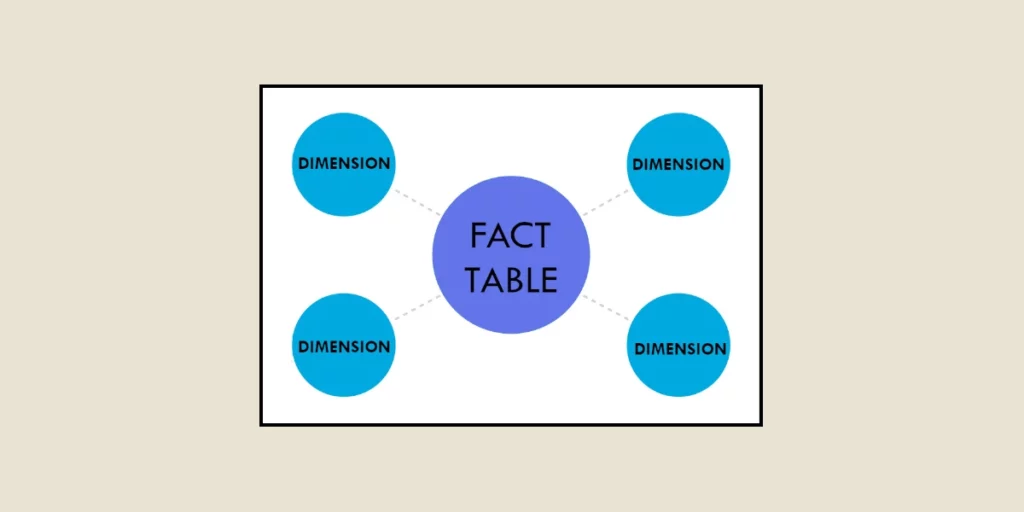
En data science et plus précisément dans les data warehouses, les termes dimension table (table de dimension) et facts table (table de faits) sont des concepts clés dans tout modèle de données, entre autres, à des fins d’analyse.

Rappel : qu'est-ce qu'un data warehouse ?
Un data warehouse est une plateforme centralisée de stockage de données, conçue pour faciliter l’analyse et la prise de décision. Il regroupe des données provenant de différentes sources et les organise de manière à permettre des analyses rapides et efficaces. Contrairement aux bases de données opérationnelles, un data warehouse est optimisé pour l’analyse des données historiques, offrant ainsi une meilleure vision des performances passées et présentes.
Qu'est-ce qu'une table de dimension ?
Une dimension est une table qui stocke des attributs qualitatifs d’un élément clé du processus de l’entreprise. Ces attributs sont utilisés pour décrire les faits numériques, qui sont à leur tour enregistrés dans les tables de faits.
Les dimensions permettent donc de fournir un contexte aux mesures quantitatives. Elles donnent des détails sur les événements, par exemple, qui, quand, où, ou à quel produit une vente a été réalisée.
Ces attributs peuvent inclure des éléments tels que le produit, la date, le client, ou même le lieu. Ces tables sont organisées de manière à rendre l’analyse des données plus intuitive, facilitant ainsi la compréhension des tables de faits, qui contiennent quant à elle les mesures quantitatives.
Les types de schémas utilisés
Il existe plusieurs modèles permettant d’organiser les tables de faits et de dimensions, notamment les modèles en étoile (star schema) et en flocon de neige (snowflake schema).
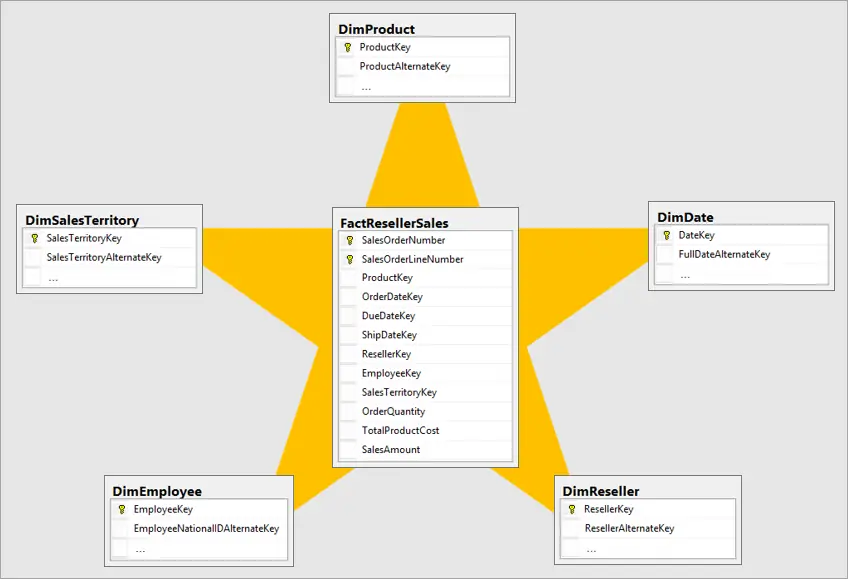
Star Schema
Ce type de schéma est le plus simple et le plus couramment utilisé en data warehousing. Ici, les tables de faits sont placées au centre et sont reliées aux tables de dimensions qui l’entourent, formant une structure en forme d’étoile. Cela facilite l’analyse des données car les relations entre tables sont claires et peu complexes. Il est généralement l’approche conseillée dans la mesure du possible.
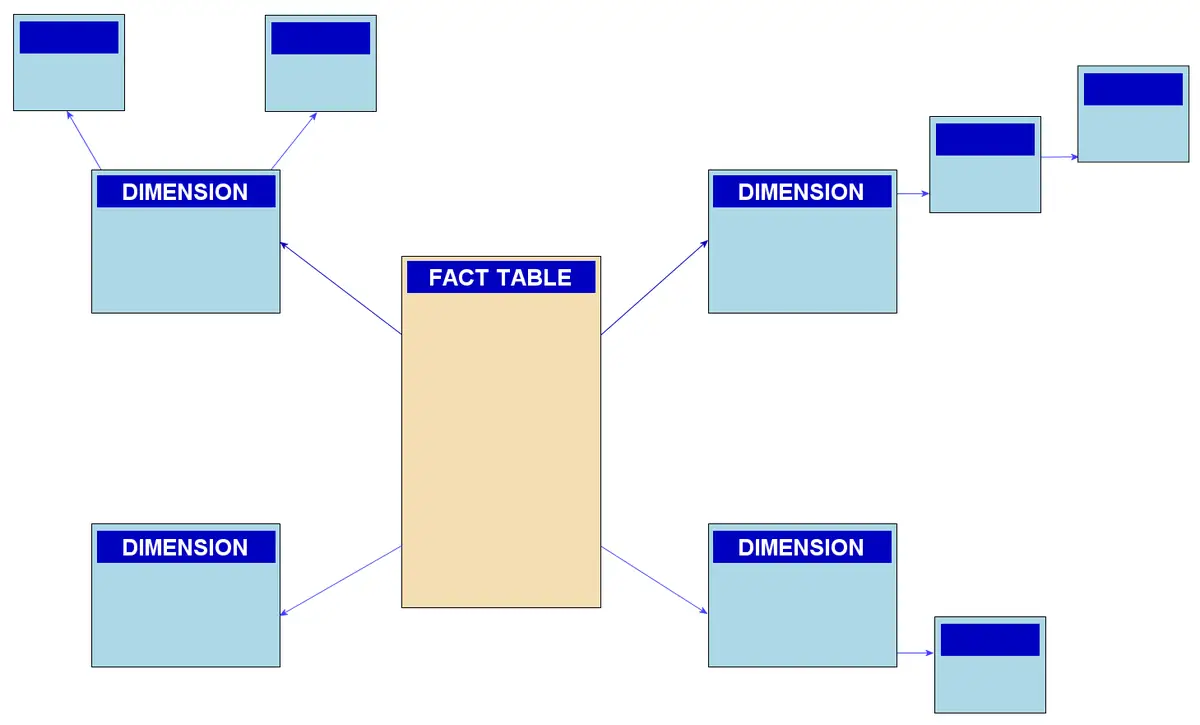
Snowflake Schema
Le schéma en flocon de neige est une extension du star schema, dans lequel les tables de dimensions sont normalisées à plusieurs niveaux. Cela signifie que les attributs d’une dimension sont à leur tour reliés à d’autres tables, formant une structure plus complexe qui ressemble à un flocon de neige. Cela permet de réduire la redondance des données, mais augmente la complexité des requêtes.
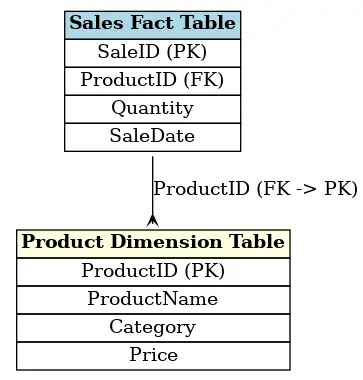
Primary Keys et Foreign Keys
Dans un modèle dimensionnel, les tables de dimensions disposent d’une clé primaire (primary key) qui identifie de manière unique chaque ligne. Cette primary key est à son tour utilisée dans la clé étrangère (foreign key) de la table de faits pour créer une relation entre les tables.
Par exemple, une table de faits des ventes (sales fact table) peut avoir une colonne « ProductID » qui est une foreign key pointant vers la primary key de la table de dimension produit. Ces relations permettent de croiser les données de différentes tables pour obtenir des analyses riches et détaillées.
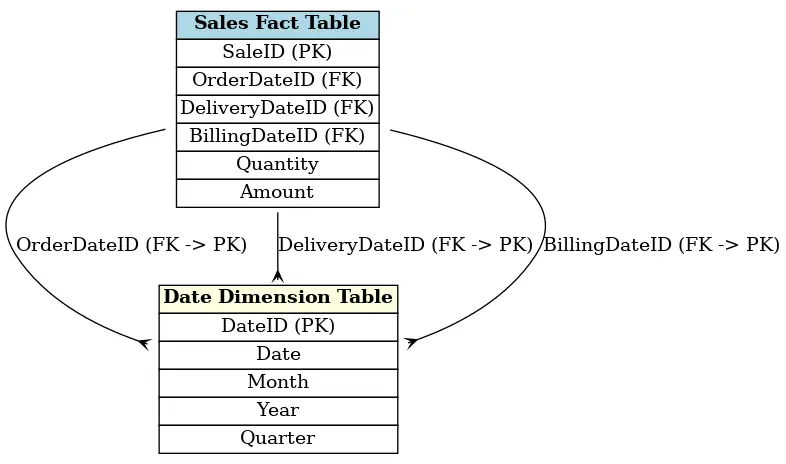
Role-Playing Dimensions
Certaines dimensions peuvent jouer différents rôles dans le modèle de données. Par exemple, une dimension date peut être utilisée pour représenter la date de commande, la date de livraison, ou la date de facturation. On parle alors de role-playing dimensions. Cela permet d’éviter la duplication des données en utilisant une seule dimension pour différents usages.
Dimensions à évolution lente (Slowly Changing Dimensions)
Les dimensions peuvent évoluer au fil du temps, et il est souvent nécessaire de suivre ces changements dans le data warehouse. Par exemple, un client peut changer d’adresse. Ces changements doivent être gérés pour être capables de comprendre à quel moment ces modifications ont eu lieu et comment elles ont affecté les faits.
Les slowly changing dimensions (SCD) permettent de gérer ce type de variation. Il existe plusieurs types, notamment :
- Type 1 : Le changement remplace simplement l’ancienne valeur.
- Type 2 : Une nouvelle ligne est ajoutée pour chaque modification, permettant de garder l’historique.
- Type 3 : Une nouvelle colonne est ajoutée pour garder la précédente valeur.
L'importance des dimensions dans l'analyse de données
Les dimensions permettent de transformer des valeurs numériques en informations exploitables. Elles aident à répondre à des questions stratégiques en contexte de business process, telles que :
- Quel produit se vend le mieux ?
- Qui sont nos meilleurs clients ?
- Quel moment de l’année est le plus rentable ?
En utilisant des dimensions pertinentes comme le produit, la date, ou le client, les analystes peuvent segmenter les données de vente ou de production et ainsi obtenir une vue plus précise des performances de l’entreprise. C’est cette association entre facts et dimensions qui rend possible une analyse de données éclairée.
Conclusion
Les dimensions sont extrêmement importantes dans un data warehouse et ne doivent pas être sous-estimées, car elle permettent de donner du sens aux données quantitatives contenues dans les tables de faits. En organisant les données avec des schémas en étoile ou en flocon de neige, en utilisant les clés primaires et étrangères, et en exploitant des role-playing dimensions, un data warehouse peut fournir une base solide pour une analyse des données approfondie.








