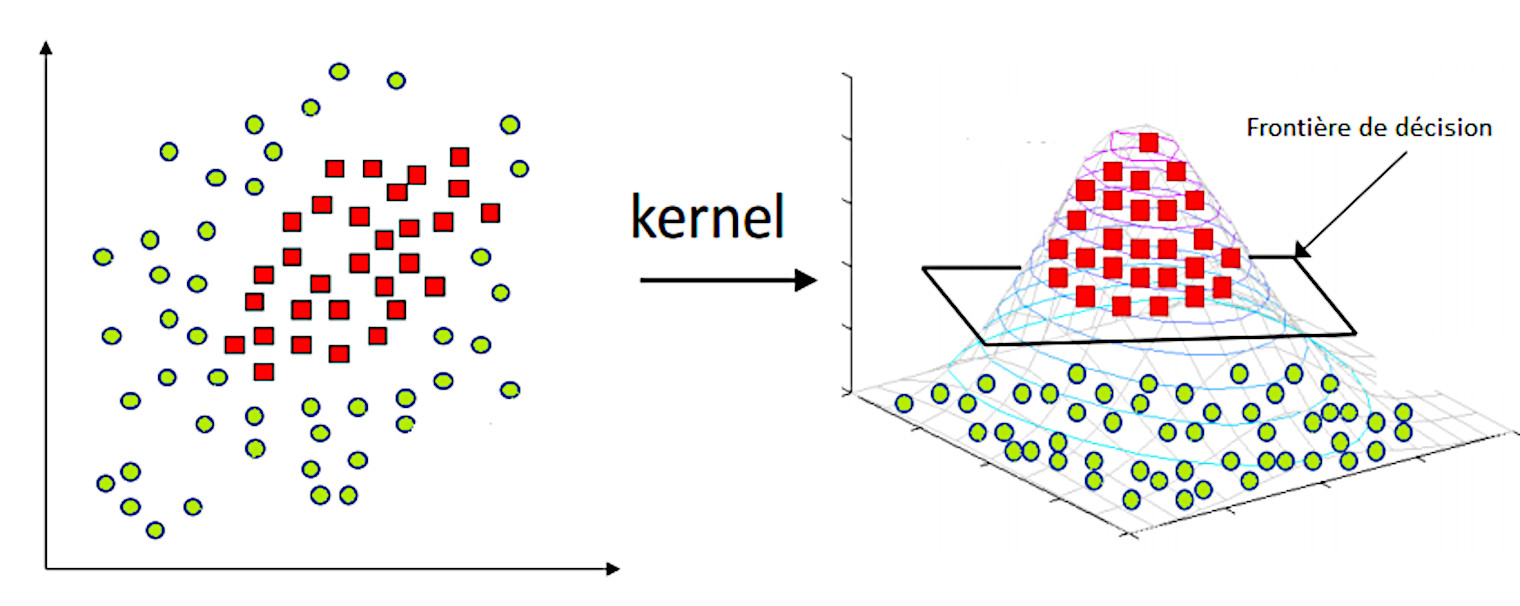
Where is the Kernel used?
There are various kernel-based algorithms in Machine Learning, such as the Regularised Radial Basis Function (Rdg RBFNN), the Support Vector Machine (SVM), the Kernel-Fisher discriminant analysis (KFD), or the Regularised Adaboost (Reg AB). Among these models, the most widely used approach is the Support Vector Machine (SVM).
A distinction is made between the classic linear SVM for linear classification and the non-linear SVM for which the Kernel is used to map patterns from the lowest to the highest dimensions.
This method makes it possible to process linearly inseparable data and create non-linear combinations of the original features into a higher-dimensional space via a mapping function where linear separation becomes possible. The most commonly used kernel for SVM is the RBF kernel or the Gaussian kernel.
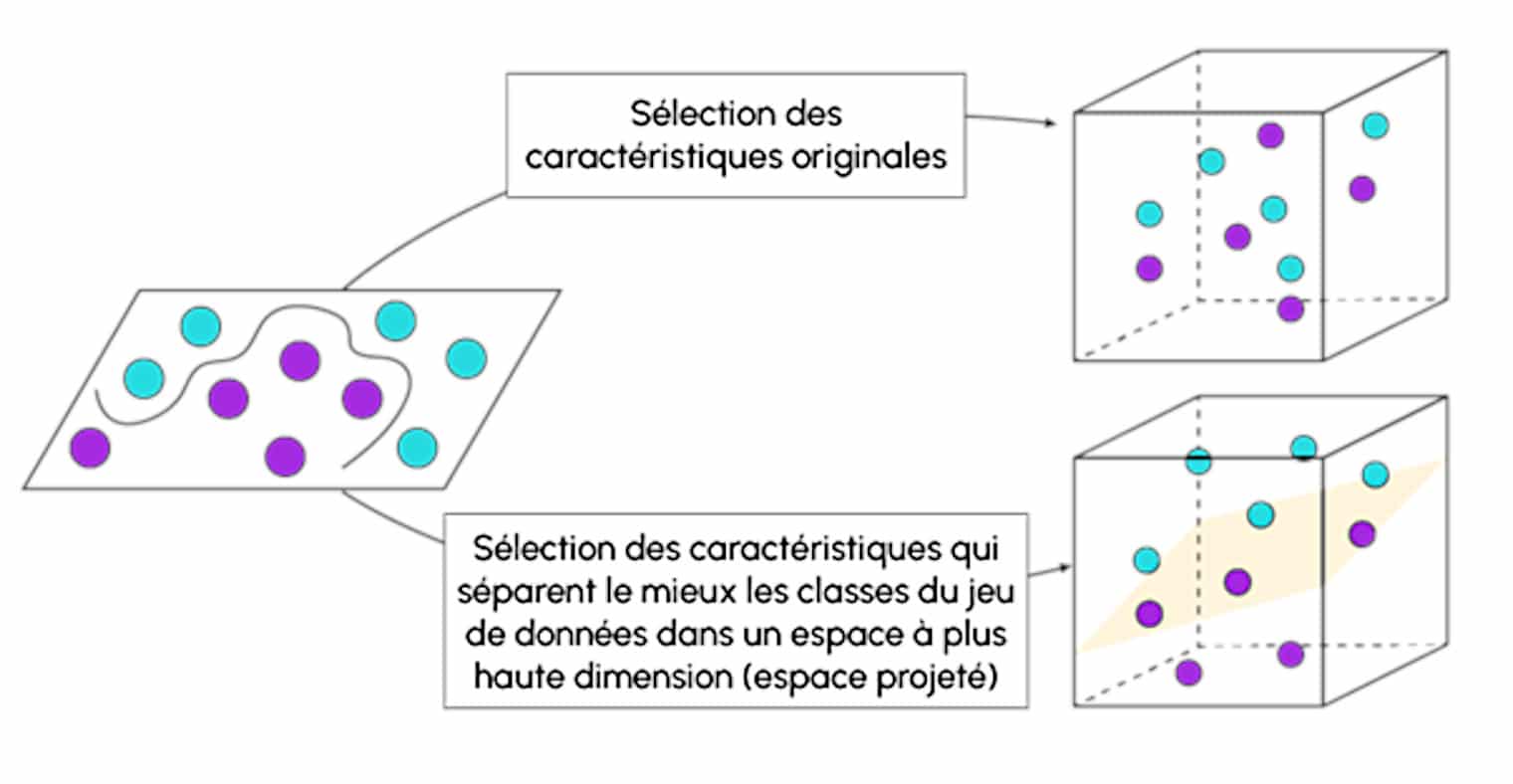
Can I learn how to use Kernel?
To learn about Machine Learning methods, you can choose one of the programmes powerede by DataScientest. Several of our courses include a module entirely dedicated to machine learning.
The Machine Learning module in the Data Analyst course covers clustering and regression methods using Scikit-learn. The other modules in this course cover programming, DataViz, databases and Business Intelligence.
By the end of the course, you will have all the skills required to perform the role of Data Analyst.
Our Data Scientist course includes two modules dedicated to Machine Learning. The first covers supervised Machine Learning, with regression methods and simple and advanced classification. The second focuses on unsupervised learning, including clustering and dimension reduction methods.
The subjects of Statsmodel, Text Mining and NetworkX are also studied in this course. The other modules in the programme are dedicated to programming, DataViz, Deep Learning and AI. This course enables you to acquire all the skills you need to become a Data Scientist.
To take things further, we also offer an expert Machine Learning Engineer course. This 7-month continuous training course or 16-month part-time course complements the Data Scientist course. It teaches you how to put Machine Learning models into production using engineering techniques, which is a highly sought-after skill in business.
All our courses are online, and comprise 85% asynchronous learning on our coached platform and 15% synchronous distance learning.
With the exception of the expert courses, our programmes can be completed via continuing education or intensive bootcamps.
As far as funding is concerned, all our courses are eligible for funding options. Don’t wait any longer and discover DataScientest’s training courses!








