
Un modèle de Machine Learning est capable d’apprendre de façon autonome à partir d’un jeu de données, dans l’objectif de prédire des comportements sur un autre jeu de données. Pour cela, il trouve des relations sous-jacentes entre des variables explicatives indépendantes et une variable cible dans le dataset initial. Puis il utilise ces patterns pour prédire ou classifier des nouvelles données.
Comment définir la fonction train_test_split ?
Afin de vérifier l’efficacité d’un modèle de Machine Learning, le jeu de données initial est divisé en deux ensembles : un training set et un test set. Le training set est utilisé pour fit, c’est-à-dire pour entraîner, le modèle sur une partie des données. Le test set est utilisé pour évaluer les performances de ce modèle, sur l’autre partie des données. La fonction train_test_split de la bibliothèque ScikitLearn (sklearn) de Python permet de faire cette séparation en deux ensembles.
Avant toute chose, il faut penser à importer la fonction train_test_split à partir du package model_selection de sklearn en utilisant le code suivant :
Une fois importée, la fonction prend plusieurs arguments :
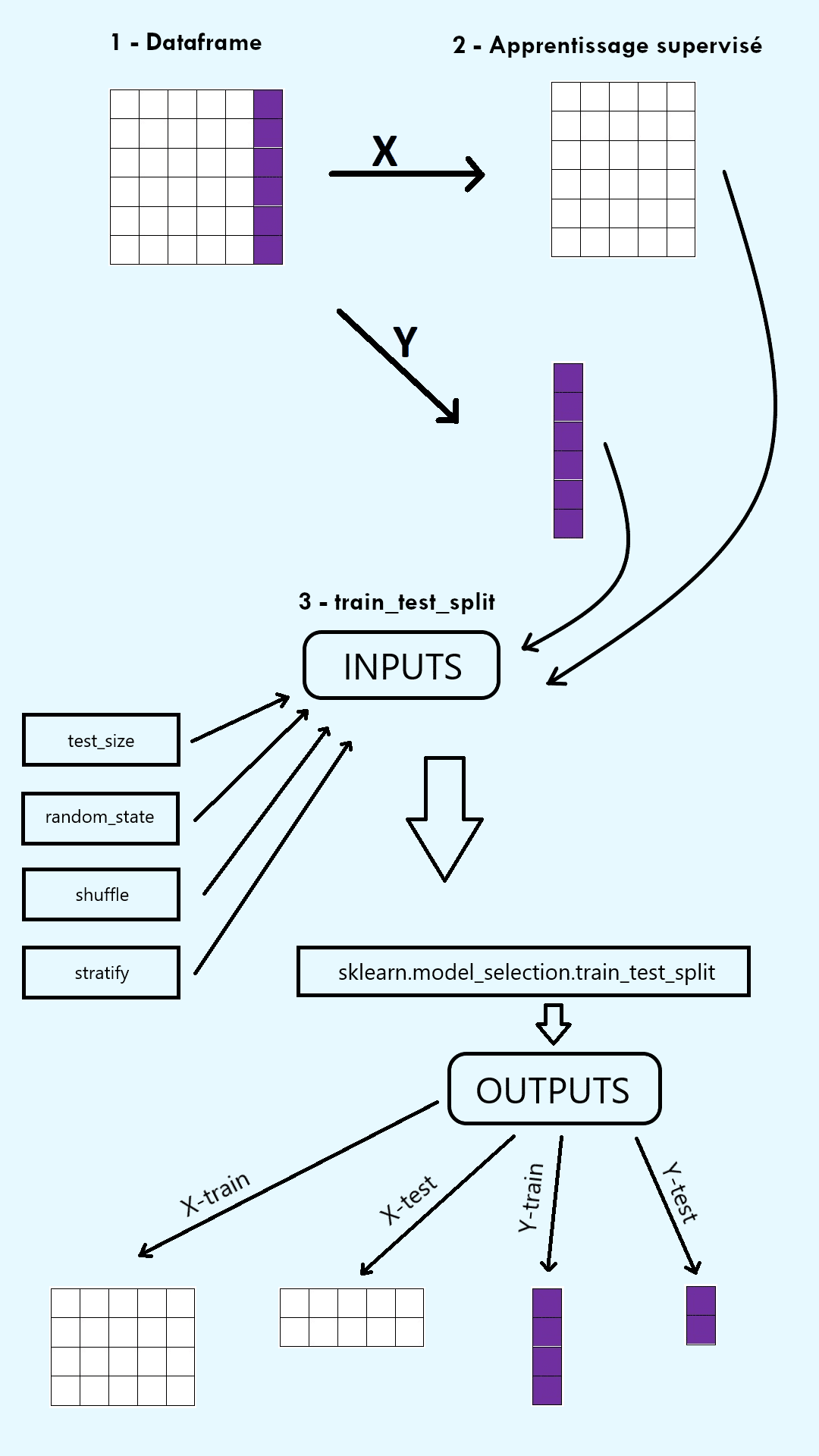
1) Des arrays extraits du jeu de données à diviser.
En apprentissage supervisé, ces arrays sont l’input array X, constitué des variables explicatives en colonnes, et l’output array y, constitué de la variable cible (c’est-à-dire les labels).
En apprentissage non-supervisé, l’unique array en argument est l’input array X, constitué des variables explicatives en colonnes.
Remarque : Faites attention aux dimensions ! X doit être un array à deux dimensions. y doit être un array à une dimension égale au nombre de lignes de X. Pour cela, n’hésitez pas à utiliser la fonction .reshape.
2) La taille du test set (test_size) et la taille du training set (train_size).
La taille de chaque ensemble est soit un nombre décimal compris entre 0 et 1 représentant une proportion du jeu de données, soit un nombre entier représentant un nombre d’exemples du jeu de données.
Remarque : Il est suffisant de définir un seul de ces arguments, le deuxième lui étant complémentaire.
3) Le random state (random_state).
Le random state est un nombre qui contrôle la façon dont le générateur pseudo-aléatoire divise les données.
Remarque : Choisir un nombre entier comme random state permet de séparer les données de la même manière à chaque appel de la fonction. Cela rend donc le code reproductible.
4) Le shuffle (shuffle).
Le shuffle est un booléen qui choisit si les données doivent être mélangées ou non avant d’être séparées. Dans le cas où elles ne sont pas mélangées, les données sont donc séparées en fonction de l’ordre où elles étaient initialement.
Remarque : La valeur par défaut est True.
5) Stratify (stratify).
Le paramètre Stratify choisit si les données sont séparées de façon à garder les mêmes proportions d’observations dans chaque classe dans les ensembles train et test que dans le dataset initial.
Remarques :
- Ce paramètre est particulièrement utile face à des données « unbalanced » avec des proportions très déséquilibrées entre les différentes classes.
- La valeur par défaut est None.
La fonction train_test_split renvoie un nombre d’outputs égal au double de son nombre d’inputs, sous forme d’array. Ainsi en apprentissage supervisé, elle renvoie quatre outputs : X_train, X_test, y_train et y_test. En apprentissage non-supervisé, elle renvoie deux outputs : X_train et X_test.
Comment évaluer les performances d’un modèle avec la fonction train_test_split ?
Une fois la fonction train_test_split définie, elle renvoie un ensemble train et un ensemble test. Ce splitting des données permet d’évaluer un modèle de Machine Learning sous deux angles différents.
Le modèle est entraîné sur l’ensemble train renvoyé par la fonction. Puis ses capacités prédictives sont évaluées sur l’ensemble test renvoyé par la fonction. Plusieurs métriques peuvent être utilisées pour cette évaluation. Dans le cas d’une régression linéaire, le coefficient de détermination, la RMSE et la MAE sont privilégiés. Dans le cas d’une classification, l’accuracy, la précision, le recall et le F1-score sont privilégiés. Ces scores sur l’ensemble test permettent donc de déterminer si le modèle est performant et à quel point il doit être amélioré avant de pouvoir prédire sur un nouveau dataset.
Les ensembles train et test renvoyés par la fonction train_test_split jouent aussi un rôle essentiel dans la détection d’overfitting ou d’underfitting. Pour rappel, l’overfitting (ou sur-apprentissage) décrit une situation où le modèle construit est trop complexe (avec trop de variables explicatives par exemple), tel qu’il apprend parfaitement les données d’entraînement mais n’arrive pas à se généraliser sur d’autres données.
À l’inverse, l’underfitting (ou sous-apprentissage) décrit une situation où le modèle est trop simple ou mal choisi (choix d’une régression linéaire sur des données ne respectant pas ses hypothèses par exemple), tel qu’il apprend mal. Ces deux problèmes peuvent être corrigés par différentes techniques mais ils doivent d’abord être repérés, ce qui est possible grâce à la fonction train_test_split. En effet, nous pouvons comparer les performances du modèle sur l’ensemble train et sur l’ensemble test créés par la fonction. Si les performances sont bonnes sur l’ensemble train mais mauvaises sur l’ensemble test, nous faisons sûrement face à de l’overfitting. Si les performances sont aussi mauvaises sur l’ensemble train que sur l’ensemble test, nous faisons sûrement face à de l’underfitting. Les deux ensembles renvoyés par la fonction sont donc essentiels dans la détection de ces problèmes récurrents en Machine Learning.
Comment résoudre un problème de Machine Learning complet en utilisant la fonction train_test_split ?
Maintenant que nous avons compris l’utilisation et les fonctionnalités de la fonction train_test_split, mettons la en pratique à travers un réel problème de Machine Learning.
Étape 1 : Compréhension du problème
Nous choisissons de résoudre un problème d’apprentissage supervisé tel que les labels attendus sont connus. Plus précisément nous nous concentrons sur une classification binaire. L’objectif est de prédire si un individu est atteint ou non d’un cancer du sein, à partir de ses caractéristiques corporelles.
Étape 2 : Récupération des données
Nous utilisons le dataset « breast_cancer » inclus dans la librairie Sklearn.
Grâce aux lignes de code suivantes, nous récupérons les variables explicatives (features) et la variable cible (target) :
Nous obtenons que la variable cible à prédire prend deux valeurs (« malignant » et « benign ») et que le problème est bien une classification binaire.
Étape 3 : Création de X et de y
Nous créons l’input array X à deux dimensions et l’output array y à une dimension. Pour ce dataset, l’encodage binaire de la variable cible est effectué par sklearn et peut-être directement récupéré.
Nous vérifions que les dimensions de X et de y sont bien correspondantes : y a le même nombre de lignes que X.
Étape 4 : Création des ensembles train et test
Nous divisons les données en un ensemble train et un ensemble test.
Puisque nous fournissons deux arrays X et y à la fonction train_test_split, elle renvoie quatre éléments. Nous choisissons un ensemble test constitué de 10% des données. Nous choisissons un nombre de type “int” comme random state pour assurer la reproductibilité du code. Nous n’utilisons pas les derniers paramètres de la fonction, qui ne sont pas nécessaires pour un problème aussi simple.
Étape 5 : Modèle de classification
Pour résoudre la tâche de classification nous construisons un modèle des k-plus proches voisins. Nous entraînons le modèle sur le train set avec la méthode .fit(). Puis nous testons les performances du modèle sur le test set avec la méthode .predict(). Nous obtenons ainsi les classes prédites pour les observations de l’ensemble test.
Étape 6 : Évaluation du modèle
Nous choisissons comme métrique l’accuracy. L’accuracy représente le nombre de bonnes prédictions sur le nombre total de prédictions. Nous la calculons sur l’ensemble train et sur l’ensemble test grâce à la méthode .score(), qui compare les vraies classes du dataset aux classes prédites par le classifieur clf.
Nous obtenons une accuracy de 0.95 sur l’ensemble train et de 0.93 sur l’ensemble test. Ainsi le modèle a de bonnes performances de classification.
De plus l’accuracy sur l’ensemble test est très légèrement inférieure à celle sur l’ensemble train. Cela signifie que le modèle se généralise bien à de nouvelles données. Nous ne faisons donc pas face à un problème d’overfitting.
Ainsi la fonction train_test_split est facilement utilisable et très efficace pour résoudre un problème complet de Machine Learning.
Existe-t-il des limites à la fonction train_test_split ?
Malgré tout, la fonction train_test_split comporte une principale limite liée à son paramètre random_state. En effet, lorsque la valeur donnée au random state est un nombre entier, les données sont séparées grâce un générateur pseudo-aléatoire initialisé avec ce nombre entier, appelé seed ou graine aléatoire. La séparation effectuée est reproductible en gardant le même seed. Cependant, il a été montré que le choix du seed a une influence sur les performances du modèle de Machine Learning associé : des seeds différents peuvent créer des ensembles différents et des scores variables.
Une solution à ce problème consiste à utiliser la fonction train_test_split plusieurs fois avec des valeurs différentes pour le random_state. Nous pouvons ensuite calculer la moyenne des scores obtenus.
Ainsi la fonction train_test_split de la librairie Python sklearn est essentielle pour mener un projet de Data Science et évaluer un modèle de Machine Learning quand elle est bien utilisée ! !









