
De nos jours, le potentiel du big data en entreprise n’est plus à prouver. Les recruteurs se disputent les profils les plus expérimentés et le besoin de formation se fait de plus en plus ressentir. Toutefois, lorsque l’on veut faire de la data science, le choix des outils est une étape très importante pour avoir une expérience optimale. Utiliser Python pour la data analysis est un très bon choix pour débuter, mais vous apprendrez qu’il est possible de le rendre plus adéquat avec par exemple Anaconda. Découvrez dans cet article l’intérêt d’utiliser Anaconda et comment l’installer sur votre ordinateur pour l’analyse de données.
Qu’est-ce que c’est Anaconda ?
Anaconda est un outil de distribution Python open source utilisé pour la gestion de packages et d’environnement de développement. Il sert à la réalisation de projets Python et de langages de programmation connexes, tel que R et Julia. Anaconda simplifie le processus de configuration et de gestion de différents packages et bibliothèques Python, ce qui en fait un outil indispensable pour les développeurs et les data scientist.
Son importance en data science est marquée par les packages qu’il propose comme : Numpy, Panda, Jupyter et Python. On peut aussi directement gérer ses environnements de développement et ses packages depuis son outil “conda”. Il est également multi-plateforme, ce qui permet de l’installer sur Linux, Windows ou MacOS.
Bibliothèque Python et package Anaconda quelles différences ?
Une bibliothèque Python est un ensemble de modules destiné à résoudre des problèmes spécifiques. Un package Anaconda est quant à lui un groupe de logiciels et de bibliothèques Python compilés pour simplifier l’installation et la gestion de bibliothèques Python et d’autres langages comme R.
Installer Anaconda pour Python
En installant Anaconda, vous installerez également Python et profiterez des packages scientifiques directement inclus, certains sont essentiels pour une bonne analyse des données.
Suivez ensuite les instructions selon votre système d’exploitation.
Installer Anaconda pour Windows ou Mac
- Téléchargez l’installateur macOS ou Windows en version Python 3 64 bits et lancez l’installation.
- Pour faciliter l’installation, n’ajoutez pas de chemin Anaconda au PATH de Windows.
- Une fois l’installation terminée, vous aurez accès aux différents outils d’Anaconda, les principaux étant Anaconda Navigator, une interface de gestion des environnements, et Anaconda Prompt, un terminal de gestion des environnements.
Installer Anaconda pour Linux
- Téléchargez la version d’installation Linux (x86).
- Entrez la commande suivante : bash ~/Downloads/Anaconda3-5.3.0-Linux-x86_64.h
- L’installateur devrait afficher : In order to continue the installation process, please review the license agreement.
- Faites apparaître les termes de la licence d’utilisation, scrollez jusqu’en bas et cliquez sur yes.
- Répondre yes à la question suivante : Do you wish the installer to prepend the Anaconda3 install location to PATH in your /home/ec2-user/.bashrc ? [yes|no]
- La commande précédente a ajouté au fichier “.bashrc” le dossier dans lequel se trouve Anaconda. Exécutez cette commande source .bashrcet lancez Anaconda directement en tapant anaconda dans votre console.
Vérifiez que tout est en place en lançant Anaconda Navigator et Anaconda Prompt.
Anaconda Navigator qu’est-ce que c’est ?
Anaconda Navigator est l’interface de navigation d’Anaconda, elle permet de lancer les différentes API disponibles et de gérer les différents packages et environnements du logiciel. Cette interface permet de naviguer simplement dans le logiciel, sans devoir connaître toutes les lignes de code de Conda. Dans Anaconda Navigator, vous pouvez retrouver ces différentes API :
- JupyterLab
- JupyterNotebook
- Spyder
- Pycharm
- VSCode
- Orane 3 APP
- RStudio
- Anaconda powerShell

Qu’est-ce qu’Anaconda Prompt ?
Anaconda Prompt est un terminal de commande pour accéder à Conda et gérer les environnements d’Anaconda. Grâce à lui, vous pouvez travailler sur différents environnements, utiliser des interfaces de développement et installer des packages.
Pour y accéder, il faut chercher Anaconda Prompt dans la barre de recherche d’Anaconda. Pour commencer à l’utiliser, voici une liste de commandes de bases :
- Pour lancer l’application d’Anaconda “Jupiter Notebook” : jupiter notebook
- Pour installer/désinstaller un module comme “Panda” il faut taper : Conda install/remove panda
- Si vous voulez lister les packages installés : Conda list
Pourquoi créer un environnement virtuel ?
Maintenant qu’Anaconda est installé, vous êtes fin prêt à coder en Python, enfin presque.
Pour fonctionner correctement, les programmes Python nécessitent parfois, une version spécifique d’un package. Cela arrive quand :
- Un programme a été implémenté sur une ancienne version d’un package mis à jour depuis .
- Que le programme utilise des packages compatibles uniquement avec celui-ci.
- Parce qu’un certain bug a été corrigé.
Ainsi il n’est pas toujours possible de travailler sur vos différents projets avec la même version de Python ou de vos packages. En effet, si un de vos projets dépend de la version 1.3 d’un package et qu’une autre application dépend de la version 2.0, ces dépendances entrent en conflit.
La solution est donc de créer un environnement virtuel, un environnement qui contient une certaine version de Python/R ainsi que différents packages. Il existe deux façons de le créer avec Anaconda : Anaconda Navigator ou Conda.
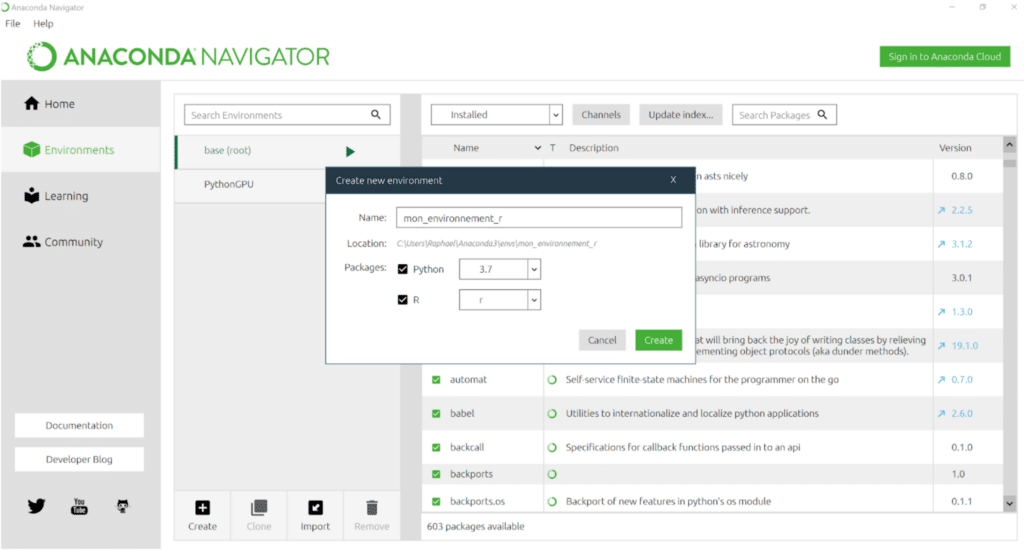
Créer un environnement virtuel avec Navigator :
Pour cela, rien de plus simple: dans l’onglet “Environments”, il suffit de créer un nouvel environnement virtuel en cliquant sur “Create”. Puis d’installer ou de mettre à jour les packages dont vous avez besoin, grâce au menu de gauche.
Créer un environnement virtuel avec Conda :
Avec Conda, il faut suivre une suite de commandes à remplir qui vous permettront de créer facilement votre premier environnement.
- Commencer par entrer cette commande : conda create -n mon_environement python=3.11
- À la suite de cette commande, Anaconda va créer un dossier avec un environnement complet dedans: l’interpréteur Python 3.9, les libs, etc. C’est une installation isolée.
- D’ailleurs, si vous utilisez cette commande sans préciser la version de python, Conda installera la version de python livrée par défaut avec Anaconda : conda create -n mon_environement
- pour activer votre environnement et travailler dessus, entrez : conda activate -n mon_environement
- Vous pouvez alors observer que votre prompt de ligne de commande va changer en (mon_environement) C:\dev $
Cela indique que vous allez travailler dans votre environnement virtuel.
Maintenant, toute commande exécutée dans ce terminal fera uniquement appel à la version de Python associée à l’environnement virtuel. Votre code aura aussi accès à chaque librairie exclusivement installée dans cet environnement.
Sur cette page vous trouverez d’autres commandes plus spécifiques sur la création d’environnement.
Une fois votre travail terminé, n’oubliez pas de fermer votre espace de travail avec : conda deactivate
Comment coder en Python ?
Pour commencer à coder en Python, il ne vous reste plus qu’à vous rendre sur la page d’accueil (Home) de l’application et de cliquer sur le bouton Launch de la fenêtre Jupyter Notebook.
Pour coder en R, il vous faudra suivre quelques étapes avant de commencer :
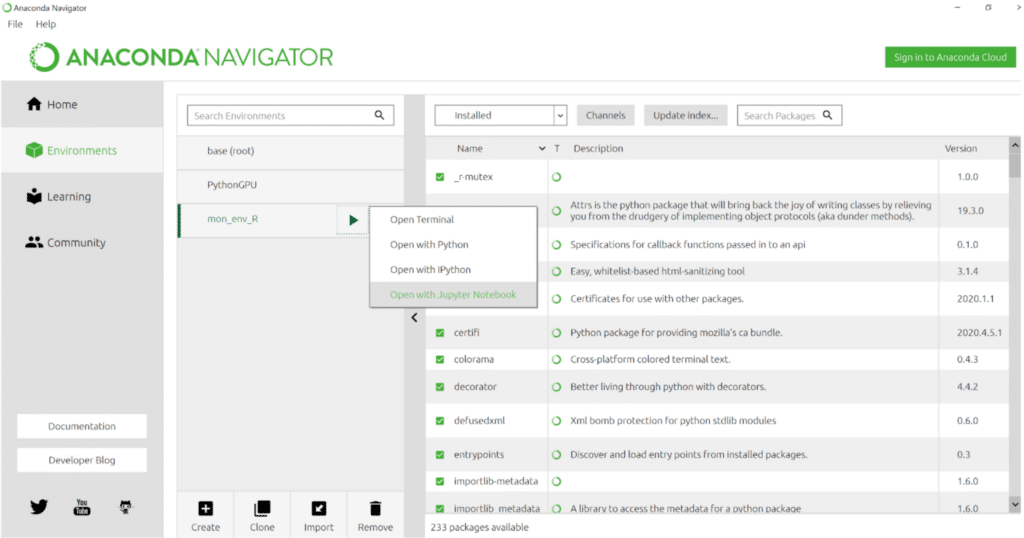
- Dans votre nouvel environnement virtuel, cochez les cases Python et R.
- Ouvrez l’environnement avec le package R en cliquant sur l’option “Open with Jupyter Notebook”
- Enfin, pour créer un nouveau Notebook en R, dans le menu de Jupyter Notebook, sélectionnez “New”, puis “R”. Ou sélectionnez “Python 3” pour coder en Python.
Vous êtes maintenant prêts à coder, après avoir installé avec succès Anaconda. Il ne vous reste plus qu’à choisir les meilleurs packages pour la réalisation de votre projet. Si vous hésitez à coder entre R et Python, l’un de nos data scientist a écrit un comparatif, juste ici.
Enfin, si cet article vous à plu et si vous souhaitez approfondir vos connaissances en programmation ou en data, n’hésitez pas à découvrir nos articles ou nos offres de formations sur DataScientest.









